- The paper introduces MoE Parallel Folding, a novel methodology that decouples parallelization mappings for Attention and MoE layers to significantly enhance training efficiency.
- A sophisticated token dispatcher is presented to manage complex token routing in both token-dropping and token-dropless paradigms, ensuring optimal data distribution.
- Experimental results show up to 49.3% MFU and scalable performance across 1,024 GPUs, highlighting the framework's potential to improve large-scale MoE model training.
MoE Parallel Folding: Efficiency in Large-Scale MoE Model Training
The paper "MoE Parallel Folding: Heterogeneous Parallelism Mappings for Efficient Large-Scale MoE Model Training with Megatron Core" (2504.14960) presents an innovative framework for enhancing the efficiency of training large-scale Mixture of Experts (MoE) models. By addressing challenges in distributed training and optimizing computational resource utilization, this study significantly improves training effectiveness for massive MoE architectures.
Introduction to MoE Models
Mixture of Experts (MoE) models are characterized by their ability to dynamically select relevant sub-networks (experts) for processing specific input tokens, thereby enhancing scalability while keeping computational costs manageable. Recent advancements have scaled MoE models to trillions of parameters, demonstrating state-of-the-art performance across various domains. However, these models impose significant demands on training frameworks, necessitating efficient parallelism strategies to leverage thousands of GPUs effectively.
Framework Innovations
MoE Parallel Folding
One of the paper's core contributions is MoE Parallel Folding, a novel strategy that separates parallelization mappings for Attention and MoE layers in Transformer models. This separation allows for tailored parallel configurations suited to the distinct computational characteristics of each layer type, particularly enhancing the flexibility and efficiency of communication-intensive components.
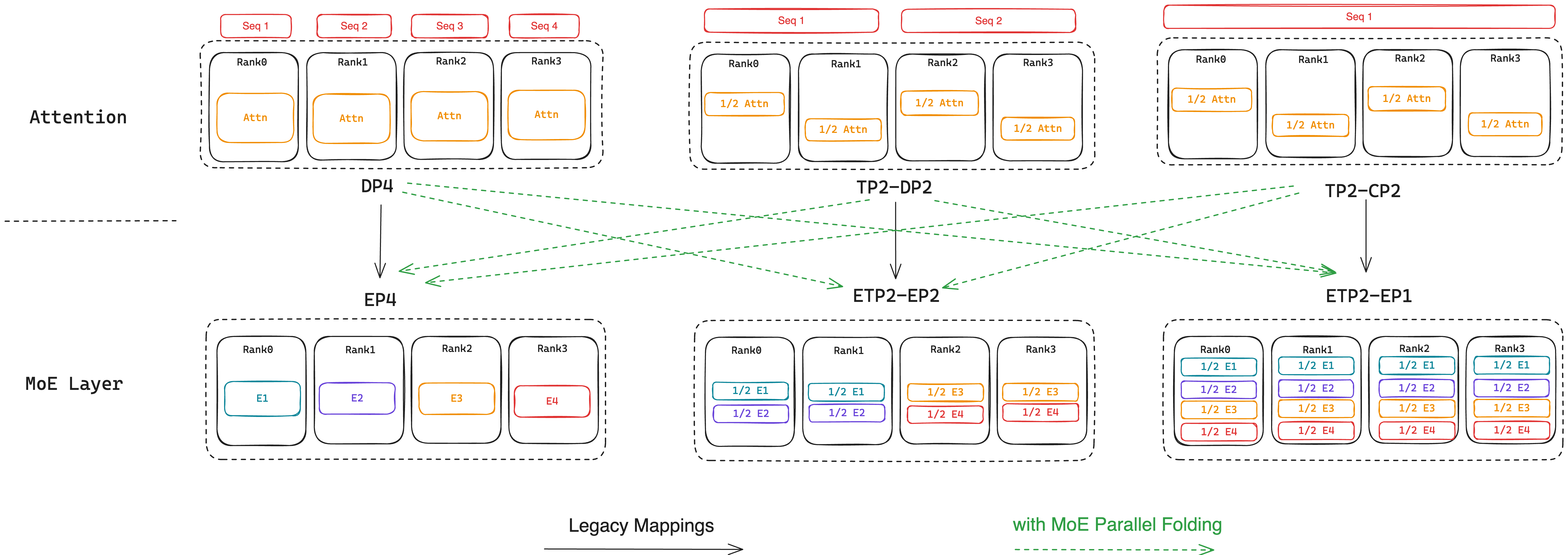
Figure 1: Illustration of parallelism mappings with MoE Parallel Folding.
Token Dispatcher
The study also introduces a sophisticated token-level dispatcher, capable of handling complex parallelism schemes within MoE models. This dispatcher facilitates both token-dropping and token-dropless training paradigms across various parallel dimensions, ensuring optimized data routing and functional integrity despite dynamic tensor shapes and routing requirements.
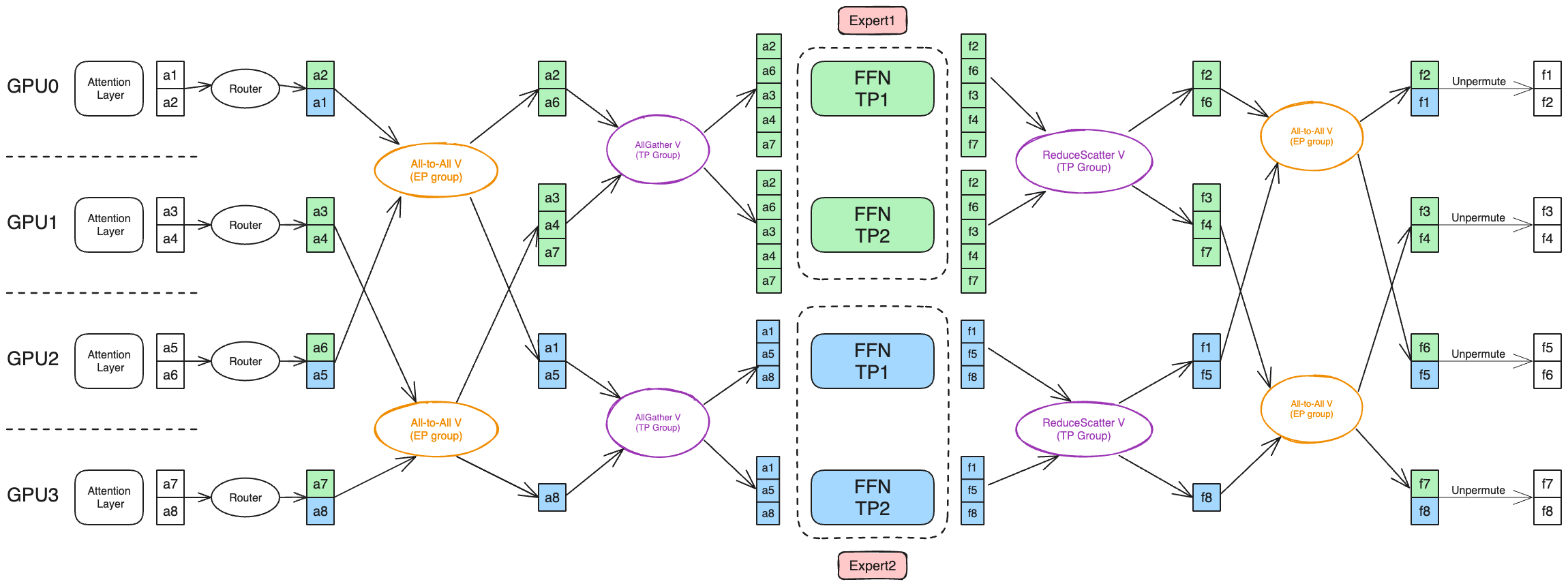
Figure 2: Workflow of token dispatcher with Tensor Parallelism and Expert Parallelism.
Experimental Evaluation
Through rigorous experiments, the framework demonstrated major improvements, achieving up to 49.3% Model Flops Utilization (MFU) for the Mixtral 8x22B model and 39.0% MFU for the Qwen2-57B-A14B model on NVIDIA H100 GPUs. These results significantly outperform existing methods, highlighting the scalability and efficiency of the proposed parallelism strategies.
Figure 3: Strong scaling experiments for various parallelism strategies by increasing number of GPUs up to 1024.
Scaling Efficiency
The practical benefits of MoE Parallel Folding extend to scaling efficiency across 1,024 GPUs and maintaining high performance with sequence lengths up to 128K tokens. The framework’s adaptability to varying computational demands ensures robust scalability, pivotal for accommodating diverse model architectures.
Figure 4: Context-scaling experiments by increasing context length and number of GPUs up to 128K and 1024.
Implications and Future Directions
The implications of this research traverse both theoretical and practical domains. By refining parallelism strategies for MoE models, this study contributes to more efficient resource utilization, potentially reducing the environmental footprint and computational expenses associated with training expansive models. Moreover, the flexibility afforded by MoE Parallel Folding hints at opportunities for further adaptations tailored to emerging hardware architectures and evolving networking capabilities.
Future investigations might explore extending these frameworks towards even larger and more complex model designs, potentially integrating novel routing mechanisms or dynamic adjustment features to further enhance performance and scalability.
Conclusion
The integration of MoE Parallel Folding represents a significant stride in optimizing large-scale MoE model training. By decoupling and refining parallelization strategies, the framework achieves notable improvements in computational efficiency and flexibility, underscoring its practical relevance in contemporary AI research and development. With the demonstrated scalability and performance enhancements, this study paves the way for further innovations in efficient AI model training methodologies.