- The paper introduces a hybrid algorithm that integrates spiking neural networks with Kalman filtering to learn optimal gain matrices, reducing dependency on explicit noise statistics.
- It employs reward-modulated STDP and teacher-forced training to ensure rapid convergence and superior state estimation in both linear and nonlinear systems.
- Empirical results demonstrate a 15–65% error reduction across tasks, highlighting its effectiveness in real-world applications like UAV trajectory tracking.
Spike-Kal: Integrating Spiking Neural Networks with Kalman Filtering
Introduction
Spike-Kal presents a hybrid estimation algorithm that leverages Spiking Neural Networks (SNNs) to optimize the gain computation stage within the canonical Kalman Filter (KF) framework. This approach is motivated by two central limitations in classical KFs: reliance on accurate system/noise models and the computational burden associated with matrix operations in high-dimensional scenarios. The SNN module is trained to directly infer the optimal gain matrix from observations, thereby reducing dependency on explicit noise statistics and potentially improving both computational efficiency and adaptivity to time-varying noise statistics.
Methodological Framework
Spike-Kal operates by embedding a two-layer fully-connected SNN within the traditional prediction-correction structure of the Kalman filter. In this design, the SNN substitutes the analytical step of gain calculation with a learned mapping from error-like features (Δx and Δy) to the gain matrix K. The transformation from traditional continuous values to and from spike representations is handled by encoder and decoder interfaces, ensuring compatibility between mature KF modules and the event-based processing of SNNs. The workflow is visualized in the system block diagram (Figure 1).
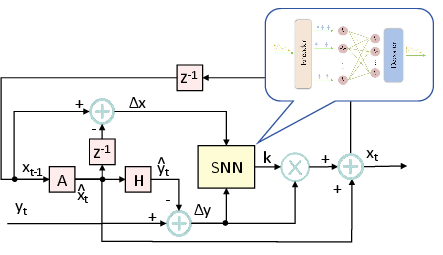
Figure 1: Spike-Kal block diagram illustrating the integration of SNN for gain calculation within the Kalman filter pipeline.
The SNN core is trained using a reward-modulated STDP (R-STDP) mechanism. The R-STDP exploits a teacher-forced regime early in training, where ground truth gain matrices computed via standard KF equations are provided as reward signals. This ensures convergence and avoids divergence during startup. Once training stabilizes, the SNN autonomously produces estimation gains.
The SNN architecture is detailed in Figure 2.
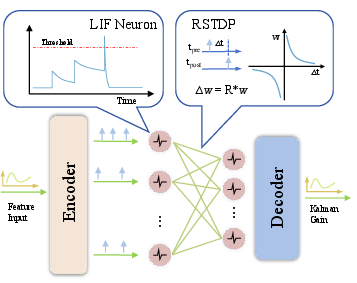
Figure 2: SNN architecture for gain estimation and the reward-modulated spike-timing-dependent plasticity learning rule.
Empirical Validation
Spike-Kal is systematically evaluated on three representative tasks: linear motion state estimation, nonlinear Lorenz system identification, and real-world UAV trajectory tracking. In all settings, mean absolute error (MAE) and mean squared error (MSE) metrics are reported, with ground truth trajectories available for reference.
Linear Motion Filtering
For linear systems, position and velocity in two orthogonal directions are estimated from noisy sensor inputs. Spike-Kal exhibits comparable or reduced error in velocity estimation relative to traditional KF and SNN-based alternatives. For position, Spike-Kal achieves a 15–60% reduction in estimation error compared to its peers (Figure 3).
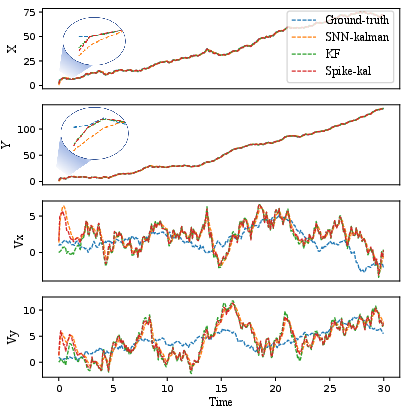
Figure 3: Comparison of reconstruction on a linear motion system; Spike-Kal demonstrates superior position estimation fidelity, particularly in early convergence.
Chaotic Nonlinear Lorenz System
Spike-Kal generalizes to highly nonlinear dynamics, as evidenced in the Lorenz attractor experiments. Only partial observations are available, necessitating challenging state recovery. Despite these difficulties, Spike-Kal achieves rapid convergence comparable to Extended Kalman Filter (EKF) and demonstrates an 18–65% MSE reduction across unobserved and observed states. Conventional SNN Kalman approaches converge more slowly and yield larger errors (Figure 4).
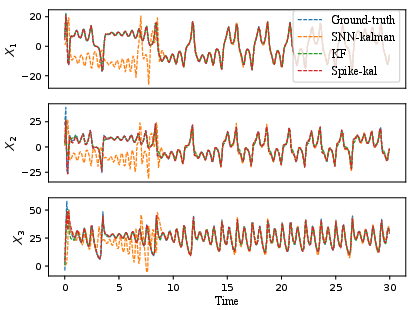
Figure 4: State estimation on the Lorenz system, showing that Spike-Kal closely tracks ground truth, outperforming EKF and SNN Kalman baselines in MSE and convergence.
Real-World UAV Trajectory Tracking
Spike-Kal is deployed on a neuromorphic processor and evaluated for real-time UAV state estimation. Position errors are reduced by 7–20% (horizontal) and 30–35% (vertical) relative to standard KF and SNN Kalman methods under partial/corrupted observation scenarios (Figure 5).
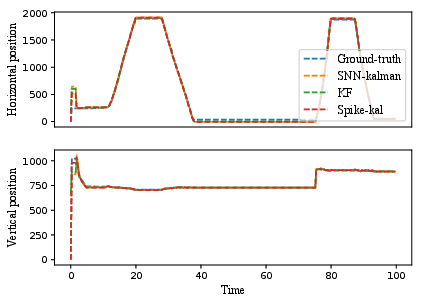
Figure 5: UAV trajectory tracking results, with Spike-Kal producing reconstructions closely adhering to manual ground truth annotations.
Numerical and Algorithmic Claims
The strongest empirical results reported are:
- Error reduction of 18–65% in filtering scenarios compared to classical and prior SNN-based Kalman approaches, especially in nonlinear systems and “partial model” conditions.
- Efficient SNN deployment: A marked decrease in SNN neuron count (7–14) versus competing SNN Kalman implementations (14–28), while maintaining or improving performance.
- Rapid convergence: Teacher-model-guided R-STDP enables the SNN to avoid the slow, unstable training observed in earlier SNN Kalman filters.
Practical and Theoretical Implications
Spike-Kal provides a template for neuromorphic, adaptive filtering architectures where a significant portion of the estimation pipeline is offloaded to energy-efficient, event-based hardware. The approach is particularly compelling for embedded or edge applications subject to time-varying noise profiles, uncertain models, and resource constraints (e.g., real-time robotic navigation or control). By demonstrating competitive or superior accuracy without explicit access to full noise statistics, Spike-Kal evidences the growing relevance of bio-inspired learning procedures (e.g., R-STDP) for control and state estimation.
On the theoretical level, the work demonstrates that even a modest SNN can internalize the computation of Kalman gain matrices in both linear and nonlinear settings, as long as the system is structured with appropriate error features and supervised by teacher-forced strategies initially. This contributes to the ongoing discourse regarding the utility of SNNs for continuous-time state estimation and filtering, especially in non-Gaussian, adaptive, or non-stationary environments.
Future Prospects for Neuromorphic Filtering
Future developments may extend the Spike-Kal paradigm to broader families of sequential Bayesian estimation (e.g., Unscented, Particle, or Ensemble KFs), hierarchical systems, or integrate fully spiking end-to-end representation and control. Distributed sensor fusion and asynchronous, event-driven robotic perception also present natural arenas for this class of hybrid neuromorphic algorithms.
Conclusion
Spike-Kal demonstrates that SNNs, equipped with R-STDP and teacher-initialized gain inference, can significantly improve both the accuracy and adaptivity of Kalman filtering in real-world, nonlinear, and uncertain noise environments. The hybrid architecture bridges conventional model-based estimation with neuromorphic, data-driven adaptation. The results indicate tangible performance gains and a clear pathway for further research at the intersection of biological learning rules, neuromorphic hardware, and statistical filtering.