- The paper demonstrates that small models, when paired with language-specific tokenizers, can generate coherent regional narratives.
- It employs a two-phase approach combining translation and synthetic data generation to create diverse datasets for Hindi, Marathi, and Bengali.
- Findings reveal that tailored tokenizers like Sarvam and SUTRA enhance performance, with Hindi models excelling in grammar and fluency metrics.
Introduction
The study "Regional Tiny Stories: Using Small Models to Compare Language Learning and Tokenizer Performance" investigates the application of Small LLMs (SLMs) in regional languages, specifically focusing on Hindi, Marathi, and Bengali. The research builds on the TinyStories framework, which demonstrated that SLMs with fewer parameters could effectively generate coherent narratives. This work extends the framework to Indian languages with the goal of understanding linguistic complexity and evaluating tokenizer performance.
Methodology
The methodology involves a two-phase approach: first, translating the original English TinyStories dataset into Indian languages, and second, augmenting the dataset with synthetic stories generated using LLMs. The study employs specific Indian language tokenizers like Sarvam and SUTRA, contrasting them against general-purpose tokenizers.
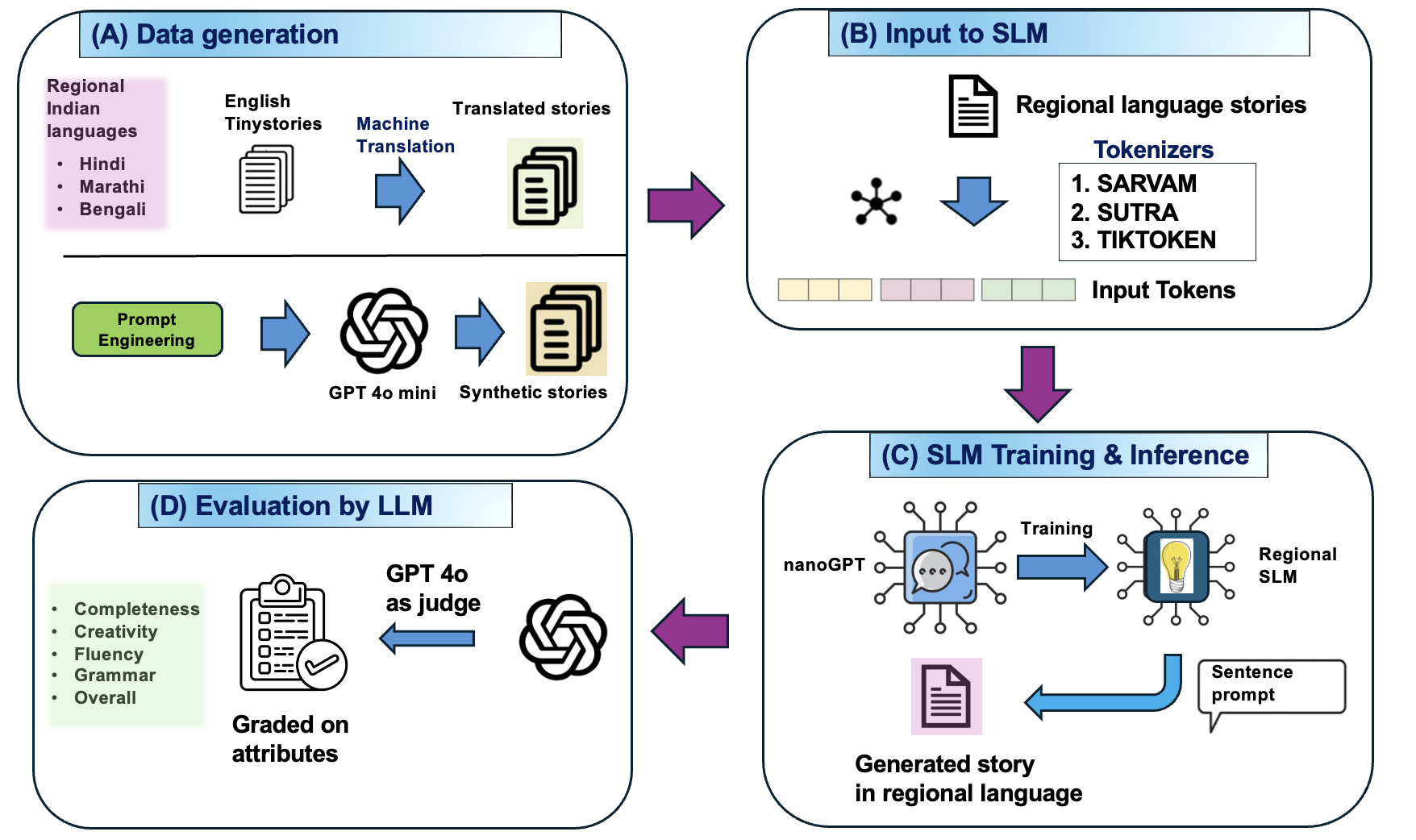
Figure 1: Schematic of model pipeline. (A) Dataset prepared through machine translation as well as generation using LLM, (B) Indic tokenizers are used to preprocess the Indian language stories, (C) A decoder only transformer architecture is used to train the model in each language, (D) Inference is evaluated by LLM on certain attributes.
Data Generation and Model Training
- Translated Data: Utilizes NLLB-200-3B and Google Translate to convert English TinyStories into Hindi and Bengali, ensuring semantic preservation and cultural appropriateness through verification by LLMs.
- Synthetic Data: Generated using GPT-4o-mini, incorporating a sophisticated prompt-generation system to maintain narrative diversity and avoid repetition. The synthetic dataset includes 1.8 million translated and 2.2 million synthetic stories per language.
Tokenization and Inference
The study highlights the superiority of language-specific tokenizers over general-purpose ones. Sarvam and SUTRA tokenizers, tailored for Indian scripts, provide better tokenization, reflected in improved model performance metrics such as evaluation loss and contextual understanding.
Results and Insights
Evaluation reveals that SLMs with parameters between 5M and 50M deliver strong linguistic capabilities. Hindi models achieve the highest performance, followed by Bengali and Marathi, with Hindi benefiting more from increased architectural width.
- Hindi Models: Achieve superior performance in grammar (8.91/10) and fluency (8.55/10).
- Cross-Linguistic Complexity: Analyzed using Rènyi entropy, highlighting Marathi's complexity due to higher entropy values.
Tokenizer Comparison
Sarvam tokenizers excel in context and narrative quality, outperforming Tiktoken and other general-purpose alternatives. The evaluation suggests language-specific tokenizers better capture idiomatic and structural nuances.
Implementation Considerations
The study demonstrates practical implications for deploying SLMs in resource-constrained environments, offering efficient language modeling solutions without requiring extensive computational resources or massive datasets. The methodology for fast adaptation to regional languages via translation and synthesis is pivotal for democratizing AI for underrepresented languages.
Conclusion
The study underscores the potential of small models in regional language processing, illustrating that SLMs can match or surpass larger models when equipped with tailored tokenizers and datasets. By providing a framework to evaluate linguistic complexity and tokenizer efficiency, this research contributes to our understanding of neural language development and promotes advancements in low-resource language modeling.
The findings pave the way for future research in optimizing LLM architectures and tokenization for diverse linguistic landscapes, promoting equitable access to AI capabilities.