- The paper introduces CHBC, a new framework integrating multi-granularity feature enhancement with cross-hierarchical bidirectional consistency for improved FGVC.
- It employs orthogonal decomposition in MGE modules and a global CBC loss to align predictions across all hierarchy levels.
- Experimental results show 2–3% accuracy gains and higher consistency rates on benchmarks like CUB-200-2011 and FGVC-Aircraft.
Cross-Hierarchical Bidirectional Consistency Learning for Fine-Grained Visual Classification
Introduction and Motivation
Fine-Grained Visual Classification (FGVC) presents unique challenges due to intrinsic minimal inter-class differences and significant intra-class variance, particularly at finer granularities. Models may extract only subtle discriminative patterns that delineate subcategories, such as nuanced differences within bird species. Conventional approaches often require extensive manual annotations or focus narrowly on the finest-grained labels, limiting practical deployment and generalization. These methods also neglect leveraging the implicit hierarchical relationships present in label taxonomies, resulting in inconsistent and occasionally logically invalid multi-level predictions.
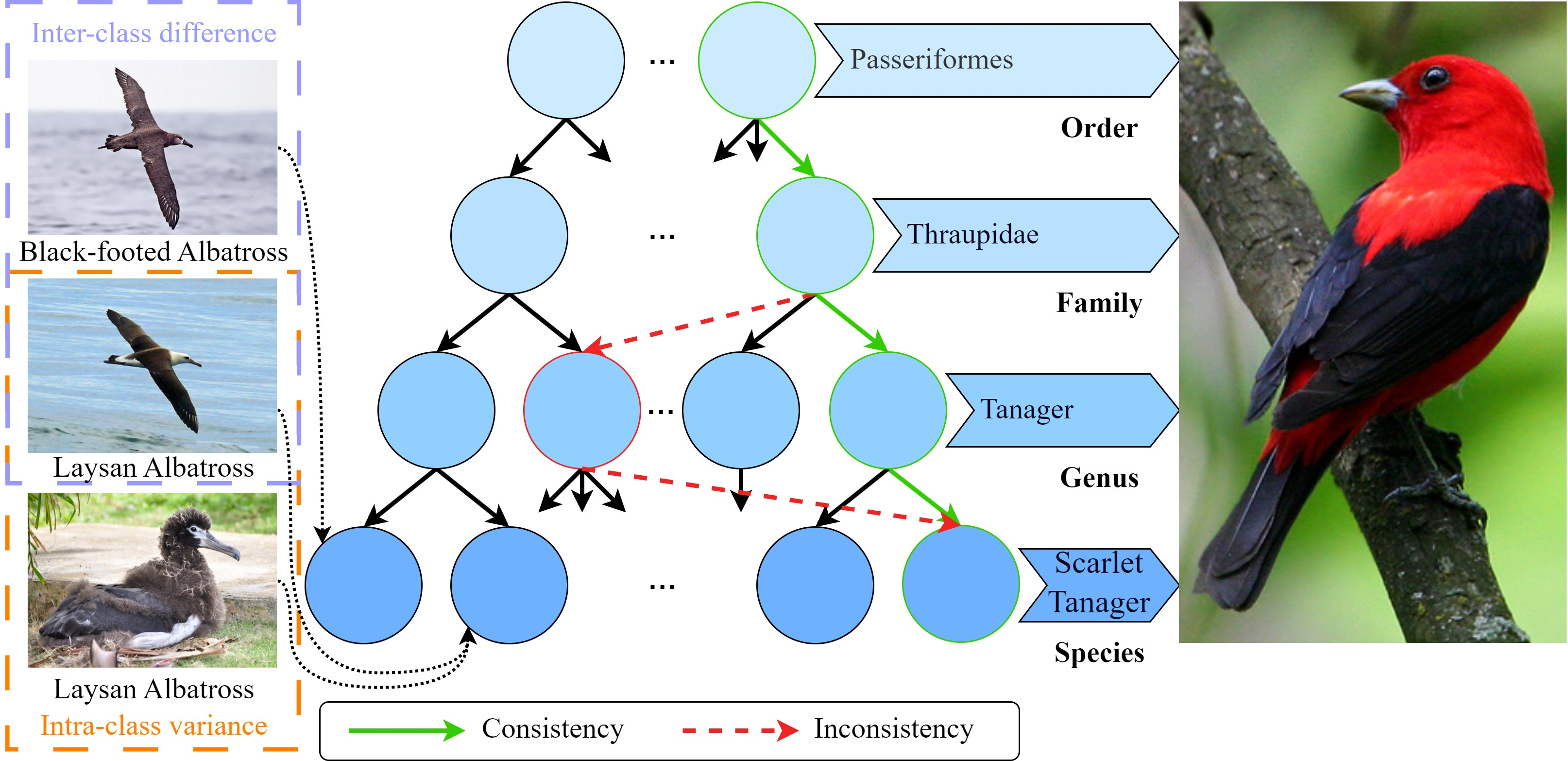
Figure 1: Visualized tree hierarchies: green arrows indicate predictions consistent across hierarchy; red arrows highlight inconsistencies, underscoring the challenge of maintaining cross-hierarchical coherence.
Recent literature proposes training a single model to predict labels at multiple taxonomic levels, but consistency constraints between these levels are commonly under-explored or only enforced locally (e.g., between immediate parent-child pairs). The proposed Cross-Hierarchical Bidirectional Consistency Learning (CHBC) addresses these limitations; it integrates all available hierarchy-level labels in prediction, systematically propagating and enforcing bidirectional consistency constraints across the entire tree.
Framework Overview: CHBC Architecture
CHBC is architected around four principal components: a trunk network for global feature extraction, a branch network with Multi Granularity Enhancement (MGE) modules, hierarchy-specific classifiers, and a composite loss function combining standard cross-entropy with a cross-hierarchical bidirectional consistency loss. The workflow follows:
- Feature Extraction: The trunk network (e.g., ResNet-50 backbone) extracts shared features from input imagery.
- Multi-Granularity Enhancement (MGE): Features are diversified by h parallel MGE modules; each specializes in extracting discriminative attention and representations relevant to a specific hierarchy level, using orthogonal decomposition to maximize inter-level distinctiveness.
- Hierarchical Prediction: Each hierarchy-specific classifier operates on MGE-enhanced features to predict the corresponding label, from coarse (e.g., order) to fine (e.g., species).
- Cross-Hierarchical Bidirectional Consistency (CBC): A consistency constraint module aligns the probability distributions of predictions across all hierarchical levels, both top-down and bottom-up, by optimally unifying the distributions according to the tree’s structure. The final loss aggregates cross-entropy (per-level) and the global CBC loss.
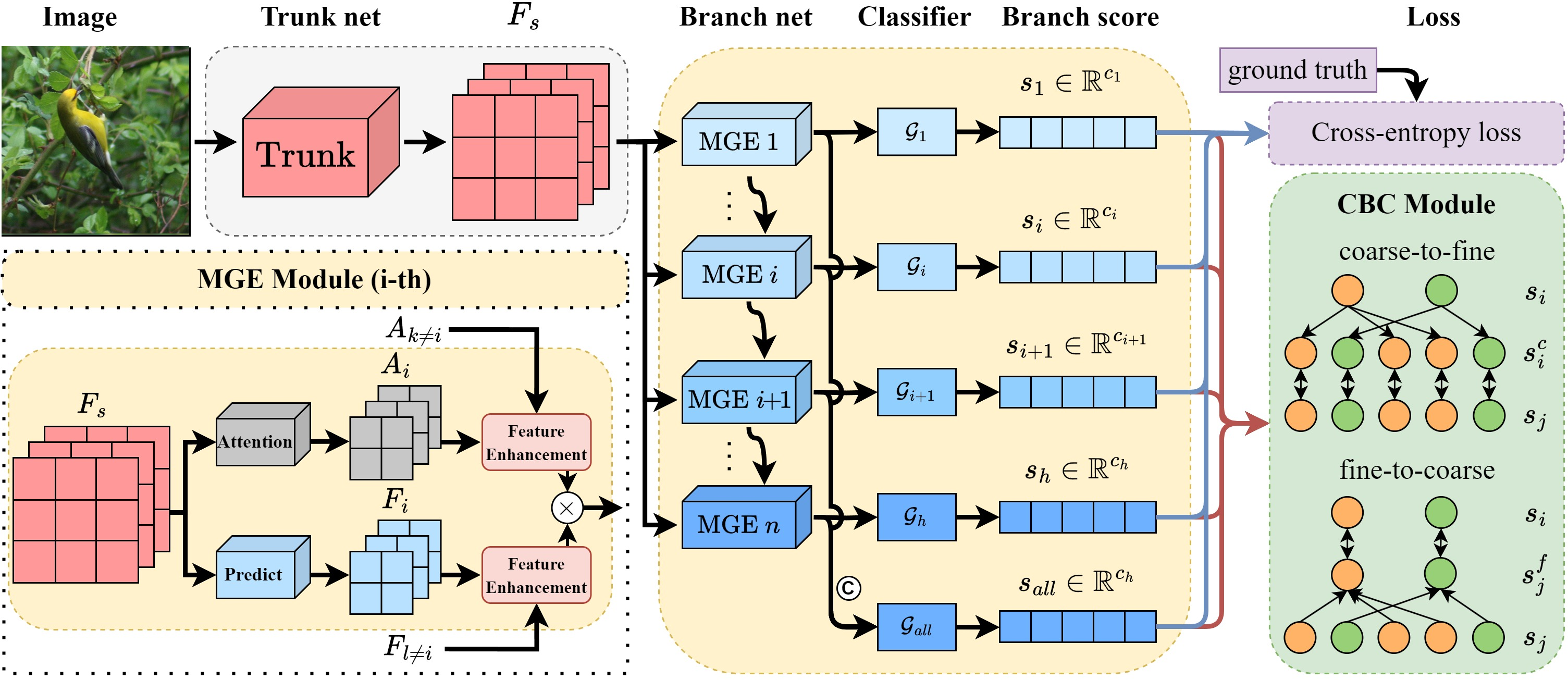
Figure 2: CHBC schematic—shared trunk, parallel MGE modules for each hierarchy, and combined consistency and classification losses.
Multi-Granularity Feature Enhancement
Existing FGVC pipelines frequently co-mingle features for all hierarchies, sacrificing level specificity. CHBC implements per-level MGEs, each of which decomposes the shared trunk features into attention masks and features specific to its designated granularity. These submodules employ orthogonal decomposition: for each level, the part of the feature/attention informative for finer classification is explicitly made orthogonal to representations at coarser levels, thus increasing discriminative capacity.
This orthogonality constraint, applied to both feature tensors and attention maps, facilitates direct disentangling of semantically similar but class-defining cues. For instance, by decomposing and recombining attention features at the family and species level, CHBC preserves elements critical for subordinate discrimination without “leakage” from ancestral, less-specific features.
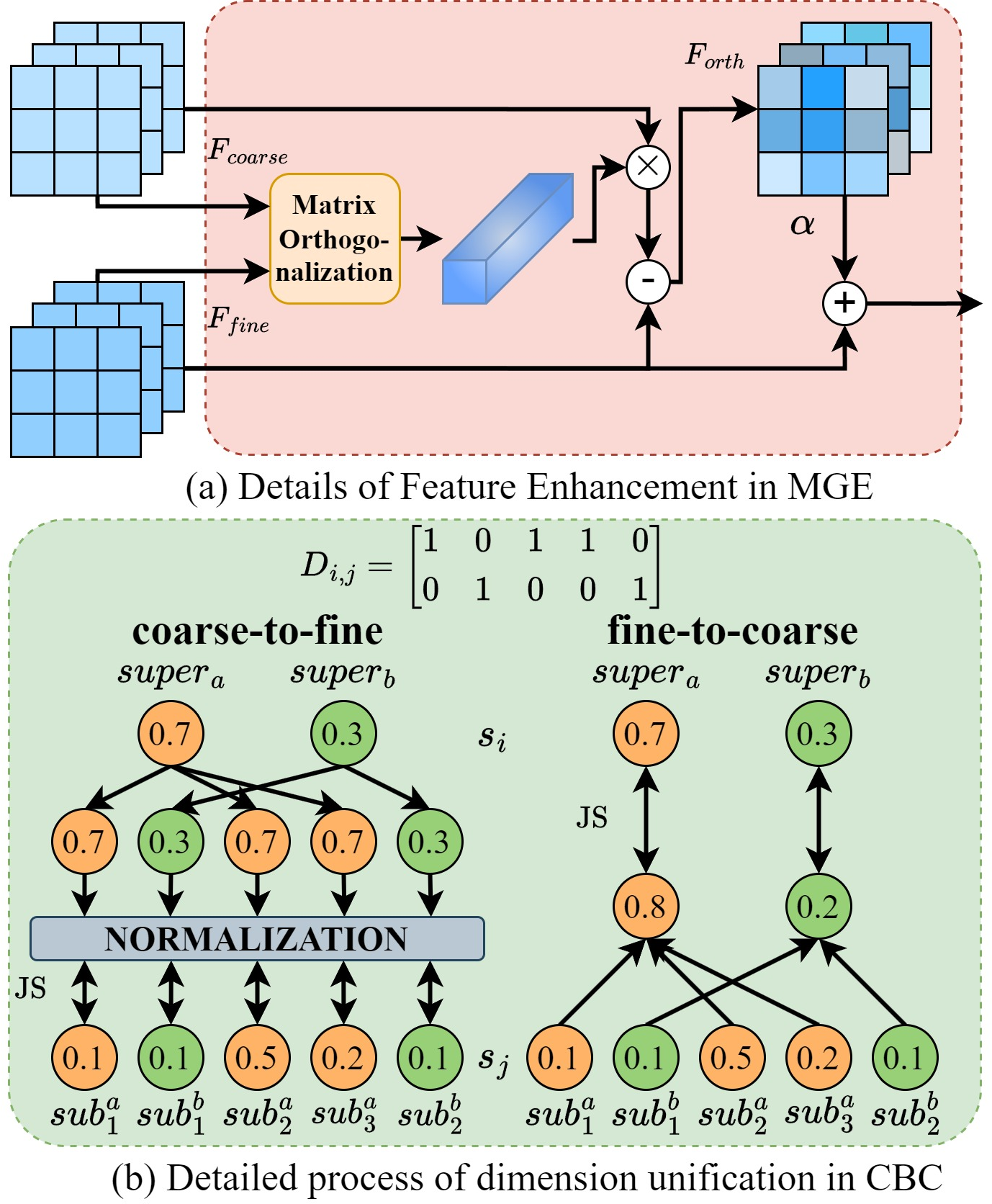
Figure 3: (a) Orthogonal decomposition details in MGE; (b) CBC unifies hierarchical probability distributions for joint optimization.
Cross-Hierarchical Bidirectional Consistency
A major innovation in CHBC is the Cross-hierarchical Bidirectional Consistency (CBC) module which enforces semantically valid predictions across all levels of the label tree hierarchy. By constructing an adjacency matrix for the hierarchy, CBC enables probability mass to be consistently “pushed” downward (coarse-to-fine) or “pulled” upward (fine-to-coarse) in a principled manner.
The bidirectional strategy contrasts with one-way regularization in prior works—here, the output at any hierarchy is regularized against aggregate evidence propagated from both parent and children nodes, using Jensen-Shannon divergence for symmetric distribution alignment. This ensures that, for example, when a superclass (order) is predicted confidently, its subclasses (family, genus, species) will reflect that certainty via increased subclass probabilities, and vice versa.
Ablations confirm that all-to-all consistency enforcement (every level interacts with all others) outperforms local or finest-only constraints, substantiating the necessity of global cross-hierarchical integration.
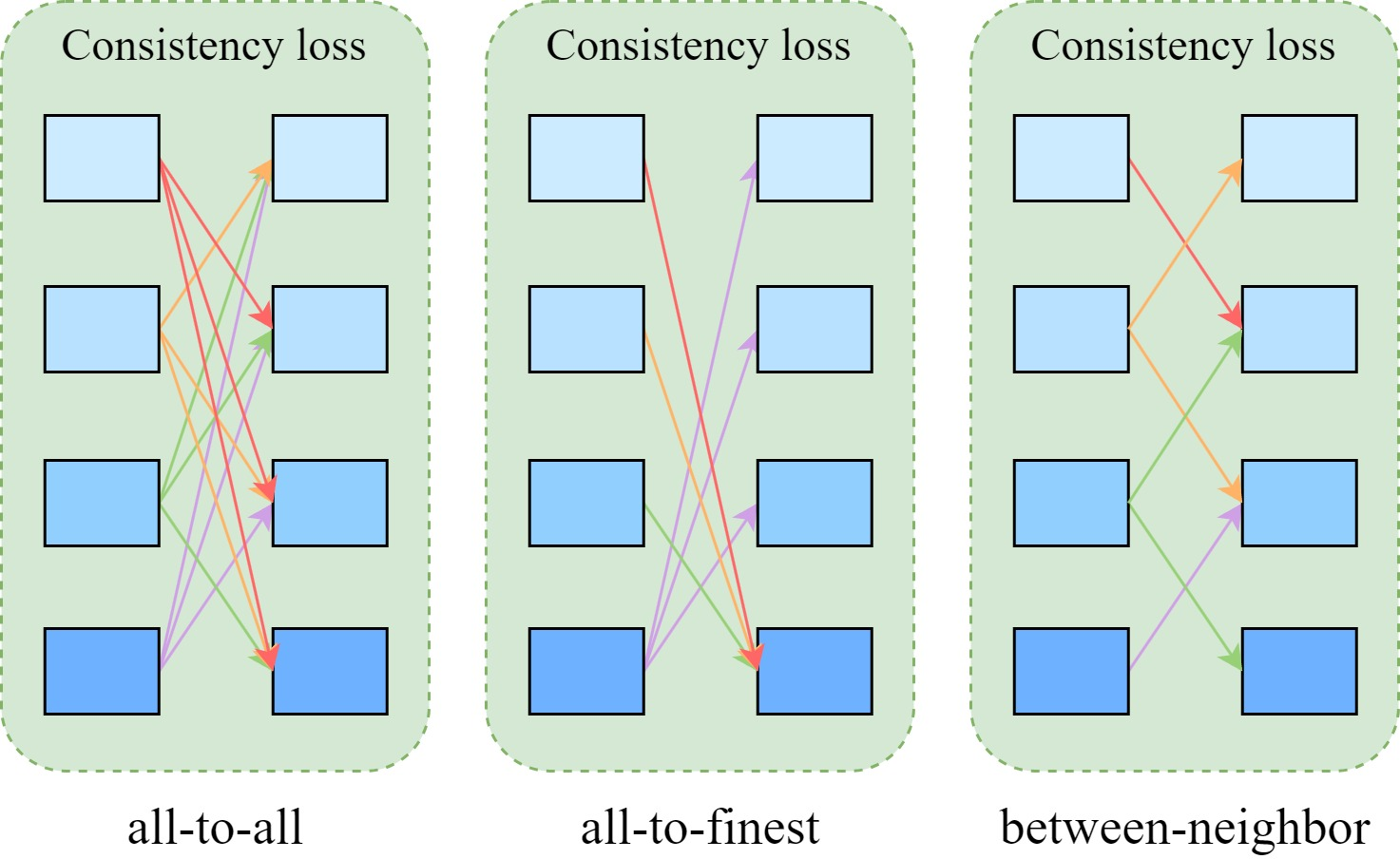
Figure 4: Consistency enforcement strategies—ablation reveals that all-to-all (global) interaction yields best multi-level consistency and accuracy.
Experimental Results
The efficacy of CHBC was validated on three canonical FGVC datasets: CUB-200-2011 (birds), FGVC-Aircraft, and Stanford Cars. The label trees for each were constructed to enable multi-level evaluation.
Key empirical findings:
- Finer-level accuracy: CHBC surpasses previous multi-level models (e.g., HRN, CAFL, HCSL, HSE) at the species/model level by 2–3% absolute accuracy across all benchmarks.
- Weighted average accuracy (wa_acc): On CUB-200-2011, CHBC posts a 90.4% wa_acc, exceeding all published baselines, with similar dominance on FGVC-Aircraft and Stanford Cars.
- Consistency (TCR): The Tree-based Consistency Rate of CHBC is systematically higher, indicating not only high accuracy but also logically coherent hierarchical predictions.
- Top-n classification: CHBC delivers substantial improvements in top-3/5 accuracy over competitors, demonstrating enhanced reliability on ambiguous samples due to better calibrated distribution consistency.
Further, ablation studies confirm significant contributions from both the MGE (disentangling multi-level features) and CBC (global consistency) modules, with the all-to-all CBC interaction and Jensen-Shannon divergence yielding optimal results.
Visualization of feature attentions and probability distributions indicates that CHBC not only focuses attention more tightly on class-defining regions but also produces classification scores with more plausible, consistent hierarchical decomposition.
Implications and Future Directions
CHBC establishes a new state-of-the-art for multi-level hierarchical FGVC by:
- Eliminating the need for additional expert annotations beyond the label taxonomy.
- Delivering label predictions at any hierarchy depth, enabling adaptation to domain expert, amateur, or application-specific needs.
- Enforcing strong logical constraints that minimize both coarse errors and “invalid” class assignments (i.e., those that violate tree ancestry).
Practically, CHBC supports reliability and transparency in computer vision systems deployed in domains where taxonomic consistency is essential, such as biodiversity monitoring or fine-grained industrial anomaly detection. Theoretically, it offers a template for structured knowledge propagation in multi-label settings, extendable to graph-based label structures beyond trees.
Looking forward, extending CHBC to handle dynamically evolving label hierarchies, integrating semi-supervised or transfer learning paradigms, and generalizing to large-scale, heterogeneous taxonomies are promising research avenues.
Conclusion
This work introduces the CHBC framework—a methodologically rigorous and empirically validated approach for FGVC with hierarchical labels. By combining multi-granularity feature extraction and cross-hierarchical bidirectional consistency constraints, CHBC advances both the accuracy and cross-level coherence of visual classifiers without recourse to manual part annotation or bespoke labeling. The architecture and principles proposed support further research into consistency-aware structured prediction in machine perception domains.