- The paper presents a novel taxonomy categorizing LLM responses into context-based, common knowledge, enterprise-specific, and innocuous outputs.
- It introduces the HDM-2 architecture with modular verification modules that detect inconsistencies in context and common knowledge.
- Experimental results on datasets like HDMBench show significant improvements in precision and recall over existing methods.
HalluciNot: Hallucination Detection Through Context and Common Knowledge Verification
This essay provides a detailed summary of the paper "HalluciNot: Hallucination Detection Through Context and Common Knowledge Verification" (2504.07069), focusing on its implementation, empirical results, and research implications for LLMs in enterprise settings.
Taxonomy of LLM Responses
The paper introduces a novel taxonomy for categorizing LLM responses within enterprise applications. The taxonomy identifies four distinct categories: context-based, common knowledge, enterprise-specific, and innocuous statements. This classification allows for a more nuanced detection approach, catering to specific knowledge domains and business requirements.

Figure 1: An example interaction with an LLM, with our taxonomy categorizations. Best viewed in color.
This taxonomy's significance lies in its ability to parse and identify hallucination types, which traditional methods fail to distinguish. The proposed taxonomy is crucial for enterprises where the accuracy of information generated by LLMs is paramount.
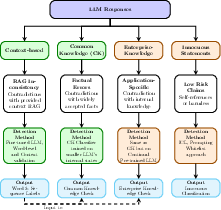
Figure 2: Our proposed taxonomy of LLM response for enterprise settings, showing the four distinct categories and their detection approaches. This paper focuses on context-based and common knowledge hallucinations (shown in green).
Model Architecture: HDM-2
The paper introduces HDM-2, a multi-task model specifically designed to enhance hallucination detection by leveraging the defined taxonomy. HDM-2 operates through separate modules that independently verify context-based and common knowledge hallucinations, allowing for targeted optimization and deployment flexibility.
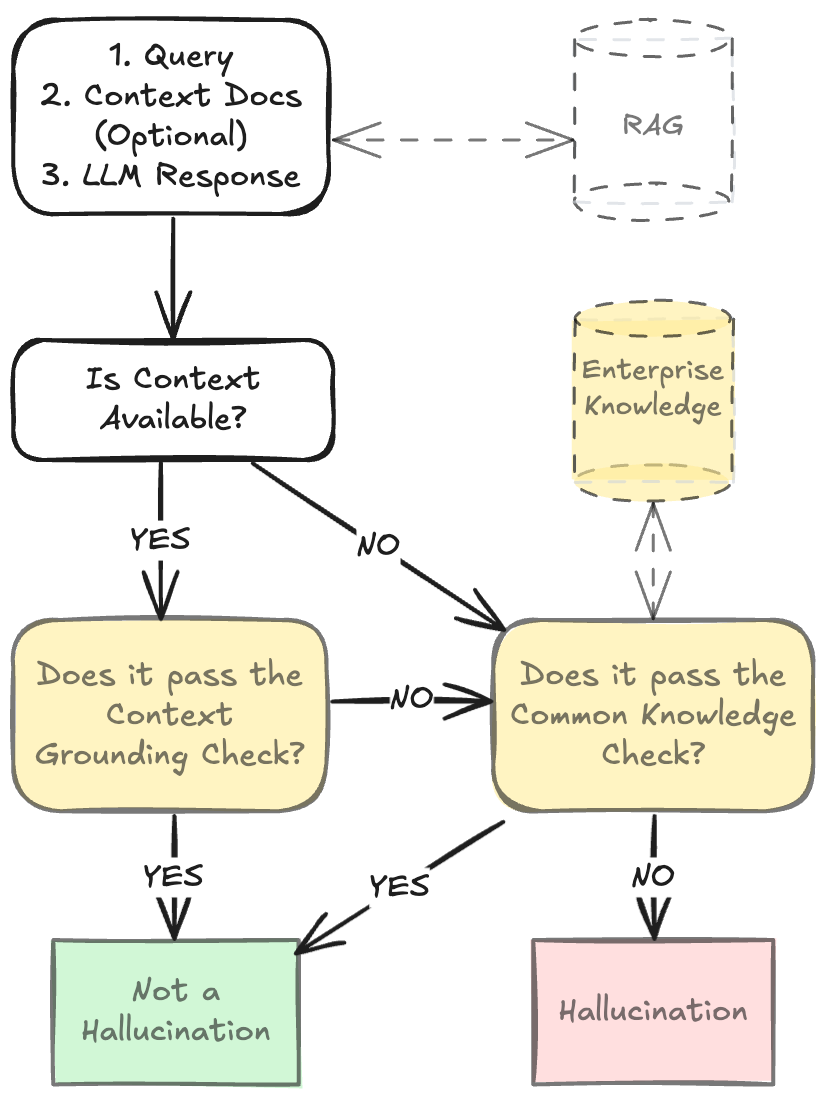
Figure 3: Our system takes the query, optional context documents, and LLM response as its input and produces a judgement of the LLM response as Hallucination or Not a Hallucination. Shaded areas denote our models (round edges) and their outputs (sharp edges); and dashed lines denote optional components. Context documents could be obtained from an enterprise's existing RAG system. Our model can be extended with private enterprise-specific knowledge for the Common-Knowledge Check.
The architecture includes layers trained to detect contradictions within context and common knowledge, using a combination of token-level and sentence-level scoring. By implementing a modular structure, HDM-2 facilitates easy adaptation to new enterprise-specific datasets and rapidly evolving domains.
Dataset Construction: HDMBench
HDMBench, the dataset released alongside the model, addresses the unique challenges of enterprise hallucination detection, filling a critical gap where current benchmarks fall short. It includes approximately 50,000 documents from diverse sources such as RAGTruth and enterprise support tickets, featuring varied question types and stylistic diversity in generated responses. This dataset is paramount for training models that require a comprehensive understanding of context and general knowledge.
Experimental Results
The empirical evaluation of HDM-2 shows significant performance improvements over existing methods. Across the RagTruth, TruthfulQA, and HDMBench datasets, HDM-2 demonstrates superior precision and recall, markedly enhancing the state-of-the-art in context and common knowledge hallucination detection.
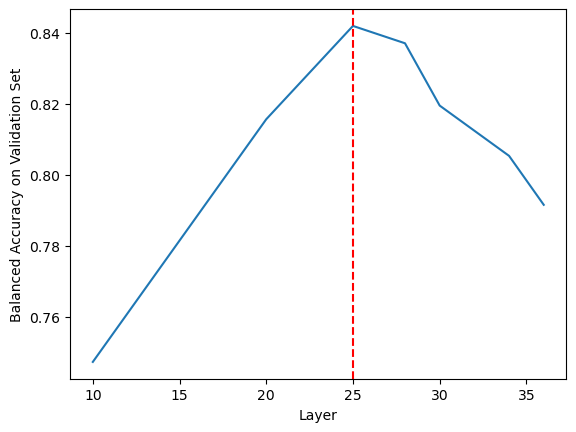
Figure 4: Common Knowledge hallucination detection (CK) performance (balanced accuracy on the validation set) for different intermediate layers of the backbone LLM (Qwen-2.5-3B-Instruct). The performance improves as we go from lower to higher layers, peaks at layer 25, and decreases as we go to the final layers.
Implementation Considerations
The model employs Qwen-2.5-3B-Instruct as its backbone, and its detection tasks are optimized using various classification heads and low-rank adapters. These choices balance performance with computational efficiency, making HDM-2 suitable for real-time enterprise applications. The modular nature of HDM-2 ensures adaptability to proprietary knowledge bases, a crucial requirement for enterprises.
Conclusion
"HalluciNot" presents a transformative approach to hallucination detection in LLM outputs for enterprises, introducing a comprehensive taxonomy and a highly effective model architecture. While HDM-2 excels in context and common knowledge hallucinations, future research could focus on improving efficiency, multilingual capabilities, and resistance to adversarial attacks. As the deployment of LLMs in high-stakes settings continues to rise, this approach offers a vital advancement towards ensuring accuracy, reliability, and trust in AI-generated information.