- The paper demonstrates that Transformer models implicitly learn continuous-time functions, challenging the traditional discrete approach to language modeling.
- It details a continuous causal attention mechanism where token duration and interpolated embeddings drive smooth, semantically rich transitions in model outputs.
- Experimental results validate the continuous paradigm across state-of-the-art models, suggesting new avenues for model initialization and data augmentation techniques.
LLMs Are Implicitly Continuous
The paper "LLMs Are Implicitly Continuous" proposes a novel perspective on the nature of language understanding in Transformer-based models, challenging traditional discrete interpretations of language modeling. The authors suggest that these models implicitly learn continuous-time functions over continuous input spaces, which leads to new insights into how LLMs process and predict language.
Time Continuity
Traditional LLMs treat language as a sequence of discrete symbols. However, the authors propose that within the Transformer architecture, language can be viewed as a piecewise-constant function over continuous time intervals. This view implies that language tokens have durations, and the model's understanding can smoothly vary depending on the duration allocated to each segment of input text.
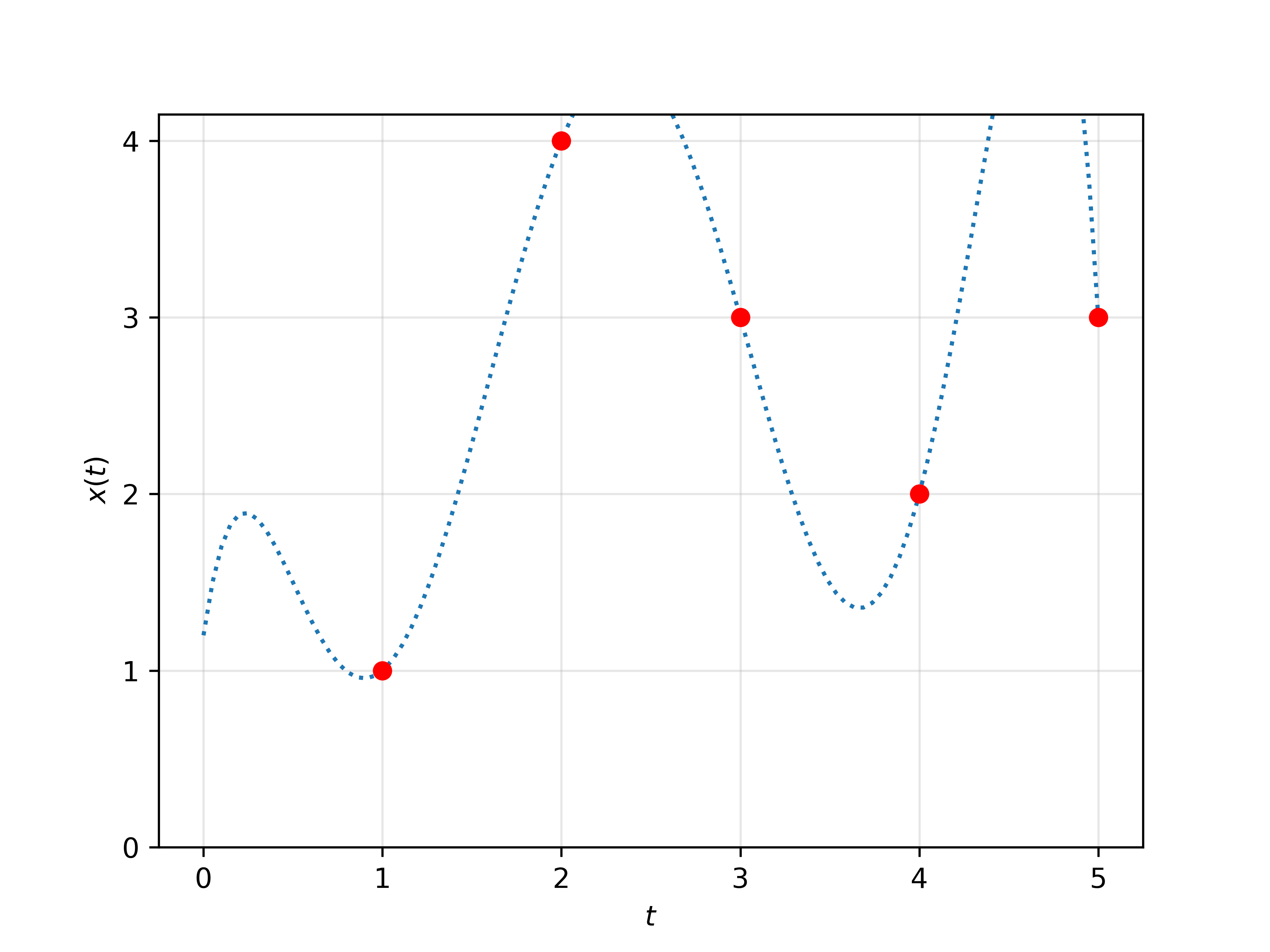
Figure 1: Graphical representation of the time continuity of language, illustrating tokens sampled at integer timesteps versus a spatially continuous extension.
The authors provide a detailed derivation of how to extend the traditional causal attention mechanism used in Transformers to handle such continuous inputs. This Continuous Causal Transformer (CCT) does not require changes to the model weights, making it applicable to existing pretrained models. The continuous approach also reveals that the model's output depends critically on the "duration" of each token, suggesting an innate semantic dimension not previously accounted for in discrete models.
Space Continuity
Beyond time, the paper explores space continuity, where the embeddings are not strictly tied to discrete tokens but can represent interpolations between them. This allows investigation into how models treat interpolated embeddings of semantically similar tokens, indicating that models inherently derive meaningful semantic concepts from such embeddings.
Experimental Results
The authors conducted experiments to empirically validate their continuous model extension across several state-of-the-art models, including Llama2, Llama3, Phi3, and others. Some key experiments include:
Single-Token and Multi-Token Time Continuity
Experiments revealed that models respond to changes in token durations in unexpected yet linguistically meaningful ways. For instance, altering the duration of tokens in a repetitive sentence led the model to predict different numbers of tokens, suggesting a non-discrete concept of token "scale" or "importance" based in part on duration.
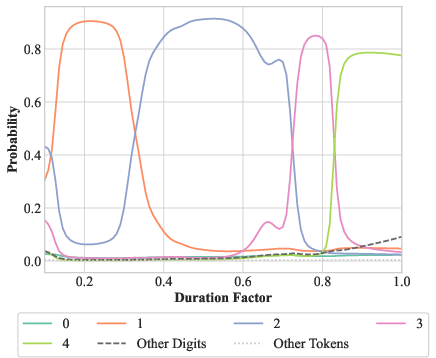
Figure 2: Output transitions observed when altering token durations in word counting tasks, illustrating the model's continuous reasoning.
Semantic Effects of Duration and Spatial Continuity
When continuous embeddings (interpolations between two tokens) were input, models demonstrated smooth transitions in their predictions, consistent with the interpolated meanings of the embeddings rather than abrupt switches characteristic of discrete interpretations.
Implications and Future Work
The findings have significant implications for both the theoretical understanding of LLMs and practical applications:
- Understanding LLMs: The shift towards continuous representation emphasizes that LLMs operate under different paradigms than human language processing, potentially explaining their unique failure modes and successes.
- Improving Efficiency: The implicit continuity suggests new initialization strategies for LLMs or more effective data augmentation techniques that leverage continuous semantics.
- Broader Linguistic Theories: A richer understanding of how LLMs process semantic continuity can offer innovative insights into linguistic theory, possibly integrating cognitive models with AI language processing approaches.
Conclusion
In summarizing the work, the paper provocatively asserts that the continuous nature of LLMs offers a foundational shift in how we conceptualize LLM architectures and their training. This understanding paves the way for more nuanced models that bridge discrete and continuous interpretations of language, with both theoretical and practical implications for future AI developments.