- The paper introduces Sequential-NIAH, a novel benchmark designed to evaluate LLMs on extracting sequential needles from long contexts.
- The methodology uses three needle generation pipelines—synthetic-temporal, real-temporal, and real-logical—with a synthetic test accuracy of 99.49%.
- Results highlight LLM performance gaps, with best accuracy around 63.5%, emphasizing challenges in sequence extraction and noise robustness.
Overview of Sequential-NIAH Benchmark
The paper "Sequential-NIAH: A Needle-In-A-Haystack Benchmark for Extracting Sequential Needles from Long Contexts" (2504.04713) introduces a specialized benchmark designed for assessing LLMs in extracting sequential items from extensive textual data. Recognizing the importance of LLMs in processing long sequences, particularly for retrieving strategically embedded information, Sequential-NIAH addresses gaps in existing benchmarks by focusing on the retrieval and order comprehension of sequential information items—or "needles"—spanning significant lengths of context, ranging from 8K to 128K tokens. This benchmark provides a foundation for evaluating and improving the practical capabilities of LLMs in real-world applications that necessitate complex information retrieval and ordering.
Benchmark Design and Needle Pipelines
Sequential-NIAH's architecture comprises three primary needle generation pipelines: synthetic-temporal order, real-temporal order, and real-logical order. These cater to tasks involving temporal and logical sequences typical of real-world scenarios such as legal and financial documentation queries, or certification guides requiring sequential processing. These pipelines ensure the benchmark encompasses both temporal and logical sequencing challenges, generating needles from synthetic or real data sources like the Temporal Knowledge Graph (TKG), enhancing the realism and challenge of tasks within the benchmark.
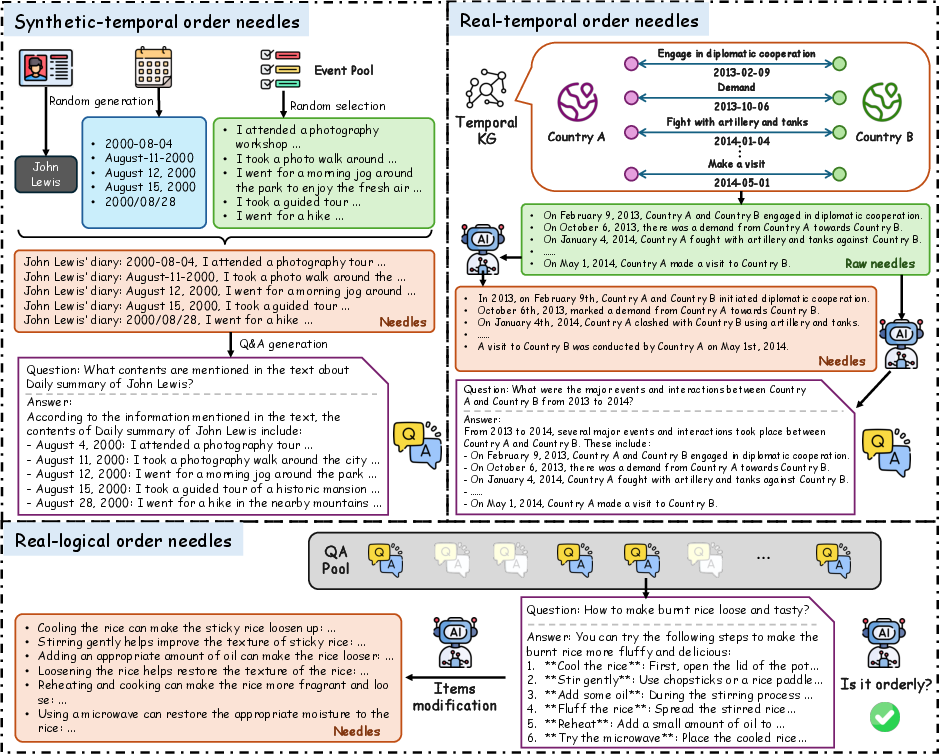
Figure 1: Three pipelines for sequential needles construction, illustrating various methods for generating temporal and logical needles.
Evaluation Model for Sequential-NIAH
The paper underscores the difficulties inherent in evaluating the performance of LLMs due to their complexity and high computation costs when using powerful models like GPT-4 or Claude. To overcome these challenges, an evaluation model trained on synthetic data was developed, achieving an impressive accuracy of 99.49% on synthetic test sets. This model offers a cost-effective, reliable means to evaluate LLM responses against ground truth standards with a special focus on enumeration correctness and sequence fidelity.
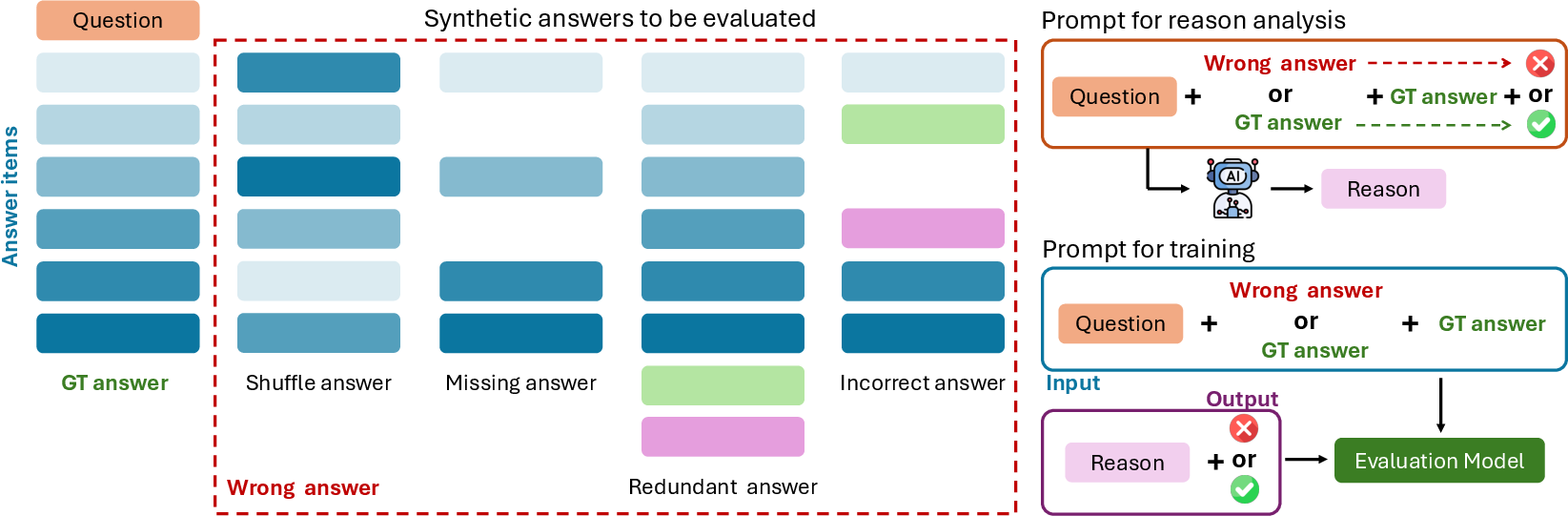
Figure 2: Synthetic different wrong answers for generating diversified training data for evaluation model training.
Results and Implications
Experimental results from testing prominent LLMs (such as GPT-Series, Claude, Gemini, Qwen, and LLaMA) reveal significant room for improvement, with the best-performing model (Gemini-1.5) only achieving 63.50% accuracy. This indicates substantial challenges for LLMs in handling tasks that require extracting sequential information from lengthy contexts. Important observations include increased difficulty with longer contexts and more numerous needles and a notable impact on performance due to noise variance, which further validates the benchmark's robustness as a tool for LLM enhancement.
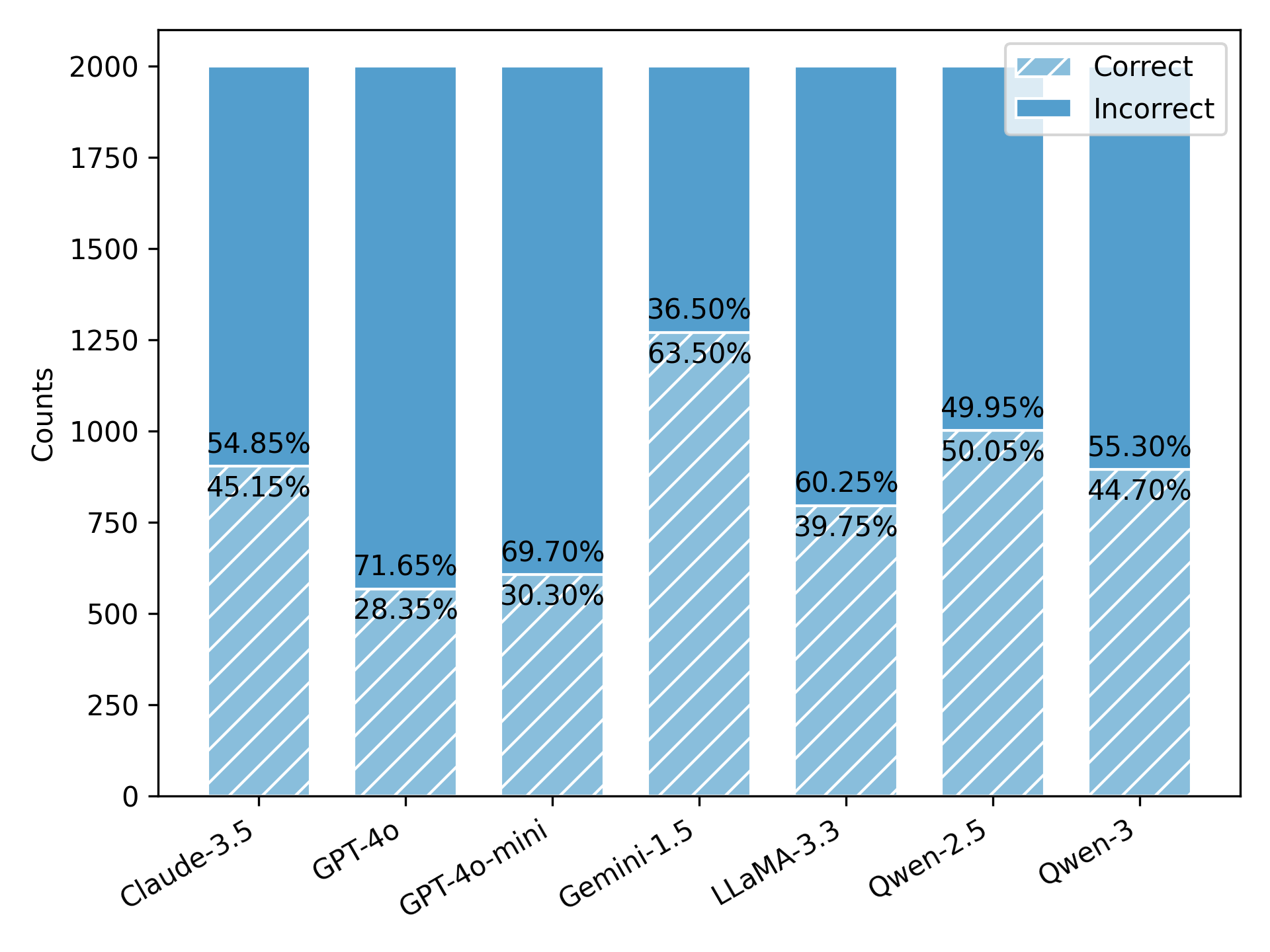
Figure 3: Results comparison of LLMs on all test data of Sequential-NIAH benchmark.
Discussions on Noise Robustness
The benchmark's noise robustness was evaluated by altering the position and order of needles or adding semantically similar but incorrect needles. Results showed models vary in resilience to such perturbations, with shifts impacting models differently depending on noise type and magnitude. This further confirms the robustness and reliability of Sequential-NIAH as a challenging benchmark, essential for advancing LLMs' abilities in sequence processing tasks.
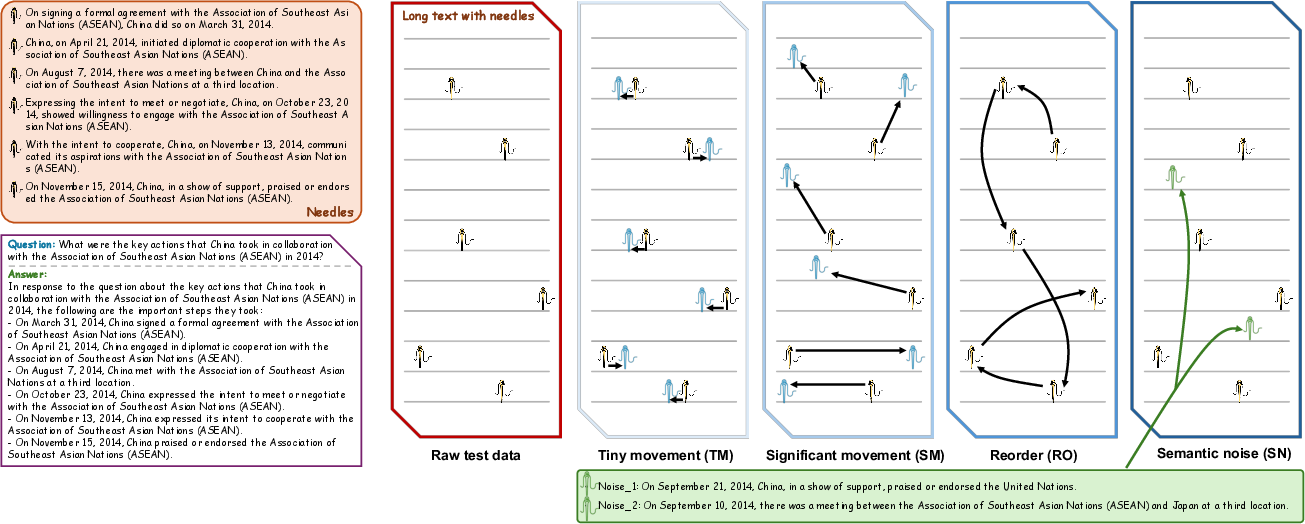
Figure 4: Four types of noise added into the raw test data.
Conclusions
Sequential-NIAH represents a significant step forward in the benchmarking and development of LLMs aimed at complex information retrieval tasks within lengthy contexts. Real-world applications benefit from the benchmark's comprehensive approach to sequential information evaluation. The results highlight critical limitations in current LLM capabilities, outlining substantial potential for further advancement in AI's ability to manage intricate, sequence-dependent tasks.
The implications underscore the need for refined models that can achieve better consistency and performance across diverse, demanding linguistic and contextual settings, reflecting an ongoing evolution towards more adept AI-driven information retrieval solutions.
The paper sets the stage for continued exploration and development in the domain of long-context LLM evaluation, essential for enhancing AI's nuanced information processing capabilities in practical settings. Future work will likely focus on optimized model architectures and novel evaluation paradigms that can accommodate the intricate complexities posed by benchmarks such as Sequential-NIAH.