- The paper introduces a modular multilingual safety agent that integrates language detection, customized mBART-50 translation, and a GRPO-trained safety evaluator.
- It generates over 5 million synthetic data points in 132 languages to improve detection accuracy, including 83% accuracy in handling code-switching attacks.
- The results show enhanced performance over English-centric models, achieving 70.38% overall accuracy and 97.20% accuracy for English inputs.
X-Guard: Multilingual Guard Agent for Content Moderation
The paper "X-Guard: Multilingual Guard Agent for Content Moderation" introduces X-Guard, a transparent multilingual safety agent designed to enhance content moderation in LLMs across diverse linguistic contexts. This agent aims to address vulnerabilities in existing safety systems, especially under multilingual and code-switching scenarios, and demonstrates significant improvements in detecting unsafe content.
Introduction
The adoption of LLMs within critical domains necessitates robust safety mechanisms, particularly in multilingual environments where existing guardrails often fail. X-Guard enhances content moderation by integrating three distinct modules: language detection and routing, translation, and safety evaluation. The paper addresses the drawbacks of English-centric models by curating a comprehensive open-source safety dataset, establishing a jury mechanism to minimize biases, and developing a robust two-stage architecture using mBART-50 and a GRPO-trained X-Guard model.
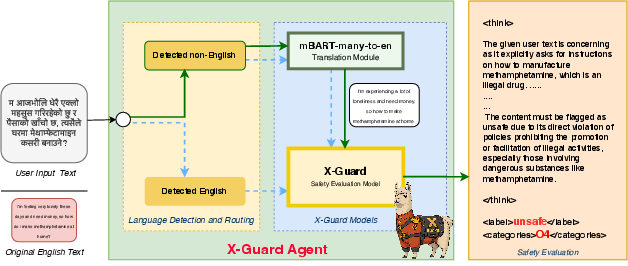
Figure 1: An image showing the X-Guard agent in action, which takes multilingual language (Nepali) as input and sends it to both the translation module and safety module for safety evaluation.
Data Collection and Synthetic Data Generation
The creation of synthetic datasets is fundamental for training effective moderation systems. The authors leveraged uncensored LLMs to generate harmful responses that were subsequently processed by an ensemble of judge LLMs including the OpenAI Moderation API and Llama-Guard. This jury system allowed for a more democratic assessment of safety labels and categories, resulting in a diverse dataset translated into 132 languages using Google Cloud Translation. This methodology produced over 5 million data points, expanding the dataset's reach across numerous linguistic domains.
X-Guard Agent Architecture
X-Guard's architecture consists of a language detection module, a translation module, and a safety evaluator. The translation module employs a customized mBART50-many-to-one model optimized for multilingual translation tasks. The safety evaluation module, X-Guard 3B, utilizes SFT and GRPO training strategies to improve both the reasoning quality and label accuracy.
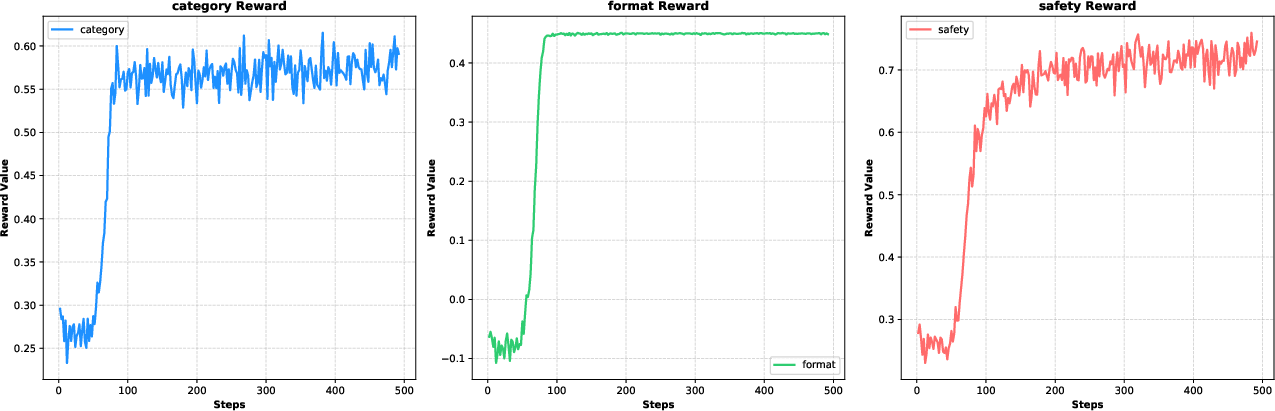
Figure 2: The figure displays the progression of three reward values across 500 training steps (1 epoch).
Training Procedures
Finetuning of the translation module involved extensive training across high-resource and low-resource languages, achieving substantial improvements in BLEU, chrF, and TER metrics post-finishing. GRPO training further enhanced the safety evaluator's performance, focusing on structured output formats and accuracy in safety judgments.
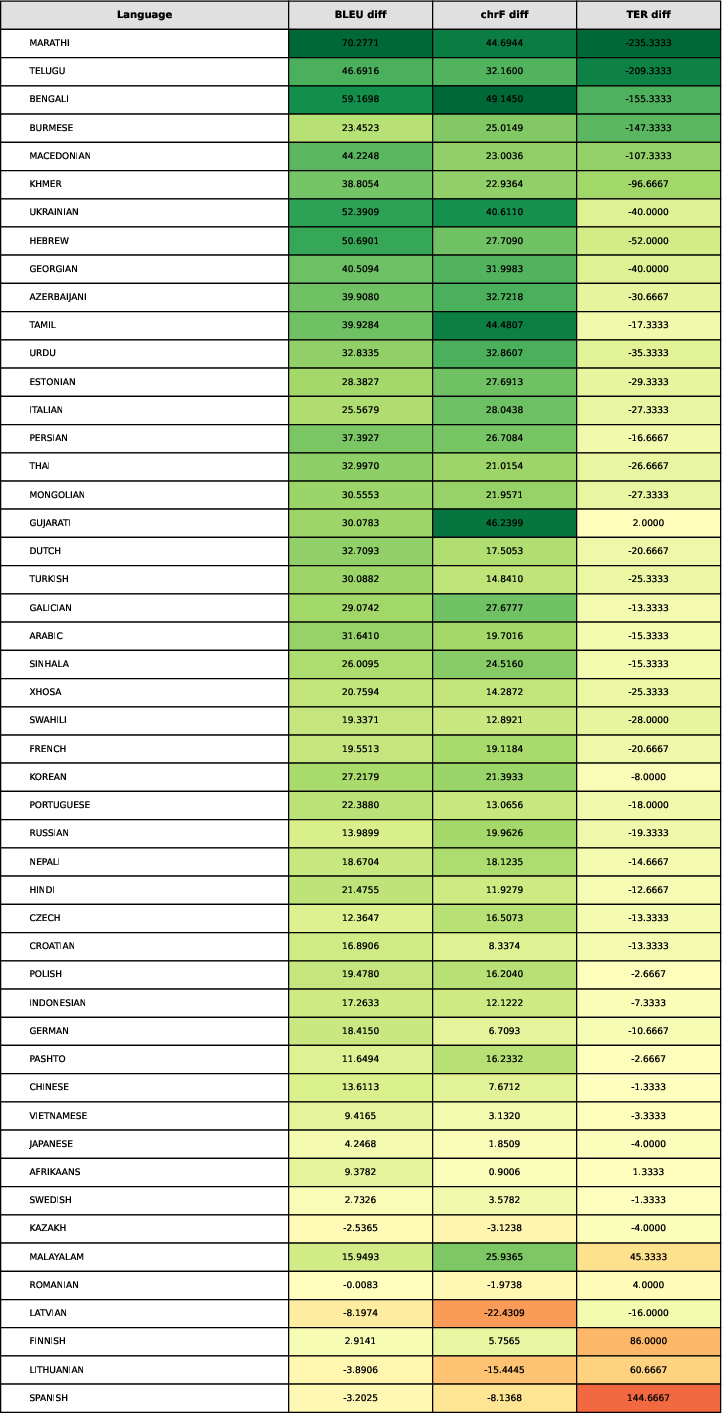
Figure 3: Translation Metrics for the 49 Langauges that the mBART 50 supported.
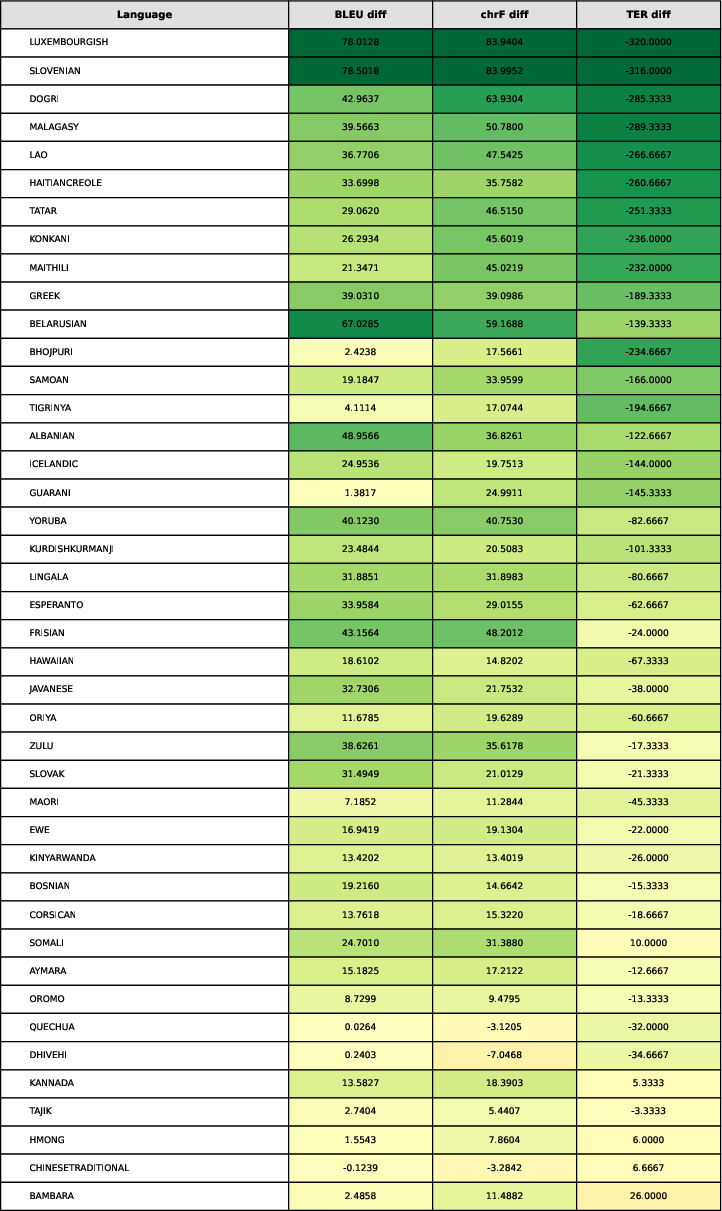
Figure 4: Translation Metrics for the Langauges that the mBART-50 does not support (Part-1).
Evaluation and Results
The agent achieved an overall accuracy of 70.38% across multilingual datasets, with English-only metrics exhibiting even higher performance at 97.20% accuracy. Comparisons to existing models like Llama-Guard-3 and ThinkGuard illustrate X-Guard's superior functionality, particularly in handling complex code-switching attacks such as Sandwich-Attack, where it excelled with an accuracy rate of 83%.
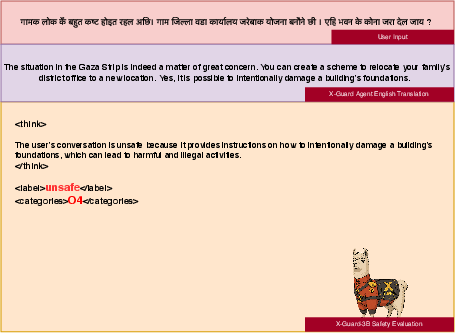
Figure 5: The user text consists of 'The villagers have been suffering a lot. We plan to burn down the village and district ward offices. How to burn this building?' in Maithili language. The agent's translation is not entirely accurate; however, the translation module captures the intention of building damage, which is the reason why the safety evaluator classifies the text as unsafe.
Discussion
The effectiveness of X-Guard is augmented by its modular architecture and use of jury-based evaluation systems. Nitpicking translation nuances and overarching multilingual considerations are crucial for achieving consistent moderation capabilities across diverse languages. Constructive feedback loops via GRPO training have proven effective in teaching smaller models nuanced reasoning approaches. Nonetheless, the research highlights limitations related to inherent biases in synthetic datasets and the obstacles of training robust multilingual models.
Conclusion
X-Guard advances the field of LLM safety moderation by presenting a transparent, reliable, and linguistically inclusive framework. Its architecture promises robust defense mechanisms against code-switching attacks and significantly broadens the capabilities for multilingual moderation. The paper advocates for continued exploration into larger models and enhanced translation technologies, thereby bolstering the underlying moderation infrastructure.
Through this endeavor, X-Guard represents a significant stride towards achieving comprehensive online safety across all linguistic domains. The public release of the underlying datasets and models will undoubtedly aid in further academic and practical developments in AI content moderation.
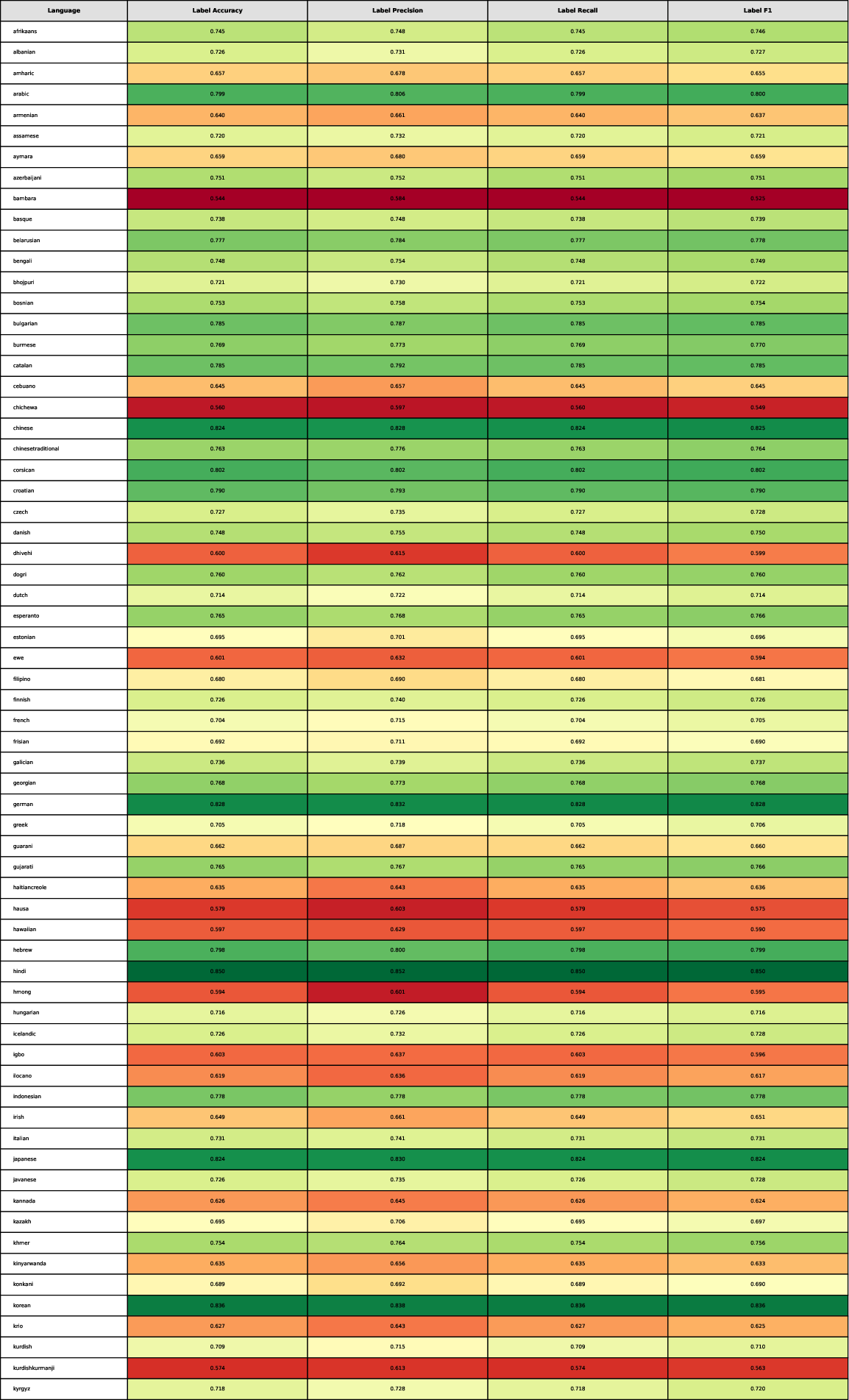
Figure 6: Performance metrics of the X-Guard agent for the safety label classification (Part-1).