- The paper introduces MME-Unify, a benchmark that systematically evaluates unified multimodal models across understanding, generation, and integrated tasks.
- It standardizes tasks from 12 datasets into a multiple-choice format with harmonized metrics, enabling fair and direct model comparisons.
- Experimental results reveal notable trade-offs in current U-MLLMs, highlighting challenges in cross-modal reasoning and multi-step generation.
MME-Unify: Comprehensive Evaluation of Unified Multimodal LLMs
Introduction and Motivation
The development of Unified Multimodal LLMs (U-MLLMs) has been accelerated by their capacity to process, reason about, and generate content across both textual and visual domains. Despite rapid advances, prior evaluation efforts for these models remain fragmented—typically assessing either comprehension or generation, often via inconsistent metrics, and lacking rigorous, standardized benchmarks for tasks that intertwine modalities (so-called "unify" tasks).
The work "MME-Unify: A Comprehensive Benchmark for Unified Multimodal Understanding and Generation Models" (2504.03641) directly addresses these deficiencies. The authors introduce the MME-Unify (MME-U) benchmark, which offers a systematic, unified, and extensible suite for assessing U-MLLMs on multimodal understanding, generation, and highly integrated unify tasks, thereby setting a new baseline for comparative analysis in the community.
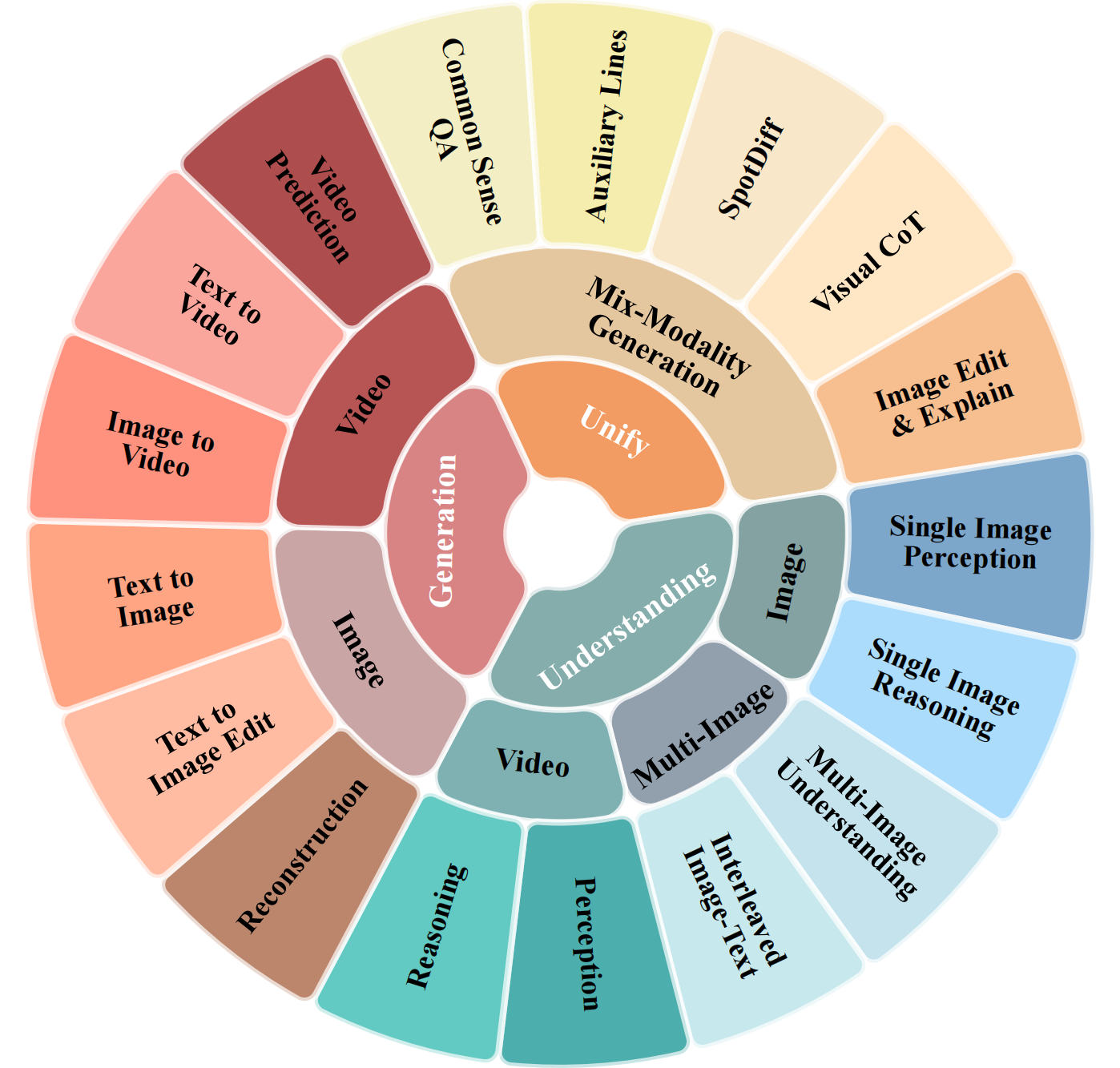
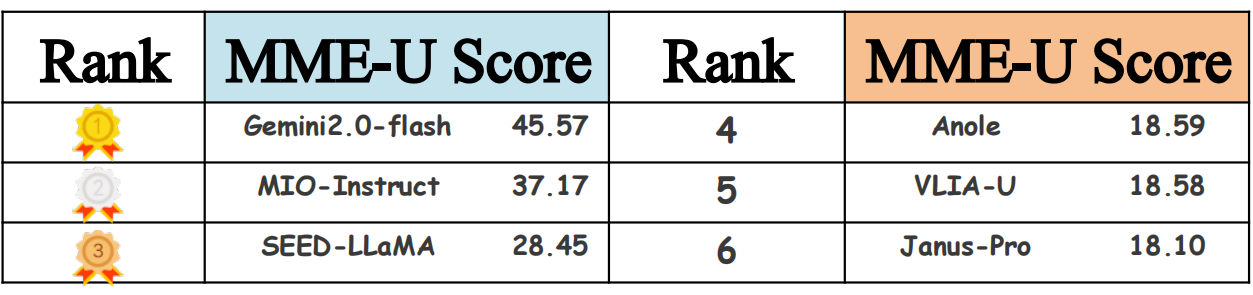
Figure 1: MME-U tasks, depicting the landscape of understanding, generation, and unify domains in the benchmark.
Benchmark Structure and Evaluation Paradigm
MME-U meticulously curates tasks from 12 major datasets, comprising 10 traditional tasks (with 30 subtasks) and introducing five novel unify tasks specifically crafted to evaluate mixed-modality generation and reasoning. All subtasks—across understanding, generation, and unify categories—are standardized into a multiple-choice format where feasible, greatly improving result comparability. The benchmark employs harmonized evaluation metrics: accuracy for understanding, normalized generation metrics (CLIP, FID, FVD, LPIPS) for generation, and combined cross-modal accuracy for unify tasks.

Figure 2: Structure of MME-Unify: Three domains (understanding, generation, unify) with task pipelines involving image and text input, option selection, and both CLIP-based and logic-based checks.
Understanding
Understanding tasks are segmented into single-image, multi-image interleaved, and video-based perception/reasoning, sampling from established datasets with an emphasis on real-world complexity and a diverse set of image/text or video/text scenarios. All outputs are recast as multiple-choice QA pairs to ensure robust, unbiased scoring.

Figure 3: Representative samples from understanding tasks across image-text, image-image and video-text reasoning.
Generation
Generation subtasks target the spectrum from text-guided image creation/editing (TIG/TIE), fine-grained image reconstruction (FIR), and conditional image-to-video, to text-to-video and video prediction. Attribute normalization and prompt standardization address the inherent heterogeneity of source datasets and task formats.
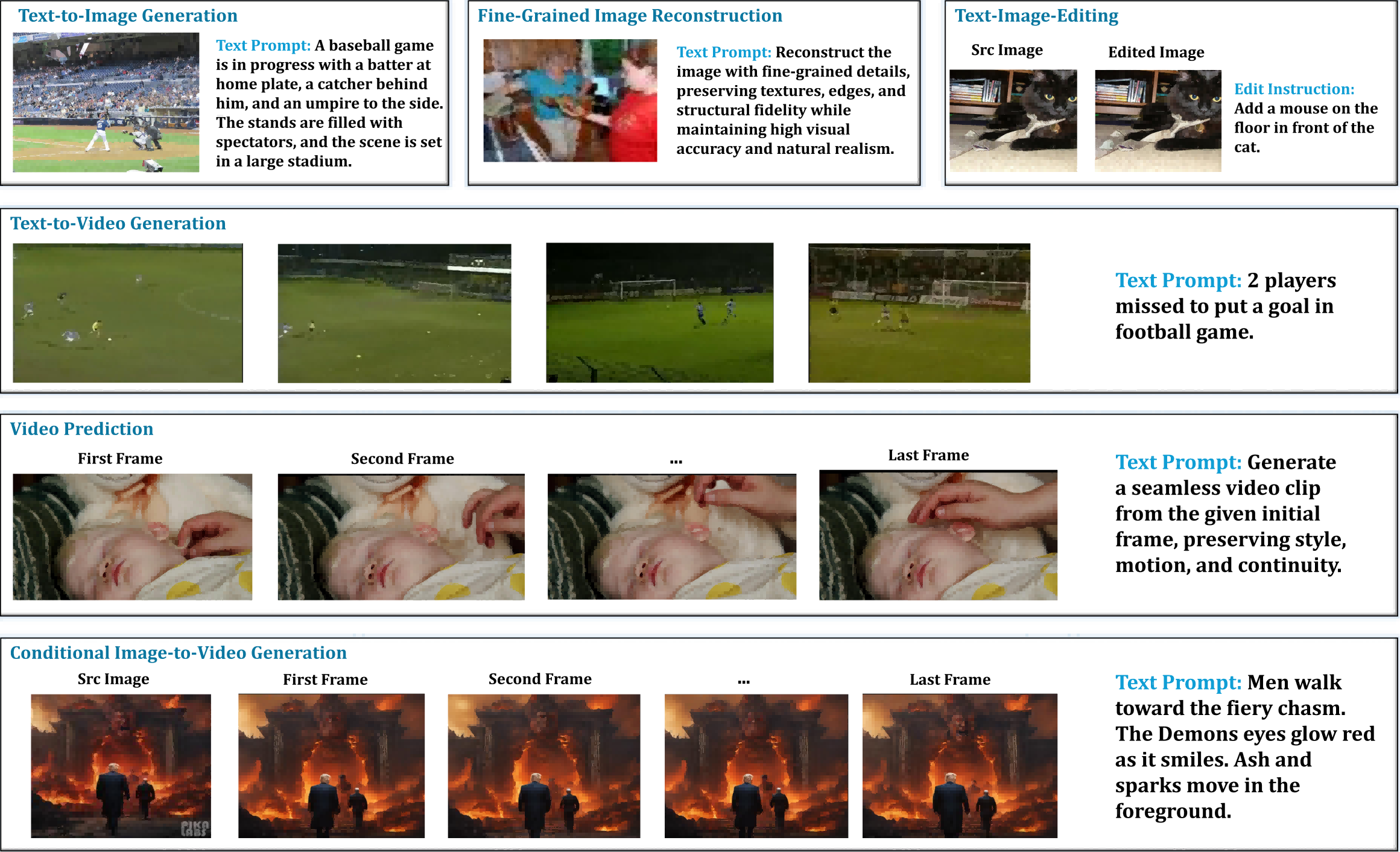
Figure 4: Representative samples from generative tasks covering image and video modalities in text/image-to-image or text/image-to-video settings.
Unify Capability
The benchmark's most innovative contribution is its suite of unify tasks, specifically engineered to require synergistic reasoning and generation across modalities:
- Common Sense Question Answering (CSQ): Link riddles to both entity selection and corresponding image generation.
- Image Editing and Explaining (IEE): Parse and execute multi-step visual modifications with natural language rationale.
- SpotDiff (SD): Localize and generate difference maps between paired images.
- Auxiliary Lines (AL): Reason through geometry problems visually and textually, producing diagrams with auxiliary constructions.
- Visual Chain-of-Thought (VCoT): Employ step-wise visual and textual reasoning for spatial navigation or puzzle tasks.
These tasks are explicitly mapped to multiple-choice settings for both generated text and images, with objective CLIP-based and logic-based correctness criteria.
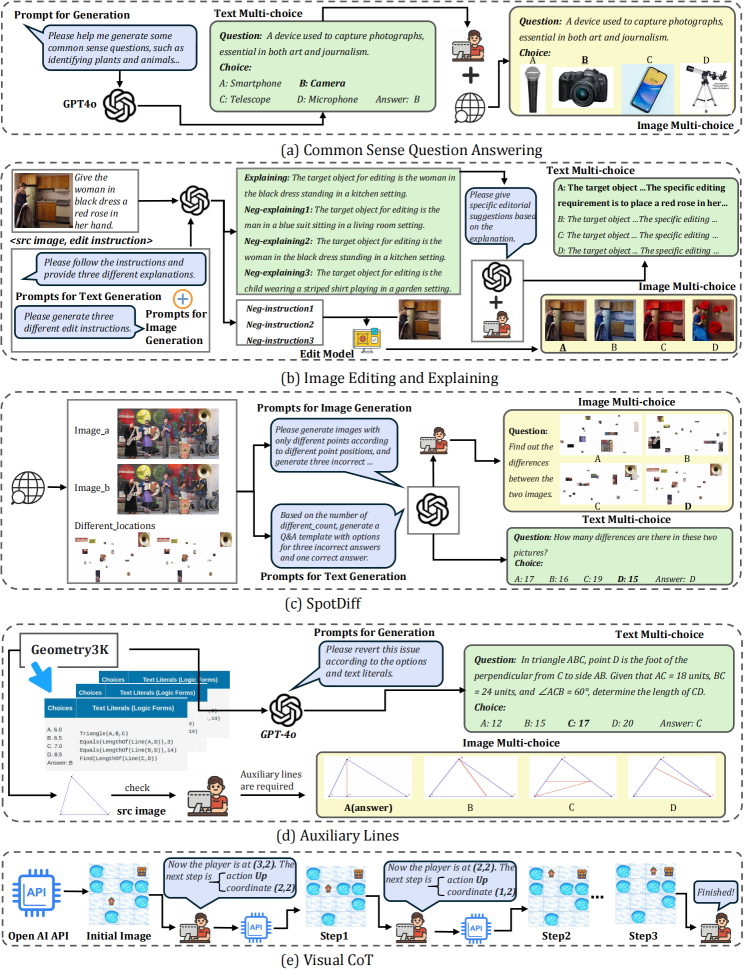
Figure 5: Construction process for all five unify tasks, capturing data collection and option generation pipelines.
Experimental Results and Analysis
Model Coverage and Metrics
The authors evaluate 22 models, including generalist U-MLLMs (e.g., Gemini2.0-flash-exp, Emu3), specialized comprehension/generation models (Claude-3.5 Sonnet, DALL-E-3), and several open-source interleaved modality generators (Janus-Pro, MiniGPT-5). Each model is assessed across all three axes: understanding, generation, and unify (MME-U) score.
Quantitative Findings
- No Dominant Generalist: Closed-source Gemini2.0-flash-exp achieves the top unified score (45.57), markedly outperforming all open-source approaches. No model excels simultaneously in understanding, generation, and unify tasks; trade-offs are pronounced, particularly for open-source systems.
- Specialization vs. Generalization:
- Unify Tasks Remain Unsolved: Across unify tasks, even the most capable open-source U-MLLMs rarely exceed 60% accuracy on integrated pipelines, and multi-step reasoning tasks (Visual CoT) consistently expose compounding error cascades, with no model reliably completing extended visual logic chains.
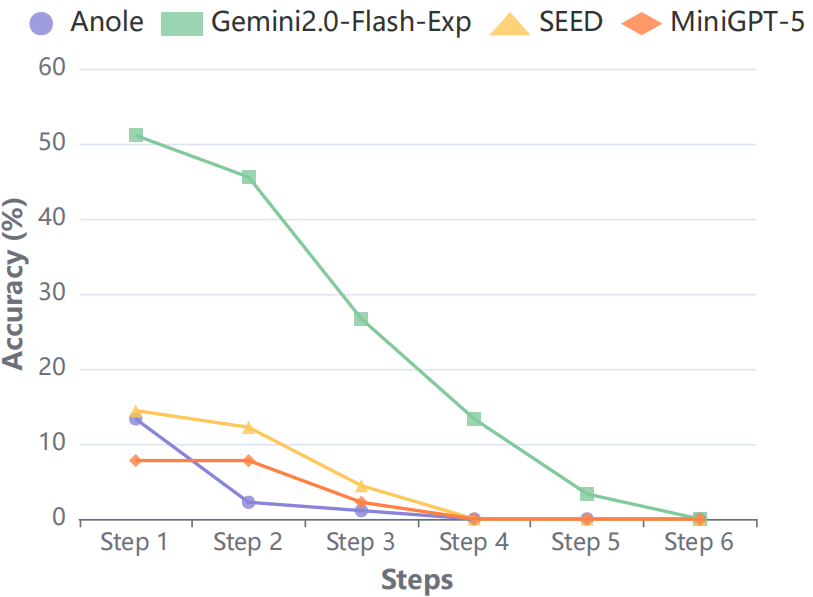
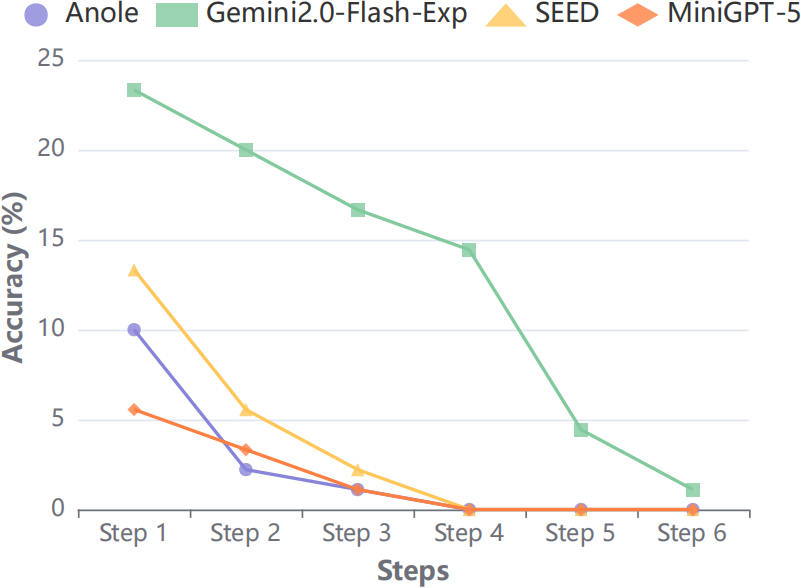
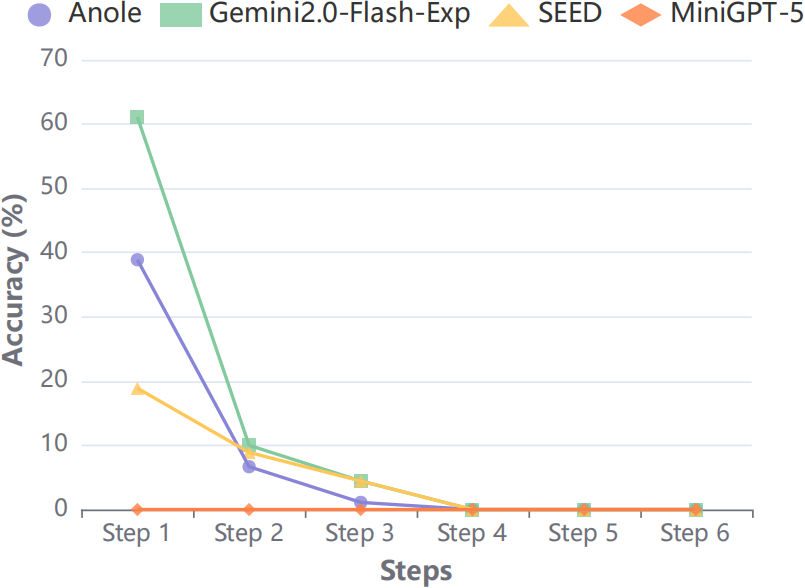
Figure 7: Action accuracy in Visual CoT tasks sharply declines with increasing step complexity.












Figure 8: Ground truth for Visual CoT navigation, exemplifying the complexity of sequential reasoning that current models fail to master.
- Instruction Following Remains Fragile: Detailed error analysis reveals brittle instruction adherence in all U-MLLMs: outputs diverge from prompt styles or instructed edits in both image and video generation, especially when combining semantic transforms (e.g., style transfer, auxiliary line addition) with logical reasoning.

Figure 9: Image editing and explaining outputs by various models, showing substantial style and semantic gaps relative to ground truth edits.
Qualitative Analysis
Results highlight that open-source U-MLLMs (VILA-U, Janus-Pro, Anole, GILL, SEED) struggle with multi-stage compositionality, failing to cohere textual and visual outputs. Hybrid models (e.g., MIO-Instruct) occasionally achieve high comprehension or generation scores, but not in an integrated fashion. Representative generation tasks illustrate semantic omissions and hallucinations: factual details are often misrepresented, and spatial/semantic alignment with prompt text is poor.

Figure 10: Common sense QA unify task outputs reveal frequent mismatches between generated images and required entities.
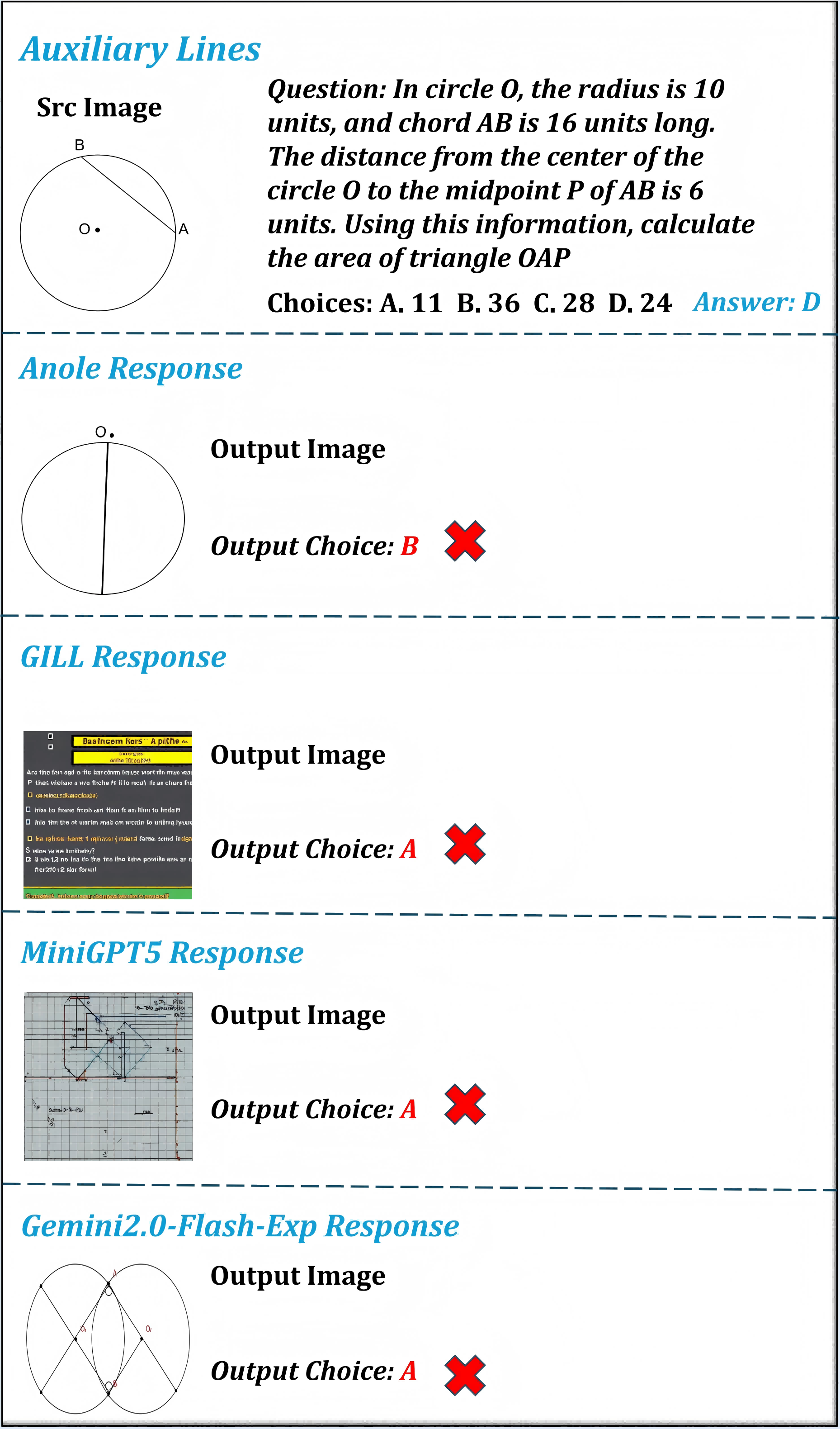
Figure 11: Auxiliary line generation: models typically miss auxiliary construction objectives or produce irrelevant visuals, constraining downstream—e.g., geometric—answers.
Implications and Future Trajectory
The introduction of MME-Unify reshapes the evaluation paradigm for U-MLLMs by providing a rigorous, multi-faceted benchmark that exposes the fragility of current approaches in integrating comprehension and generation. The stark performance differences between dedicated and unified models, especially on complex unify tasks, suggest that monolithic training paradigms or naive fusion strategies are fundamentally insufficient. Moreover, the inability to maintain cross-modal and temporal coherence throughout sequential chains (as seen in Visual CoT) points to deeper architectural and algorithmic challenges.
Theoretical Impact
These results press for new methods that jointly optimize for understanding and generation, with an emphasis on iterative, causally-linked cross-modal reasoning. The dichotomy between generation-driven and understanding-driven architectures must be reconciled, potentially through hybrid frameworks or curriculum-based training that balance both objectives from the ground up.
Practical Impact
For real-world applications—e.g., interactive visual assistants, robotic perception-actuation, multi-modal dialogue—the findings illuminate current limits. The low fidelity of unified reasoning and generation implies that current U-MLLMs are not yet suitable for deployment in high-stakes mixed-modality tasks, despite isolated successes in one modality.
Future Directions
- Explicit Multimodal Reasoning Modules: Architectures integrating explicit visual grounding, step-wise memory, and hierarchical control for modal outputs.
- Curriculum and Multi-task Learning: Progressive training on unify tasks that incrementally combine comprehension and generation, with feedback-driven alignment.
- Benchmark Extensions: Incorporation of even more diverse unify scenarios, especially with longer action chains, real-world context, and adversarially constructed edge cases.
Conclusion
MME-Unify provides a comprehensive, technically rigorous, and extensible benchmark for evaluating U-MLLM capabilities in understanding, generation, and especially mixed-modality reasoning and synthesis. The empirical findings demonstrate that, while U-MLLMs have made progress in isolated tasks, significant limitations persist in truly integrative tasks that require both modalities in harmony. As such, MME-Unify establishes a clear research agenda for future work on holistic multimodal AI systems, with pressing open challenges in unified representation, cross-modal instruction following, and causal consistency in sequential mixed-modality pipelines.
