GraphCodeAgent: Dual Graph-Guided LLM Agent for Retrieval-Augmented Repo-Level Code Generation
Abstract: Writing code requires significant time and effort in software development. To automate this process, researchers have made substantial progress for code generation. Recently, LLMs have demonstrated remarkable proficiency in function-level code generation, yet their performance significantly degrades in the real-world software development process, where coding tasks are deeply embedded within specific repository contexts. Existing studies attempt to use retrieval-augmented code generation (RACG) approaches to mitigate this demand. However, there is a gap between natural language (NL) requirements and programming implementations. This results in the failure to retrieve the relevant code of these fine-grained subtasks. To address this challenge, we propose GraphCodeAgent, a dual graph-guided LLM agent for retrieval-augmented repo-level code generation, bridging the gap between NL requirements and programming implementations. Our approach constructs two interconnected graphs: a Requirement Graph (RG) to model requirement relations of code snippets within the repository, as well as the relations between the target requirement and the requirements of these code snippets, and a Structural-Semantic Code Graph (SSCG) to capture the repository's intricate code dependencies. Guided by this, an LLM-powered agent performs multi-hop reasoning to systematically retrieve all context code snippets, including implicit and explicit code snippets, even if they are not explicitly expressed in requirements. We evaluated GraphCodeAgent on three advanced LLMs with the two widely-used repo-level code generation benchmarks DevEval and CoderEval. Extensive experiment results show that GraphCodeAgent significantly outperforms state-of-the-art baselines.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
Big AI models can write short bits of code pretty well, but real software lives inside huge projects with many files that depend on each other. This paper introduces a smarter way (they call it “CodeRAG”) to help an AI write code that fits correctly into a whole codebase (a repository), not just a small, isolated function.
The key idea: build two “maps” of the project so the AI can figure out what code it needs to look at—even if the original request doesn’t spell out every little step. Then let an “agent” (the AI plus tools) explore those maps, collect the right code pieces, and use them to generate the final code.
What questions the authors wanted to answer
- Why do AIs that write code stumble on big projects, and how can we fix that?
- Can we get the AI to find the hidden pieces it needs (like helper functions and settings) that aren’t directly mentioned in the user’s request?
- Will this approach actually make the AI’s code more correct on real-world benchmarks?
How they tackled the problem (in simple terms)
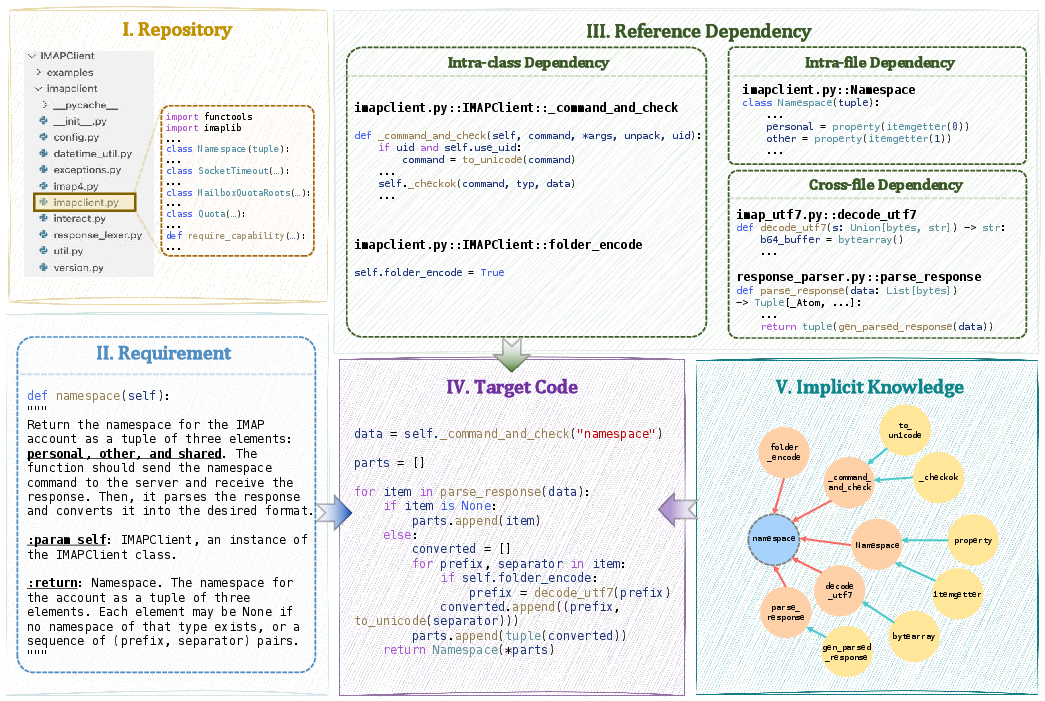
Think of a repository (repo) like a big library with rooms (folders), shelves (files), and lots of books (functions, classes). When you ask for a new feature, your request might only say the big goal (“add user signup”). But to do it right, you also need many smaller, hidden steps (validations, security checks, database calls) that the repo already has coded somewhere.
To help the AI find all this, the authors build two connected maps:
- Map 1: Requirement Graph (RG)
- What it is: A map of “what tasks are related to this task.”
- Analogy: If your goal is “bake a cake,” the RG shows hidden sub-tasks like “preheat oven,” “mix batter,” and “measure ingredients,” plus similar recipes you can copy ideas from.
- In code terms: It models the relationships between high-level requirements (the goal you stated), their subrequirements (the smaller tasks), and similar requirements across the repo.
- Map 2: Structural–Semantic Code Graph (SSCG)
- What it is: A map of “how the code pieces relate to each other.”
- Analogy: A metro map for the codebase—showing which function calls which, which classes inherit others, and which files import which.
- In code terms: It captures imports, function calls, class inheritance, what’s inside what, and which code pieces are similar in meaning.
They connect the two maps so the AI can jump from “what needs to be done” (RG) to “where in the code this is implemented” (SSCG).
Then they use an LLM “agent” (a problem-solving AI) that:
- Starts from your request,
- Uses the Requirement Graph to discover hidden subtasks and similar examples,
- Maps those to concrete code pieces via the Code Graph,
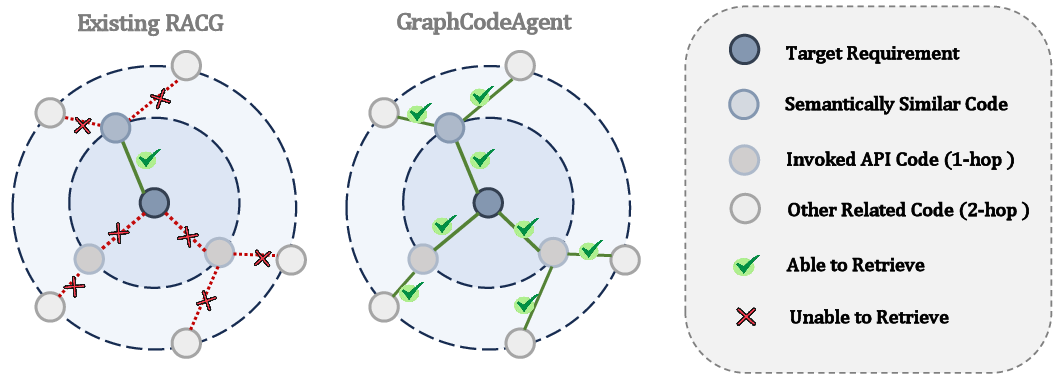
- “Walks” the code graph step by step (multi-hop reasoning) to pick up all needed helpers (like called APIs, related classes, config files),
- Optionally looks up fresh web knowledge (e.g., how to use a library) when needed,
- Finally generates the code and runs quick checks to fix basic issues (like formatting).
In everyday language: The AI acts like a detective using two maps—one for “what to do,” one for “where it lives”—to find all the clues it needs before writing the solution.
What they found
They tested their method on two big benchmarks that simulate real project coding:
- DevEval: many tasks spread across 117 real repositories
- CoderEval: tasks where the code must run and pass tests
They compared against several strong baselines (simple keyword matching, semantic search, graph-based methods, and agent tools). Their method improved the “Pass@1” score (did the first try pass all tests?) by a lot:
- On DevEval:
- With GPT-4o: about 44% relative improvement over the best baseline
- With Gemini 1.5 Pro: about 39% relative improvement
- On CoderEval:
- With GPT-4o: about 32% relative improvement
- With Gemini 1.5 Pro: about 8% relative improvement
- It also beat baselines on a reasoning-focused model (QwQ-32B) by around 11% relative improvement.
Other key points:
- It shines most when the target code depends on many other files (complex dependencies).
- The retrieval (finding the right code context) usually takes only a few seconds.
- It can fetch both:
- Implicit knowledge: APIs that will be called, multi-step related code that wasn’t mentioned
- Explicit knowledge: similar code examples and up-to-date info from the web
Why this matters
- Smarter coding assistants: Instead of guessing or only using what’s written in the request, the AI can discover the hidden steps and code pieces needed for the task. That means fewer broken builds and less back-and-forth.
- Works in real projects: Modern apps are big and interconnected. This approach helps AIs handle real repo structure, not just toy problems.
- Faster development: Developers can get code that fits their project’s style and dependencies more quickly, saving time on searching, wiring, and fixing.
- Broader potential: The same dual-map idea could help with bug fixing, feature exploration, code search, onboarding to a new codebase, and more.
In short: By giving the AI two connected maps—one of tasks and one of code—and letting it reason step by step, the authors make it much better at writing code that actually works inside large, complex projects.
Glossary
- Agent-based approaches: Methods that employ autonomous software agents (often powered by LLMs) to plan, retrieve, and generate code iteratively. "Recent agent-based approaches have received increasing attention in code generation"
- Agentic RACG: Retrieval-augmented code generation frameworks that explicitly leverage agent reasoning and tool use to iteratively retrieve and integrate context. "Agentic RACG"
- BM25 algorithm: A classic sparse information retrieval ranking function that scores textual relevance using term frequency and inverse document frequency with length normalization. "we use the BM25 algorithm to calculate the textual similarity"
- CodeAgent: An LLM-based agent framework designed for repo-level code generation with specialized programming tools and strategies. "CodeAgent is a pioneer LLM-based agent framework for repo-level code generation"
- Code completion: The task of automatically generating missing or next portions of code based on context. "graph-based retrieval-augmented code completion framework"
- Code context graph (CCG): A graph representation of code that encodes statement-level relations such as control-flow and data-dependencies for completion tasks. "a code context graph (CCG)"
- CoderEval: A repo-level benchmark derived from open-source projects that evaluates functional correctness of generated code within a project-level execution environment. "We use the Python tasks of CoderEval to evaluate the effectiveness of ."
- Context window: The maximum number of tokens an LLM can ingest at once; larger windows allow more context but can degrade model understanding. "modern LLMs support context windows of hundreds of thousands of tokens"
- Control-dependence: A program analysis relation indicating that execution of one statement depends on the outcome of a control statement (e.g., if/while). "control-dependence between code statements"
- Control-flow: The order in which individual statements, instructions, or function calls are executed or evaluated in a program. "control-flow, data-dependency, and control-dependence"
- Cosine similarity: A measure of semantic proximity between two embedding vectors based on the cosine of the angle between them. "We then calculate the cosine similarity of two code elements' vector representations"
- Dense retrieval: Retrieval that uses learned embedding vectors to perform semantic search rather than purely lexical matching. "Early approaches use sparse retrieval and dense retrieval to search textually similar or semantically similar code from the repository"
- DevEval: A large-scale repo-level code generation benchmark across multiple domains that assesses code generation within real repositories. "the widely-used repo-level code generation benchmarks DevEval and CoderEval"
- Docstring: A structured documentation string associated with code elements (e.g., functions) describing behavior or usage. "Each example also includes the human-labeled docstring for the target function"
- DuckDuckGo: A search engine used to retrieve up-to-date external domain knowledge via an accessible API for agent tool use. "We introduce a web search tool by using a popular search engine DuckDuckGo"
- Embedding model: A model that maps code or text into dense vector representations used for semantic similarity and retrieval. "use an advanced embedding model to encode each code element"
- GraphCoder: A graph-based retrieval-augmented framework that models code relations to improve completion with structural context. "GraphCoder is a graph-based retrieval-augmented code completion framework"
- Heterogeneous directed graph: A directed graph with multiple node and edge types capturing varied entities and relations (e.g., files, functions, imports). "SSCG is also a heterogeneous directed graph"
- HumanEval: A benchmark of function-level programming tasks used to measure LLM code generation accuracy. "benchmarks like HumanEval"
- Import relation: An edge type indicating that a file imports classes or functions from another file. "the import relation from one file to classes or functions in other files"
- Inherit relation: An edge type indicating that one class inherits from another. "the inherit relation allows one class to inherit another class"
- Invoke relation: An edge type indicating that a code element calls or invokes another code element (e.g., function/method). "The invoke relation means one code element invokes another code"
- LLMs: Transformer-based models trained on vast corpora that can understand and generate natural language and code. "LLMs have demonstrated impressive capabilities in function-level code generation"
- Meta path: A typed path pattern over a heterogeneous graph that guides structured traversal and reasoning across specific node/edge types. "proper meta paths, which is a crucial element for heterogeneous code graph analysis"
- Multi-hop reasoning: Iteratively chaining related nodes or pieces of evidence across multiple steps to retrieve or infer relevant context. "perform multi-hop reasoning to identify additional code snippets"
- Neo4j: A graph database used to store graph indices for efficient retrieval and traversal of nodes and edges. "reserving an index of nodes and edges into Neo4j"
- Parent-child relation: A requirement-level edge indicating that a parent requirement invokes or depends on a subrequirement. "The parent-child relation means the correlation between a parent requirement and its subrequirement"
- Pass@1: The probability that at least one generated solution among a single sample passes all tests; common metric for code generation. "in terms of Pass@1"
- Pass@k: The expected probability that at least one of k sampled solutions passes all tests; standard evaluation metric in program synthesis. "we use Pass@k, a popular metric in code generation"
- RACG (Retrieval-augmented code generation): Approaches that augment LLMs with retrieved code or knowledge to improve context-aware generation. "retrieval-augmented code generation (RACG) has become a mainstream strategy"
- ReAct: A prompting strategy that interleaves reasoning (thought) with actions (tool use) and observations to guide agents. "We apply the ReAct reasoning strategy to guild the agent"
- Repo-level code generation: Generating code within the context of a specific repository, respecting its structure, APIs, and dependencies. "repo-level code generation requires not only syntactic correctness but also awareness of project-specific structure, dependencies, and conventions"
- RepoCoder: An iterative retrieval-generation method that repeatedly fetches relevant code and regenerates solutions to refine output. "RepoCoder introduces an iterative retrieval generation pipeline"
- Requirement Graph (RG): A heterogeneous graph modeling requirement relations among repository code elements and with the target requirement. "We propose a Requirement Graph (RG) that captures the relations of code elements' requirements"
- Semantically similar relation: A requirement-level edge indicating two requirements share similar functionality. "The semantically similar relation shows that two requirements have similar functionalities"
- Sparse retrieval: Lexical retrieval based on exact term matching and inverted indexes rather than embeddings. "Early approaches use sparse retrieval and dense retrieval"
- Structural-Semantic Code Graph (SSCG): A heterogeneous code graph capturing both structural (imports, invocations) and semantic similarity relations within a repository. "a Structural-Semantic Code Graph (SSCG) that captures both syntactic and semantic relationships within the repository"
- Tree-sitter: A parser generator and incremental parsing library used for static analysis of code structure. "we first use the static analysis tool tree-sitter to identify all functions, classes, and methods predefined in the repository"
- Vectorized representations: Dense numerical embeddings of code/text used for semantic search and similarity computations. "dense retrieval relies on maintaining and frequent updating of vectorized representations"
- WebSearch tool: An agent tool that queries the web (e.g., DuckDuckGo) and summarizes external content to provide up-to-date domain knowledge. "meanwhile employs the WebSearch tool to search relevant domain knowledge if needed"
Collections
Sign up for free to add this paper to one or more collections.