- The paper proposes an end-to-end fused GPU kernel that integrates FFT, GEMM, and iFFT, reducing kernel launches and global memory overhead.
- The method utilizes shared memory swizzling and in-kernel FFT pruning to eliminate redundant computations, achieving up to 67.5% computational reduction.
- Performance benchmarks on NVIDIA A100 show up to 250% speedup in 1D and significant gains in 2D FNOs, enabling efficient large-scale PDE surrogate modeling.
TurboFNO: Fused FFT-GEMM-iFFT GPU Kernels for Fourier Neural Operators
Introduction
The paper "TurboFNO: High-Performance Fourier Neural Operator with Fused FFT-GEMM-iFFT on GPU" (2504.11681) addresses substantial inefficiencies in existing Fourier Neural Operator (FNO) implementations on GPUs. FNOs are central to PDE surrogate modeling and scientific machine learning, leveraging the spectral domain via the Fast Fourier Transform (FFT) followed by channelwise linear layers (GEMM) and then projecting back to the spatial domain via inverse FFT (iFFT). Standard FNO stacks in frameworks like PyTorch incur severe performance bottlenecks due to multiple kernel launches, redundant global memory transactions, and the lack of architectural optimizations in black-box libraries such as cuFFT and cuBLAS.
TurboFNO advances this landscape by proposing a fully-fused GPU kernel that integrates FFT, frequency truncation, zero-padding, GEMM, and iFFT into a single unit, with native support for FFT-specific optimizations. The work shows that by aligning the memory layout and dataflow of FFT and GEMM, and resolving shared memory bank conflicts, the kernel can drastically reduce memory traffic and intermediate synchronization, leading to substantial performance improvements.
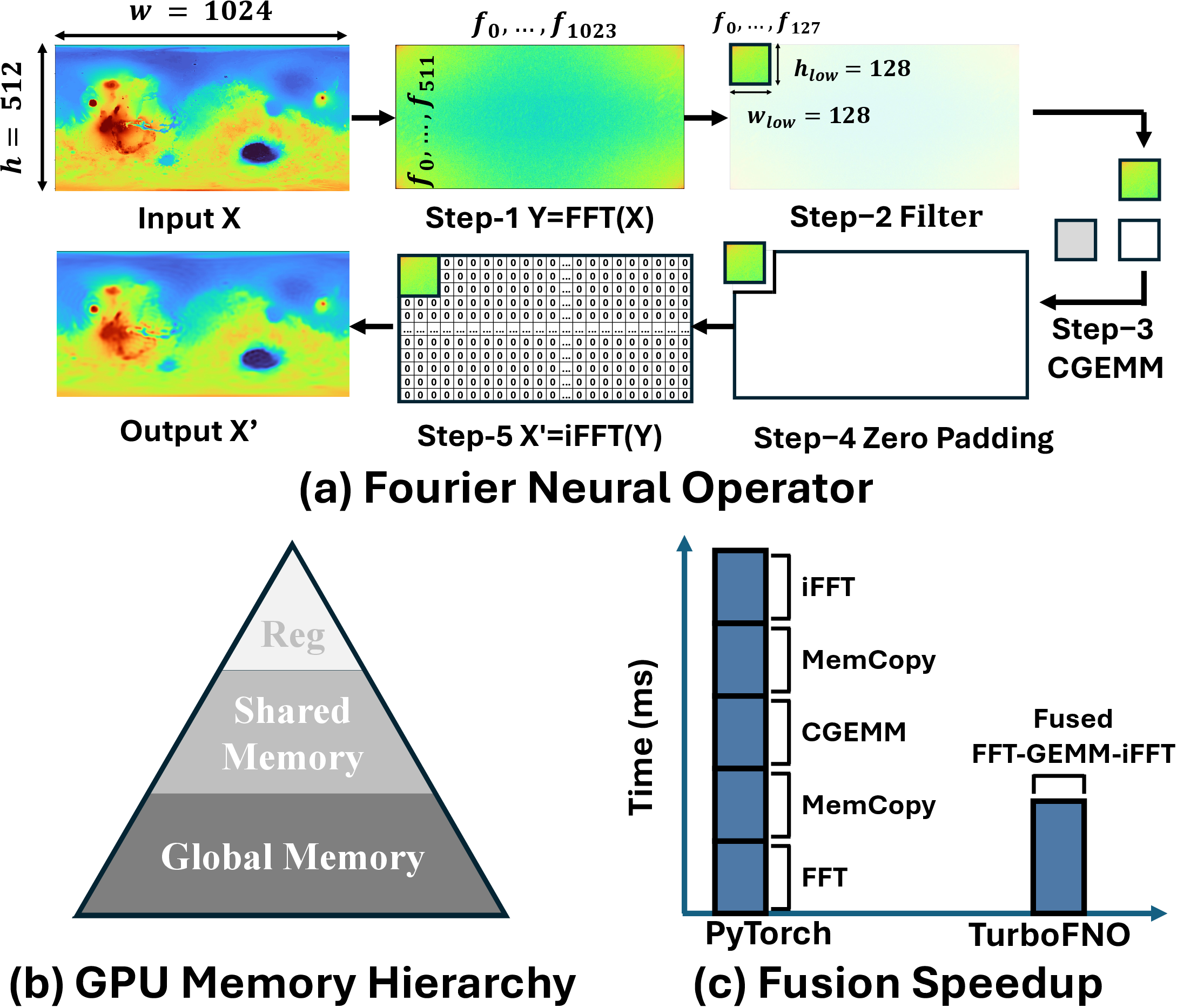
Figure 1: Overview of standard FNO workflow and TurboFNO’s full-kernel fusion approach.
Architectural Innovations
Kernel Fusion of FFT, GEMM, and iFFT
TurboFNO achieves end-to-end fusion of the FFT-GEMM-iFFT computational pattern, which is pervasive in physics-informed neural networks, RT-TDDFT, electronic structure simulation, and signal processing. The fusion is built upon:
- Custom in-place FFT and CGEMM kernels, surpassing the performance of closed-source cuFFT and cuBLAS.
- Integration of FFT-specific features (pruning, built-in truncation, and zero-padding), eliminating redundant butterfly computations and memory copies.
- Dataflow alignment: By restructuring the two-stage batched FFT such that the post-FFT data layout becomes natively compatible with the GEMM's operand A, the kernel leverages batched GEMM’s k-loop parallelism.
As shown in Figure 2, the workflow eliminates all extraneous device memory reads/writes and kernel launches between the three major FNO stages.
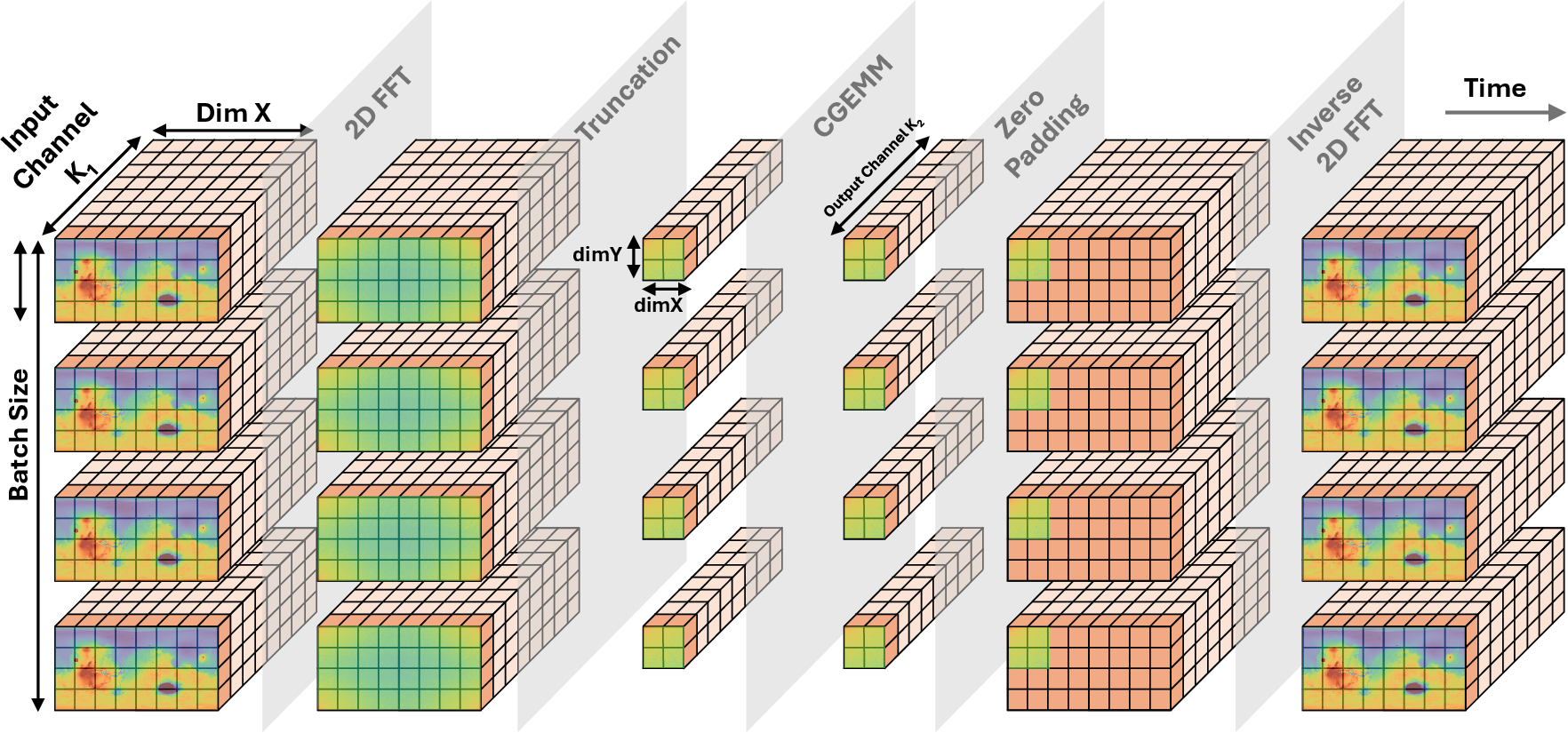
Figure 2: Dataflow through FFT, frequency truncation, GEMM, zero-padding, and iFFT within TurboFNO.
Shared Memory Swizzling and Bank Utilization
A major technical contribution is the shared memory swizzling strategy. Standard FFT and GEMM layouts are mismatched, causing severe shared memory bank conflicts upon kernel fusion. TurboFNO reconstructs the memory access pattern such that:
- FFT writes are reordered so that each bank is accessed by distinct threads in consecutive cycles.
- The output layout is column-major aligned, matching batched CGEMM expectations.
- A similar approach is applied during the epilogue, aligning CGEMM output tiles with iFFT input requirements.
This is illustrated in Figure 3 and Figure 4, where thread-bank assignments before and after swizzling are shown.
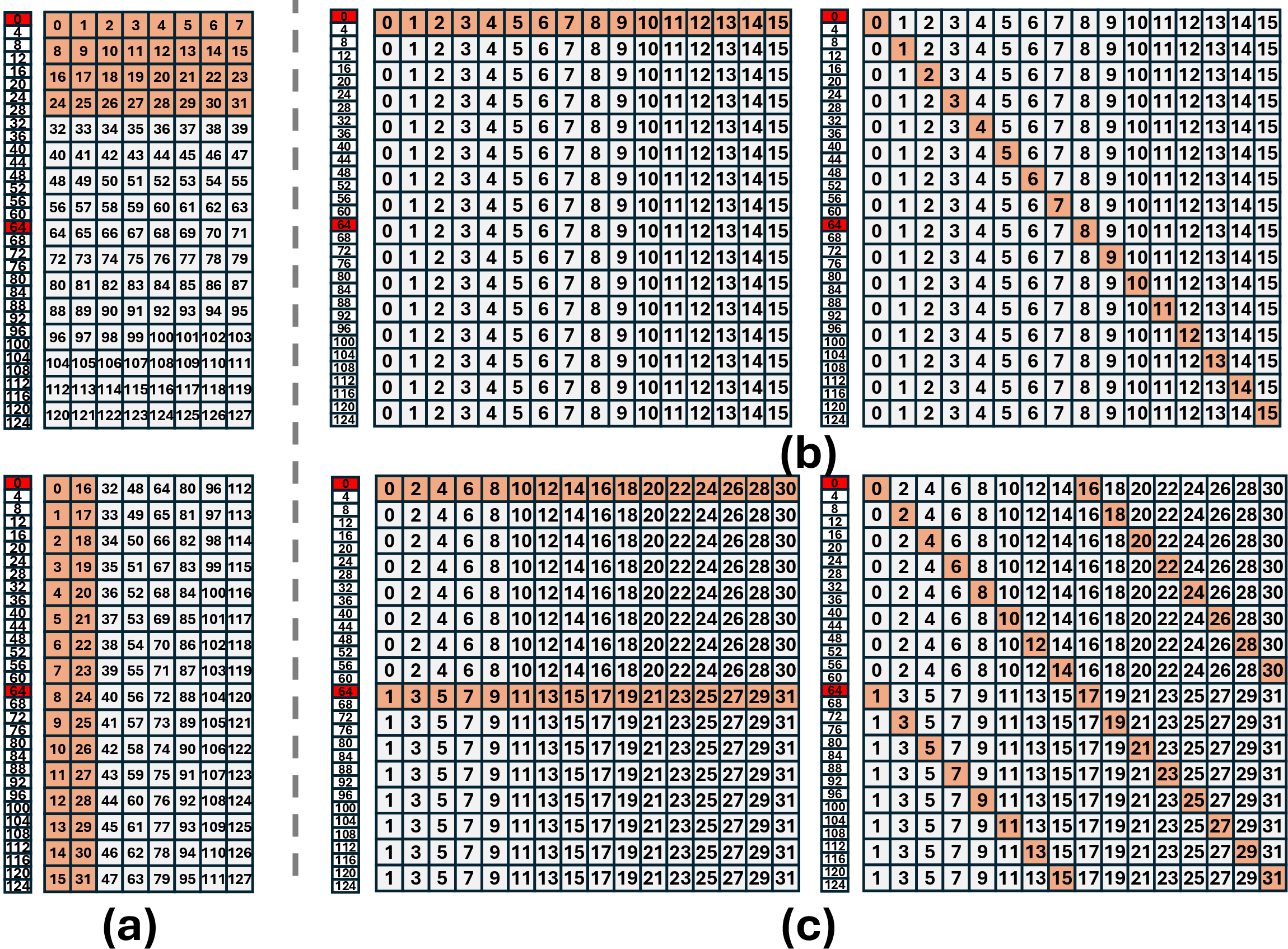
Figure 3: Conflict-free shared memory bank access in FFT-to-GEMM fusion via thread swizzling.
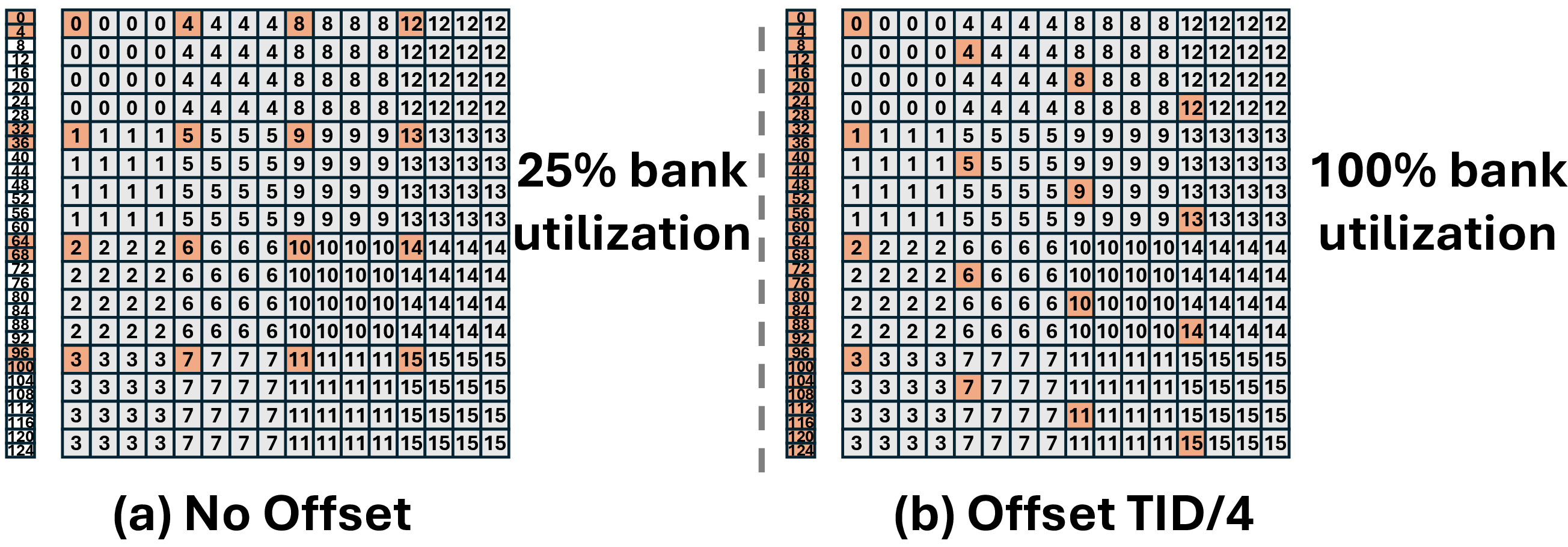
Figure 4: Memory bank alignment for CGEMM output consumption in iFFT.
Truncation and FFT Pruning
Unlike cuFFT, which imposes a fixed FFT size and requires post-processing for frequency windowing, TurboFNO’s in-kernel FFT supports frequency truncation and zero-padding natively, thereby reducing unnecessary global memory operations. Beyond simply reducing I/O, it eliminates redundant butterfly stages for discarded frequencies. The paper provides a quantitative analysis (see Figure 5) showing computational reductions of 25%–67.5% depending on the truncation ratio.
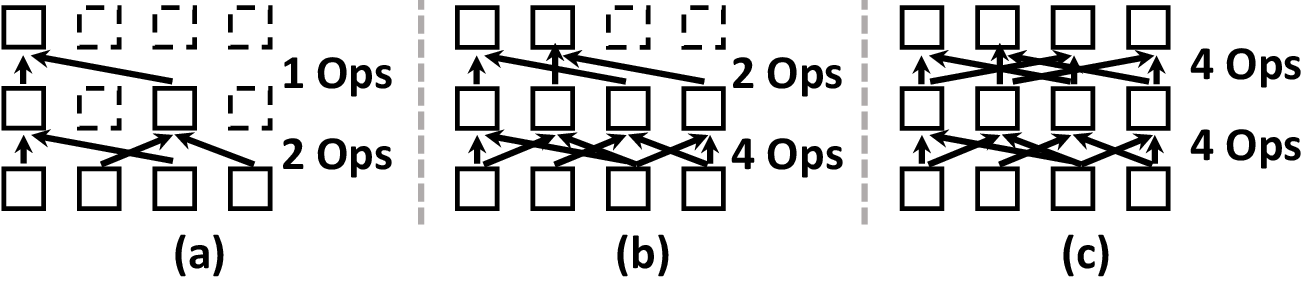
Figure 5: Example of FFT butterfly pruning and remaining operations after frequency truncation.
Implementation Details
CGEMM Kernel Structure
TurboFNO's CGEMM implementation adopts a blocked, templated design for high occupancy and flexibility. The FFT kernel is configured such that each threadblock processes a batch of frequency “pencils” iterating along the hidden dimension, supporting flexible truncation sizes and mapping perfectly to GEMM’s workload.
Fusion Pseudocode
Figure 6 presents the fused kernel pseudocode versus the baseline multi-kernel pipeline, highlighting the elimination of global memory copies and intermediate synchronization barriers.

Figure 6: Pseudocode comparison between baseline and fused FFT-CGEMM-iFFT pipeline.
1D and 2D FNO Benchmarks
On the NVIDIA A100 GPU, TurboFNO is benchmarked against PyTorch implementations using cuBLAS/cuFFT. The results demonstrate:
- In 1D FNO, average speedups of 44% and maxima up to 250% across a variety of batch and hidden dimension configurations (Figure 7).
- In 2D FNO, average gains of 67% with peak speedup of 150% (Figure 8).
- The fully fused kernel consistently delivers higher or equal performance compared to all partial fusion stages (FFT-only, FFT-GEMM, and CGEMM-iFFT).
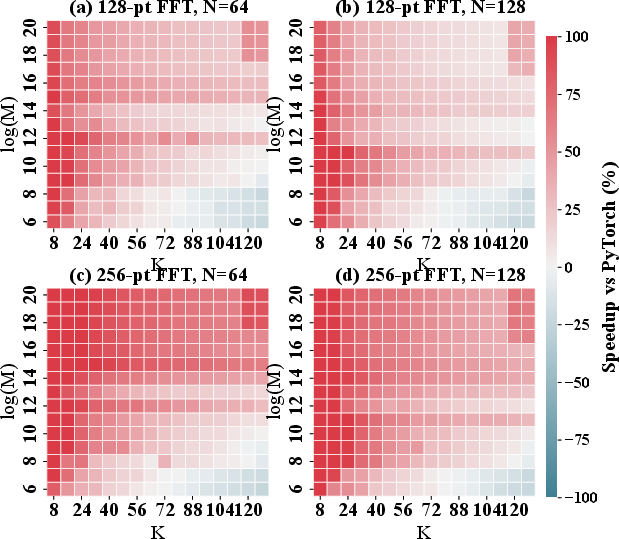
Figure 7: 1D TurboFNO speedup relative to PyTorch versus hidden dimension and batch size.
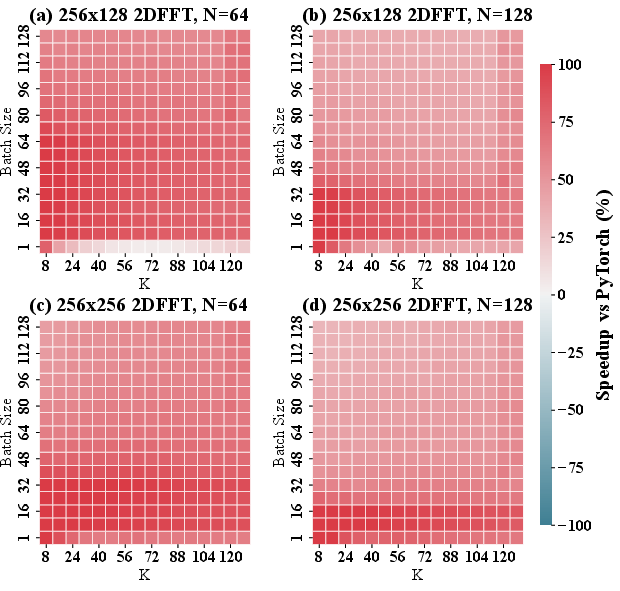
Figure 8: Heatmap of 2D TurboFNO vs. PyTorch, showing robustness of gains across model sizes.
Importantly, the most significant acceleration is observed on large-scale workloads typical in scientific computing, confirming that TurboFNO’s design targets the real-world bottlenecks of high-throughput PDE surrogates and operator learning.
Overhead Reduction Analysis
The elimination of global memory round-trips is quantitatively evidenced. The custom FFT kernel with built-in truncation and pruning accounts for about half of the speedup, while additional fusion primarily benefits large batch scenarios where kernel launch and synchronization overheads become the dominant factors.
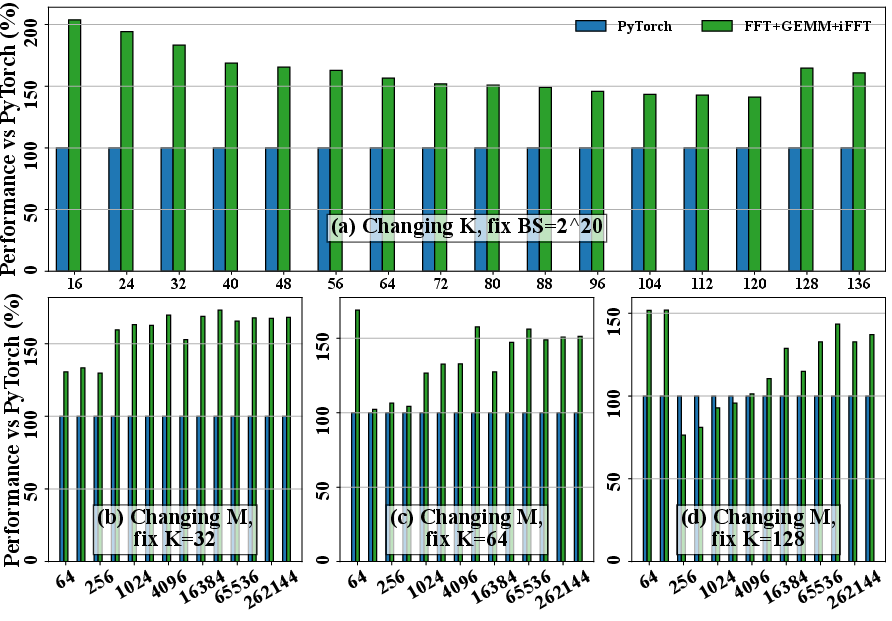
Figure 9: Breakdown of execution time and the effect of 1D FFT optimization strategies.
Implications and Future Directions
TurboFNO constitutes a substantial advancement in neural operator performance optimization, particularly for scientific computing where high arithmetic intensity and large grid sizes stress the memory subsystem of contemporary GPUs. The demonstrated acceleration directly enables training and inference at problem sizes previously untenable without distributed or multi-GPU clusters. Practically, this increases the efficiency and cost-effectiveness of large-scale PDE surrogate modeling in climate, materials science, and turbulence studies.
Theoretically, the demonstrated fusion methodology provides a template for architecture-aware kernel design in future neural operators that embed structured signal transforms. The approach also motivates the inclusion of native spectral truncation and pruning features in future GPU FFT libraries, potentially influencing industry-standard primitives.
Looking forward, further integration with hardware-specific features (e.g., Tensor Cores for CGEMM, asynchronous copy), extension to higher-dimensional FNOs, and adaptation to other spectral operator models (e.g., Chebyshev/Legendre Neural Operators) are clear next steps. The fusion methodology is likely to inspire analogous co-design strategies in other memory-bound operator learning paradigms.
Conclusion
TurboFNO demonstrates that with principled, architecture-aware kernel fusion and shared memory optimization, the canonical FFT-GEMM-iFFT stack in Fourier Neural Operators can be accelerated by up to 150% compared to best-in-class PyTorch pipelines (2504.11681). Its contributions in kernel fusion, memory-bank utilization, and in-FFT pruning collectively set a new standard for high-performance neural operator inference and training. These results underscore the centrality of cross-operator memory layout alignment and in-kernel transformation fusion as primary factors for advancing computation-bound AI workloads on modern GPUs.