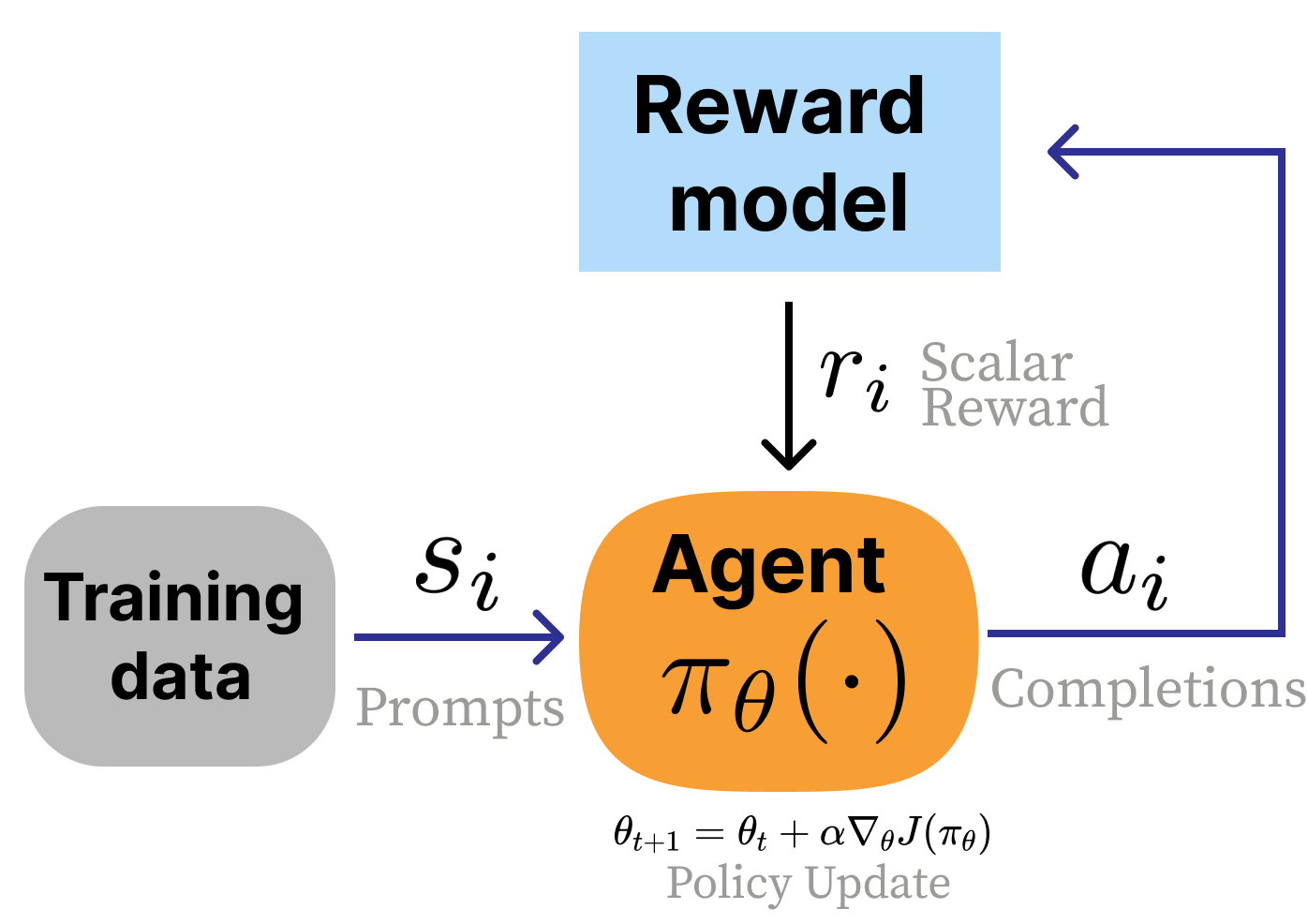
- The paper introduces a three-stage RLHF process combining supervised fine-tuning, reward modeling, and policy gradient optimization.
- It demonstrates how leveraging human judgments can align AI model outputs with human values and improve task performance.
- The work highlights challenges such as overfitting, resource intensity, and reward calibration, guiding future research directions.
Reinforcement Learning from Human Feedback (RLHF)
Reinforcement Learning from Human Feedback (RLHF) is a technique that integrates human feedback into the reinforcement learning (RL) process to guide the training of machine learning models, particularly LLMs. The essence of RLHF lies in its ability to leverage human judgement to refine and align the performance of AI systems with human expectations, making them not only capable of solving complex tasks but also aligning with human values and preferences.
Overview of RLHF Process
The RLHF pipeline typically follows a three-stage procedure:
- Supervised Fine-Tuning (SFT): Initialization of the model with example-driven training. This stage aims to teach the model to follow instructions by exposing it to a vast set of labeled examples. This step is crucial for establishing a baseline model capable of understanding and generating responses relative to human preferences.
- Reward Model Training: Developing a reward model to represent human preferences accurately. Human annotators provide feedback on model outputs, which is then used to train the reward model. The reward model acts as a proxy for human judgement in evaluating new outputs.
- Reinforcement Learning Optimization: The final model is optimized with policy gradient methods, where the reward model is used to guide the learning process. This stage involves sampling model outputs, scoring them with the reward model, and updating the model to improve future outputs.
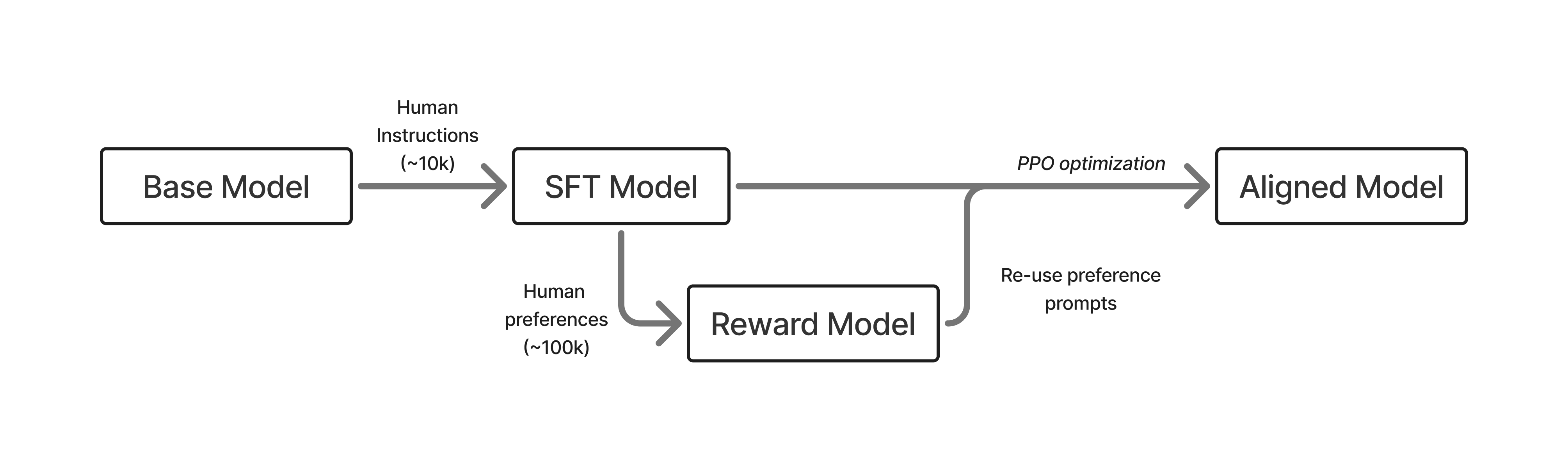
Figure 1: A rendition of the early, three stage RLHF process with SFT, a reward model, and then optimization.
Key Components and Challenges
- Reward Models:
- Training: The core of an effective RLHF application is a robust reward model. This model uses paired comparisons of outputs provided by human annotators to discern preferences.
- Challenges: Capturing nuanced human preferences is challenging due to the inherent subjectivity and potential inconsistency in human evaluations.
- Optimization Challenges:
- Overfitting and Over-Optimization: A major challenge is avoiding over-optimization of the reward model, where the model begins to exploit weaknesses in the reward model rather than learning genuine improvement strategies.
- Calibration of Rewards: Ensuring that the rewards reflect true human preferences requires careful calibration, often necessitating iterative testing and feedback.
Practical Implementation
RLHF can be practically implemented with a series of steps and technological frameworks:
Several trade-offs exist within the RLHF framework:
- Complexity vs. Generalization: While RLHF aims to generalize well by aligning with human intentions, it must be cautious of increasing model complexity which might lead to unintended behaviors.
- Resource Intensity: RLHF is resource-intensive, requiring substantial computational power and human input. The balance between resource expenditure and model performance improvement is a key consideration.
- Scalability: Scaling RLHF to very large model architectures and datasets demands efficient algorithms and effective parallel training strategies.
Future Directions
The future of RLHF involves:
- Exploration of Diverse Applications: Extending RLHF principles from LLMs to other domains like robotics, autonomous vehicles, and interactive AI systems to address diverse societal needs.
- Development of Advanced Metrics: Creating robust metrics for better evaluating model alignment with human expectations, beyond the scope of existing reward models.
- Integration of Ethical Considerations: Establishing ethical guidelines to govern how RLHF systems are trained and applied, considering potential biases and the scope of human control over intelligent systems.
Conclusion
RLHF represents a pivotal step toward harmonizing AI capabilities with human values, significantly enhancing the ability of models to perform in alignment with desired objectives. Its future lies in refining reward systems, enhancing model robustness, and broadening its application across various domains, ensuring AI’s utility is maximized while being responsibly managed.