- The paper introduces a low-dimensional manifold to reduce the complexity of over-parameterized neural networks in system identification.
- It employs an encoder-decoder architecture that maps datasets directly to the manifold, eliminating costly second-order gradient computations.
- Reduced-order models achieved a 95.2% median fit on the Bouc-Wen benchmark, demonstrating enhanced performance in low-data scenarios.
Introduction
The paper "Manifold meta-learning for reduced-complexity neural system identification" introduces a framework within system identification to tackle the complexity and computational demand of over-parameterized neural networks. These challenges are especially pertinent for modeling systems with uncertain physics via deep learning. The authors propose a meta-learning approach to identify a low-dimensional manifold within the parameter space of these architectures, leveraging datasets generated by related dynamical systems. This manifold enables efficient training while preserving the network’s expressive capacity. The key innovation is an auxiliary neural network that maps datasets directly onto the learned manifold, eliminating costly second-order gradient computations typical in bilevel meta-learning approaches.
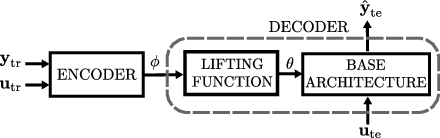
Figure 1: The autoencoder architecture for reduced-complexity architecture learning.
Framework
The framework posits access to a meta-dataset comprising input-output sequences from related dynamical systems. This dataset can originate from high-fidelity simulators or historical experimental data, capturing variability representative of the target system class. A base architecture, sufficiently expressive to encapsulate these dynamics, is defined over the parameter space. However, this architecture is inherently over-parameterized.
A manifold is meta-learned within this parameter space using a mapping function. This allows the base architecture, constrained to the manifold parameters, to describe all systems in the class efficiently. The approach shifts from model-agnostic initialization strategies (as seen in MAML) to direct manifold learning, aligning closer with learning inductive biases for system identification.
The paper utilizes an encoder-decoder architecture to sidestep the complexity of bilevel optimization. The encoder Eψ replaces the inner optimization routine by directly mapping datasets to reduced parameters, which are then lifted to the full-order space via the parametric manifold. This setup circumvents gradient-based inner loops, focusing on minimizing the loss function J~(γ,ψ) approximated by Monte Carlo sampling.
The encoder-decoder architecture conceptually aligns with hyper-network strategies, wherein an auxiliary network provides parameters for another neural network. Meta-learning aims to discover an optimal manifold that reduces modeling complexity over all datasets in the meta-dataset, fostering computational efficiency and mitigating overfitting risks in system identification.
Numerical Illustration
The framework exhibited strong numerical results on the Bouc-Wen benchmark—a nonlinear system identification task. The methodology involved training reduced-order models across varying sequence lengths. Full-order models showed inefficiencies in low-data scenarios, as illustrated by median fit improvements for reduced-order models (Figure 2).
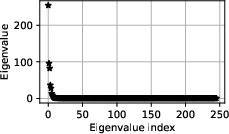
Figure 3: Eigenvalues of the Hessian of the full-order training loss.
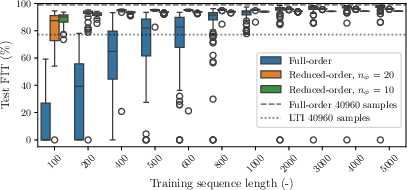
Figure 2: Full and reduced-order models: test FIT vs. training sequence length L.
Reduced-order models demonstrated heightened performance with shortened training sequences, underscoring the benefits of meta-learned manifolds in scarce data environments. Training across L=500 samples achieved a median fit of 95.2%, while full-order configurations faltered under similar constraints.
The reduced training times and avoidance of numerical instability in the optimization process affirmed the reliability and efficacy of manifold-based model training (Figure 4).
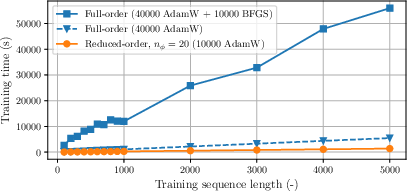
Figure 4: Training time vs. training sequence length L.
Conclusion
The manifold meta-learning framework provides an elegant solution to the challenges posed by over-parameterized neural networks in system identification. It effectively balances expressiveness with computational tractability, as evidenced by its impactful performance in the Bouc-Wen benchmark context.
Prospects for future developments include hybrid models incorporating known physics, variational approaches for probabilistic modeling, and adaptations suitable for real-world data domains. Integrating domain knowledge into the meta-learning process could further refine model structures, encouraging robust system identification in increasingly complex applications.