- The paper introduces layer freezing as a novel fidelity axis that uses the number of trainable layers to control memory and compute costs during hyperparameter optimization.
- It demonstrates that even with only 40% of layers trainable, low-fidelity evaluations maintain high rank preservation (Spearman >0.95) relative to full-fidelity results.
- Empirical results show VRAM reductions of ≥3× and per-step speed improvements of ≥4×, making HPO feasible on commodity GPUs.
Frozen Layers as a Resource- and Memory-Efficient Fidelity for Multi-Fidelity Hyperparameter Optimization
Motivation and Background
Hyperparameter optimization (HPO) in deep learning is fundamentally constrained by the computational and memory costs associated with training large-scale neural networks. The paradigm of multi-fidelity HPO (MF-HPO) circumvents exhaustive full-budget evaluations by leveraging lower-fidelity proxies, such as truncated training durations or reduced dataset sizes. However, conventional fidelity sources fail to provide direct control over GPU memory and do not readily decouple compute cost from fidelity level, particularly in regimes of limited hardware.
The paper introduces layer freezing—the number of trainable layers—as a novel fidelity axis for MF-HPO. This approach exposes an explicit control knob for memory and compute expenditure during training, thereby enabling efficient hyperparameter evaluation even on memory-constrained hardware. The method is evaluated empirically using both GPT-2 style Transformers and ResNet architectures.
Method: Layer Freezing as Fidelity
The key idea is to treat the number of layers ℓ that are updated (with the remaining n−ℓ layers fixed at initialization) as a fidelity variable z. By varying z, the evaluation function transitions smoothly from the lowest-fidelity regime (only the output layers trained) to full-fidelity training (all layers trainable). This approach satisfies the formal requirements for an effective fidelity:
- Cost monotonicity: For fixed hyperparameters, increasing the number of trainable layers always increases computational cost (FLOPs, wall-clock time, VRAM footprint).
- Rank preservation: Despite the crude nature of partially untrained networks, relative hyperparameter rankings (e.g., via Spearman correlation to final validation metrics) are highly correlated at surprisingly low fidelities.
An implementation leverages a simple architectural traversal, freezing parameters except for the last ℓ layers via parameter requires_grad settings. Practical splitting is generally aligned with functional blocks (e.g., residual blocks, Transformer encoder layers), but the approach is general.
Empirical Results: Resource Savings and Fidelity Proxy Quality
Resource Efficiency
GPU VRAM and runtime decrease steeply as lower-fidelity regimes are used:
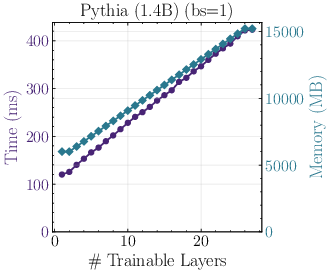
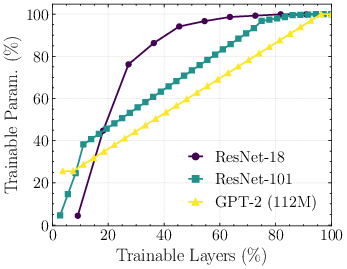
Figure 2: (Left) For Pythia 1.4B, memory and runtime under different numbers of trainable layers; (Right) distribution of trainable parameters per layer/block for ResNet variants.
With minimal batch size, training a large Transformer with only output layers trainable can reduce VRAM demand by ≥3× and per-step walltime by ≥4× relative to full training. This enables HPO for large architectures on commodity GPUs.
Monotonicity and Fidelity
Both compute and performance metrics follow a strictly monotonic relationship with respect to the number of activated layers:
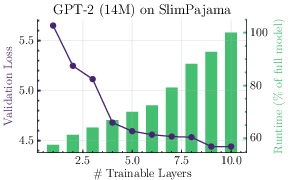
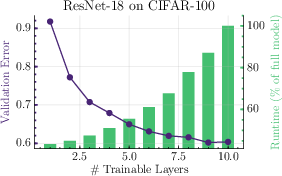
Figure 1: Compute and performance monotonicity as a function of the number of trainable layers for a 14M GPT-2 and a ResNet-18.
Even with only 40% of the layers trainable, rank correlations with full-fidelity HPO results are >0.95 for both GPT-2 and ResNet models:
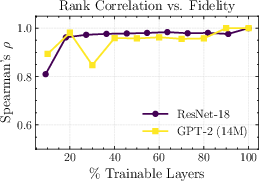
Figure 3: Correlation (Spearman’s ρ) of low-fidelity HPO results (varying numbers of trainable layers) with full-fidelity rankings for both GPT-2 and ResNet-18.
Notably, even at the lowest practical fidelities, where only a single functional block is updated, rank correlation remains substantial (ρ≈0.8). Increasing the proportion of trainable layers improves rank correlation monotonically.
Hyperparameter Search in Multi-Fidelity Regimes
A grid sweep over joint fidelities—training tokens and number of active layers—demonstrates that, for large regions of the fidelity space, high-rank correlations can be obtained at significantly reduced costs:
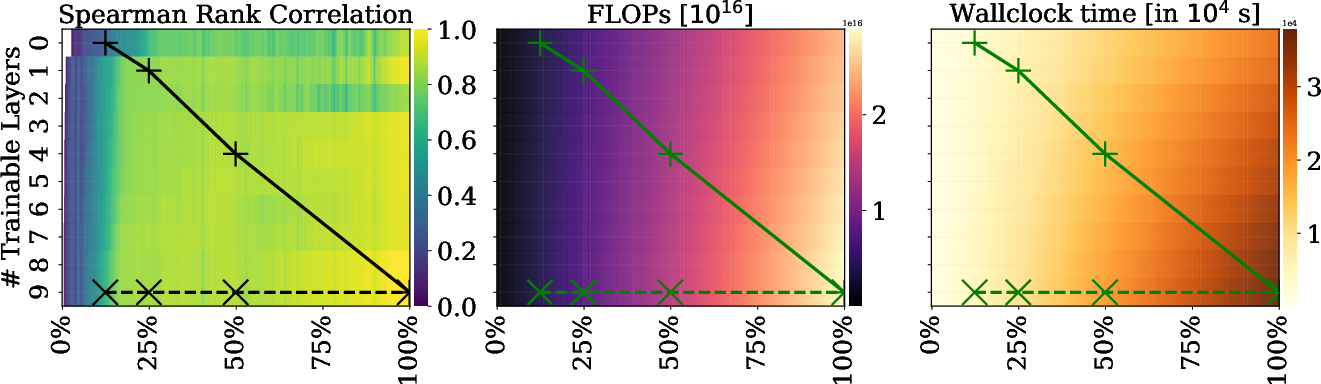
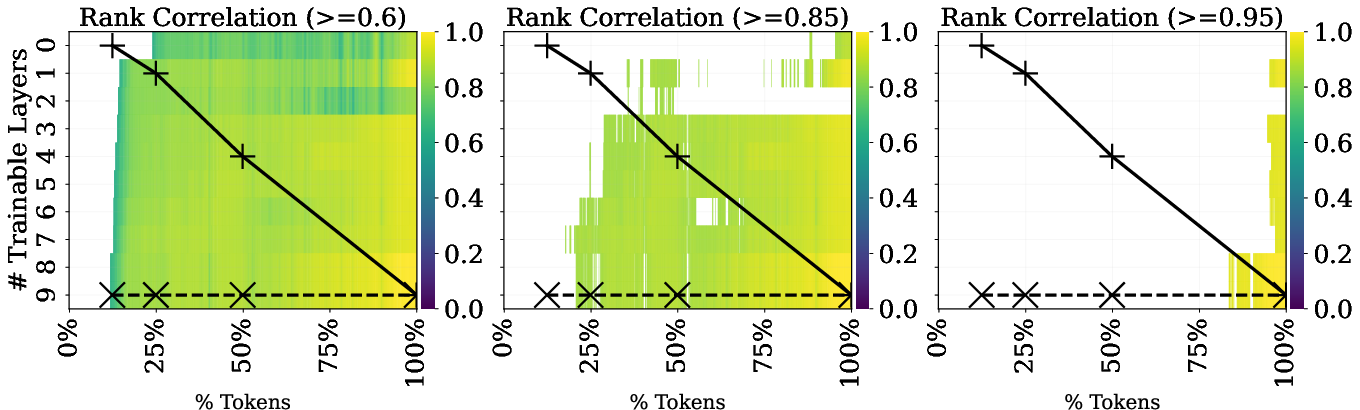
Figure 4: Spearman rank correlation across joint fidelity space (trainable layers vs. tokens) for 14M GPT-2, with overlays showing resource cost and possible Successive Halving (SH) trajectories.
Successive Halving algorithms can be adapted to exploit this joint fidelity structure, e.g., by running more parallel low-fidelity jobs, and advancing only promising hyperparameter configurations to high-fidelity evaluations.
Integrating Layer Freezing into HPO Workflows
Resource-Constrained HPO
Freezing allows HPO for large models on low-memory hardware, or enables much larger batch sizes for a given GPU configuration:
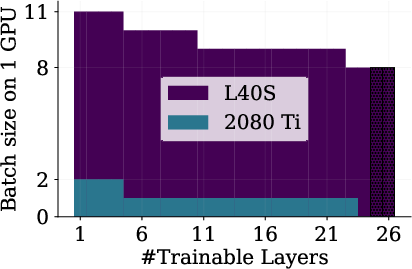
Figure 5: (a) Batch size scaling for 600M GPT-2 using frozen layers; (b) Memory-parallel configuration for SH leveraging frozen layers.
Given the lower VRAM requirements, practitioners can shard high-end GPUs using features like NVIDIA's Multi-Instance GPU (MIG), executing many low-fidelity jobs in parallel, increasing overall HPO throughput, or exploiting pre-emptible cheap cloud instances.
Behavior of Low-Fidelity Proxies
Scatter plots comparing low-fidelity validation results to their full-fidelity counterparts further corroborate high rank preservation even with aggressive freezing:
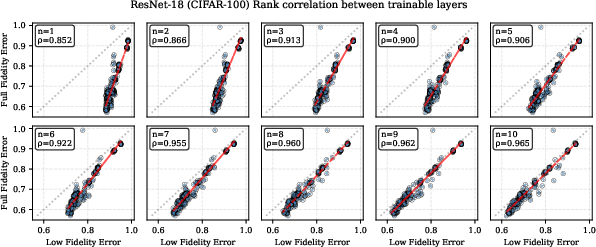
Figure 6: Scatter of low-fidelity validation errors (ResNet-18, CIFAR-100) versus full-fidelity numbers; high rank correlation persists at low fidelity.
Loss trajectories as a function of trainable layers and training steps show strict monotonicity and no evidence of pathological underfitting, confirming the suitability of layer freezing as a control variable:
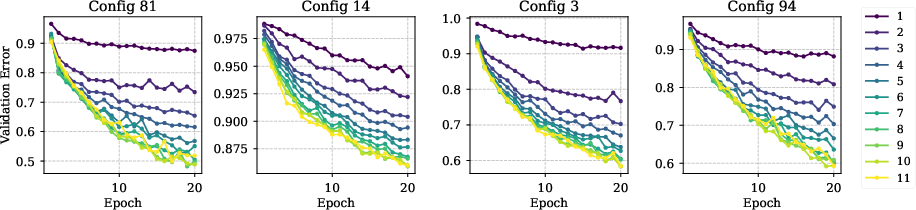
Figure 9: Validation error trajectories for ResNet-18, stratified by number of trainable layers and epochs.
Practical Guidelines and Implementation
- Layer Splitting: For most networks, layers can be split by functional blocks (conv/residual block for CNNs, encoder blocks for Transformers). Embedding and unembedding layers may contribute large parameter counts and should be considered separately.
- Parameter Freezing: In PyTorch, one toggles the requires_grad state on module parameters to specify trainable layers. Custom wrapper code can recursively traverse modules, freezing as needed.
- HPO Integration: Layer freezing can serve as an independent fidelity or be composed with epoch/data-size scheduling, enabling "many-fidelity" HPO. Successive Halving, Hyperband, or multi-fidelity Bayesian optimization methods can utilize this structure efficiently.
- Limitations: Continuation over layer fidelity is nontrivial—i.e., unfreezing additional layers mid-training changes the optimization landscape and interacts nontrivially with learning-rate schedules. For highest efficiency, each fidelity evaluation is trained from scratch unless a custom unfreezing schedule is engineered.
Implications and Future Directions
- Democratizing Model Tuning: The methodology enables HPO for large-scale models in environments previously limited by VRAM or compute, effectively democratizing access to scalable HPO.
- Environmental Impact: By reducing compute and energy requirements for HPO, layer freezing supports more sustainable ML development.
- Algorithm Innovations: Jointly exploring multiple fidelities—including hardware-aware configurations—opens opportunities for new MF-HPO algorithms that explicitly navigate a multidimensional fidelity-resource-performance landscape.
- Benchmark Design: The evidence that frozen-layer fidelities preserve hyperparameter rank even at low cost suggests that future HPO/NAS benchmarks could be constructed to be much cheaper to evaluate, facilitating larger-scale method comparisons.
Conclusion
The introduction of layer freezing as a fidelity axis for HPO constitutes a significant practical advance for resource-constrained deep learning. It enables substantial compute- and memory-savings and maintains strong hyperparameter rank preservation across architectures. This method enables practical “many-fidelity” HPO, facilitates innovation in HPO algorithms tailored to modern hardware landscapes, and makes large-scale optimization feasible for a broader community. Future work should address principled continuation strategies for freezing/unfreezing, the effect of architecture-specific discretization, and in-depth benchmarking for even more diverse DL tasks.

