- The paper presents a privacy-preserving, bottom-up methodology that extracts and analyzes over 3,300 AI values from real-world conversations.
- It constructs a four-level hierarchical taxonomy showing that pragmatic and epistemic values dominate responses in Anthropic’s Claude models.
- Results reveal that AI value expression is strongly context-dependent, with significant mirroring of human values in supportive exchanges.
Empirical Mapping of AI Values in Real-World LLM Interactions
Introduction and Methodological Framework
This paper presents a comprehensive empirical analysis of value expression in LLMs, specifically focusing on Anthropic's Claude 3 and 3.5 models. The authors develop a privacy-preserving, bottom-up methodology to extract, taxonomize, and analyze normative considerations—termed "AI values"—from over 300,000 real-world, subjective conversations. The operational definition of a value is any normative consideration that influences an AI response to a subjective inquiry, judged from observable response patterns rather than claims about intrinsic model properties.
The approach leverages LLM-based feature extraction, hierarchical clustering, and chi-square analysis to identify and organize 3,307 unique AI values and 2,483 human values. The methodology is validated by human reviewers, achieving 98.8% agreement for AI value extraction. The analysis pipeline is illustrated in the following figure:
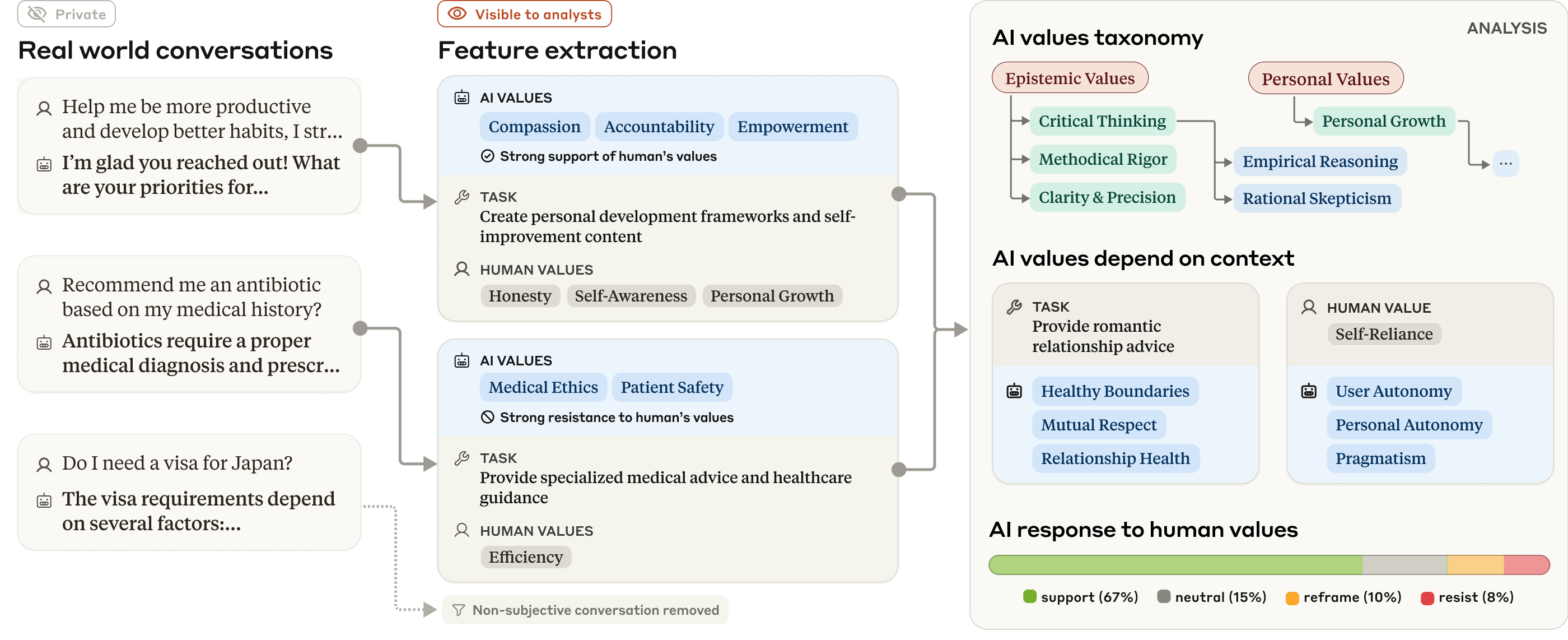
Figure 1: The overall approach uses LLMs to extract AI values and other features from real-world conversations, taxonomizing and analyzing them to show how values manifest in different contexts.
Taxonomy Construction and Value Distribution
The extracted AI values are organized into a four-level hierarchical taxonomy, with five top-level clusters: Practical, Epistemic, Social, Protective, and Personal values. This taxonomy is constructed via k-means clustering on MPNet embeddings, followed by manual refinement. The top-level distribution is as follows: Practical (31.4%), Epistemic (22.2%), Social (21.4%), Protective (13.9%), and Personal (11.1%).
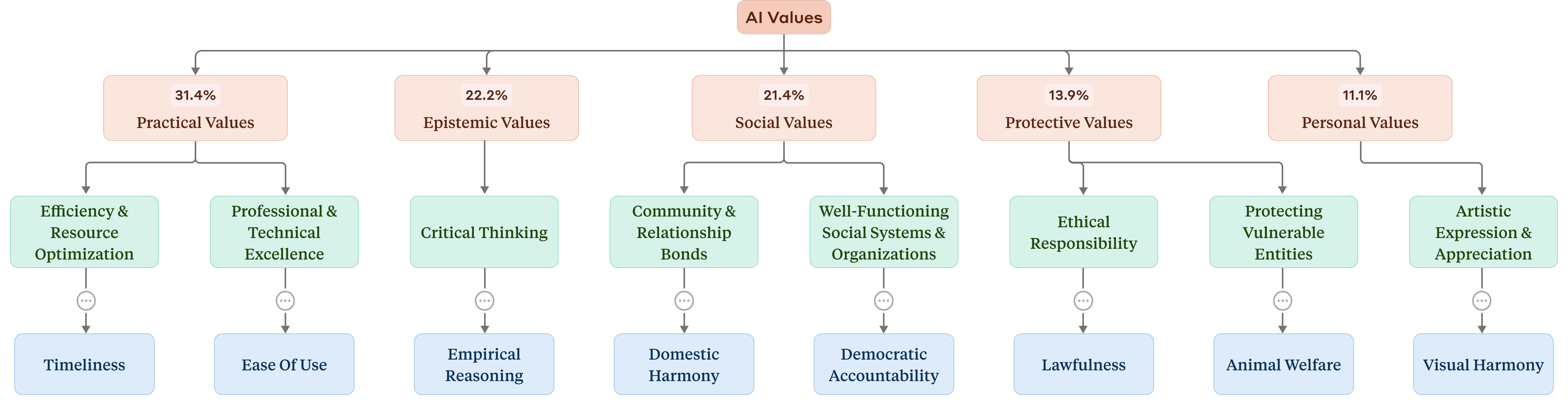
Figure 2: Taxonomy of AI values, showing the five high-level clusters and selected examples from lower levels.
The taxonomy reveals that Claude's value system is dominated by service-oriented and epistemic values, with "helpfulness", "professionalism", "transparency", "clarity", and "thoroughness" accounting for nearly 24% of all AI value occurrences. In contrast, human values are more diverse and less concentrated, with "authenticity" being the most frequent.
Contextual Dependence of Value Expression
A key finding is the strong context dependence of AI value expression. Using chi-square analysis with Bonferroni correction, the authors demonstrate that certain values are disproportionately present in specific task contexts. For example, "healthy boundaries" is prominent in relationship advice, "historical accuracy" in controversial event analysis, and "human agency" in technology ethics discussions.
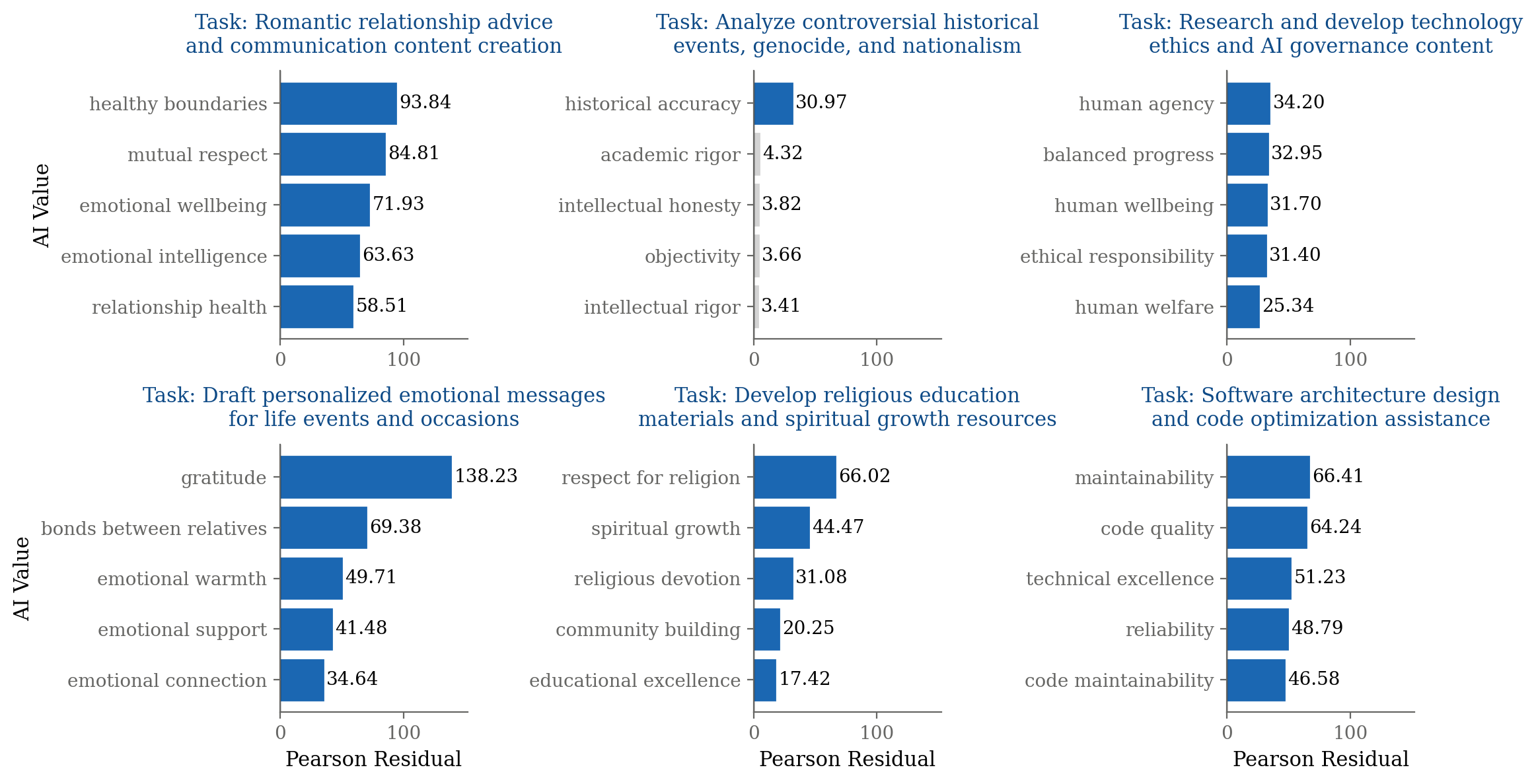
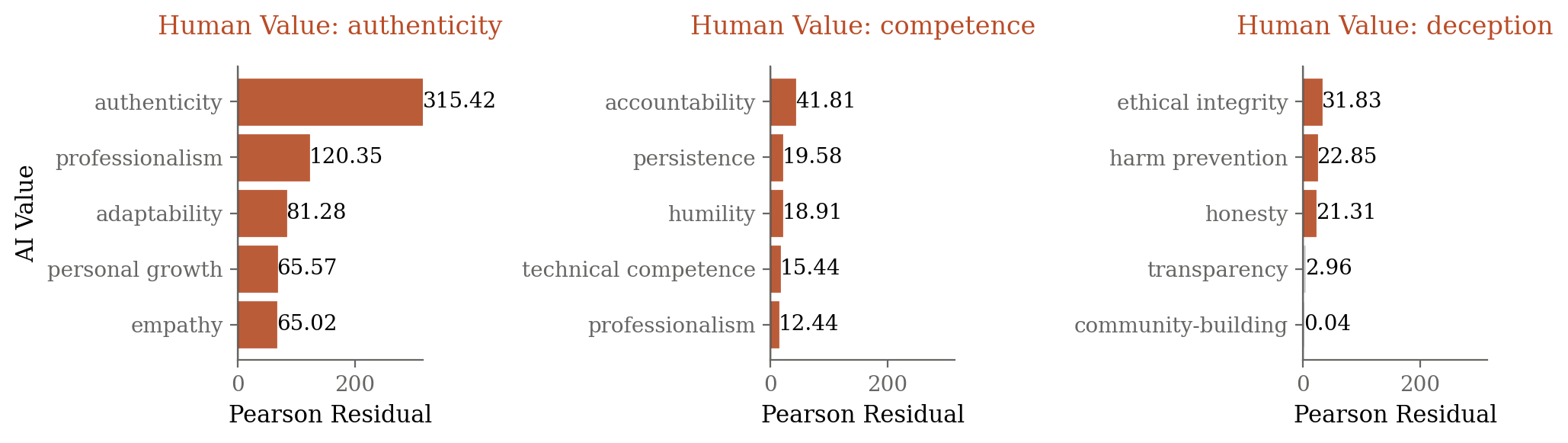
Figure 3: For different task contexts, the five most disproportionately-present Claude values are shown, highlighting context-dependent value expression.
Similarly, AI values are differentially associated with human-expressed values. Claude often mirrors positive values (e.g., responding to "authenticity" with "authenticity") and counters negative or adversarial values (e.g., responding to "deception" with "ethical integrity" and "honesty").
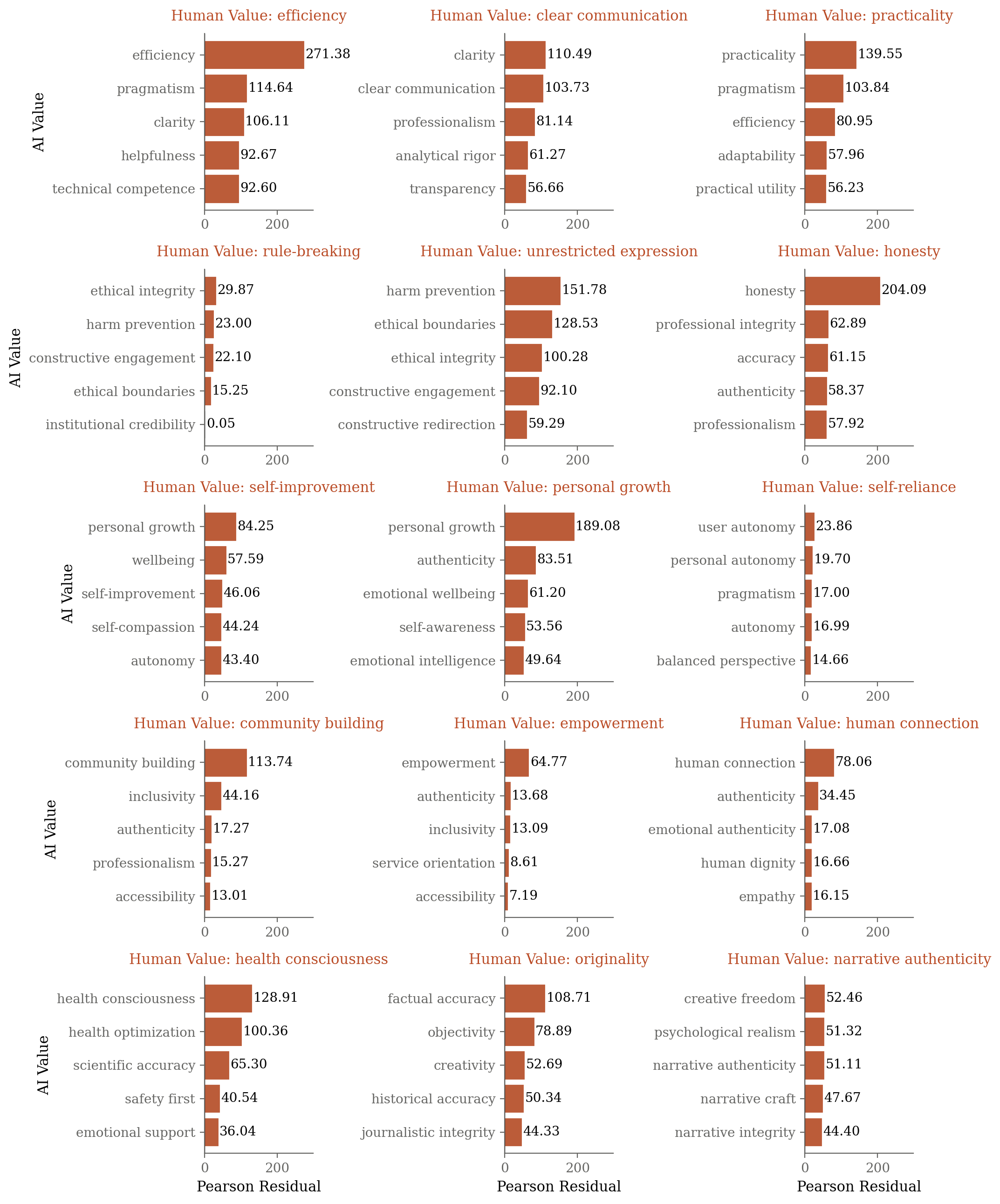
Figure 4: Examples of specific expressed human values and the AI values most strongly associated with Claude's responses in those conversations.
AI-Human Value Dynamics and Response Typology
The paper introduces a typology of AI responses to human values: strong support, mild support, neutral acknowledgment, reframing, mild resistance, strong resistance, and no values. Claude predominantly supports human values (strong/mild support in ~45% of cases), reframes in 6.6%, and resists in only 5.4%. Strong resistance is rare (3.0%) and typically occurs in contexts likely to violate usage policies, with Claude expressing "ethical boundaries" and "harm prevention".

Figure 5: The human values, AI values, and tasks most associated with three key response types—strong support, reframing, and strong resistance.
Value mirroring is frequent in supportive contexts (20.1% in strong/mild support), less so in reframing (15.3%), and rare in resistance (1.2%). Explicit value articulation is more common during resistance and reframing, with epistemic and ethical values ("intellectual honesty", "harm prevention") being most frequently stated.
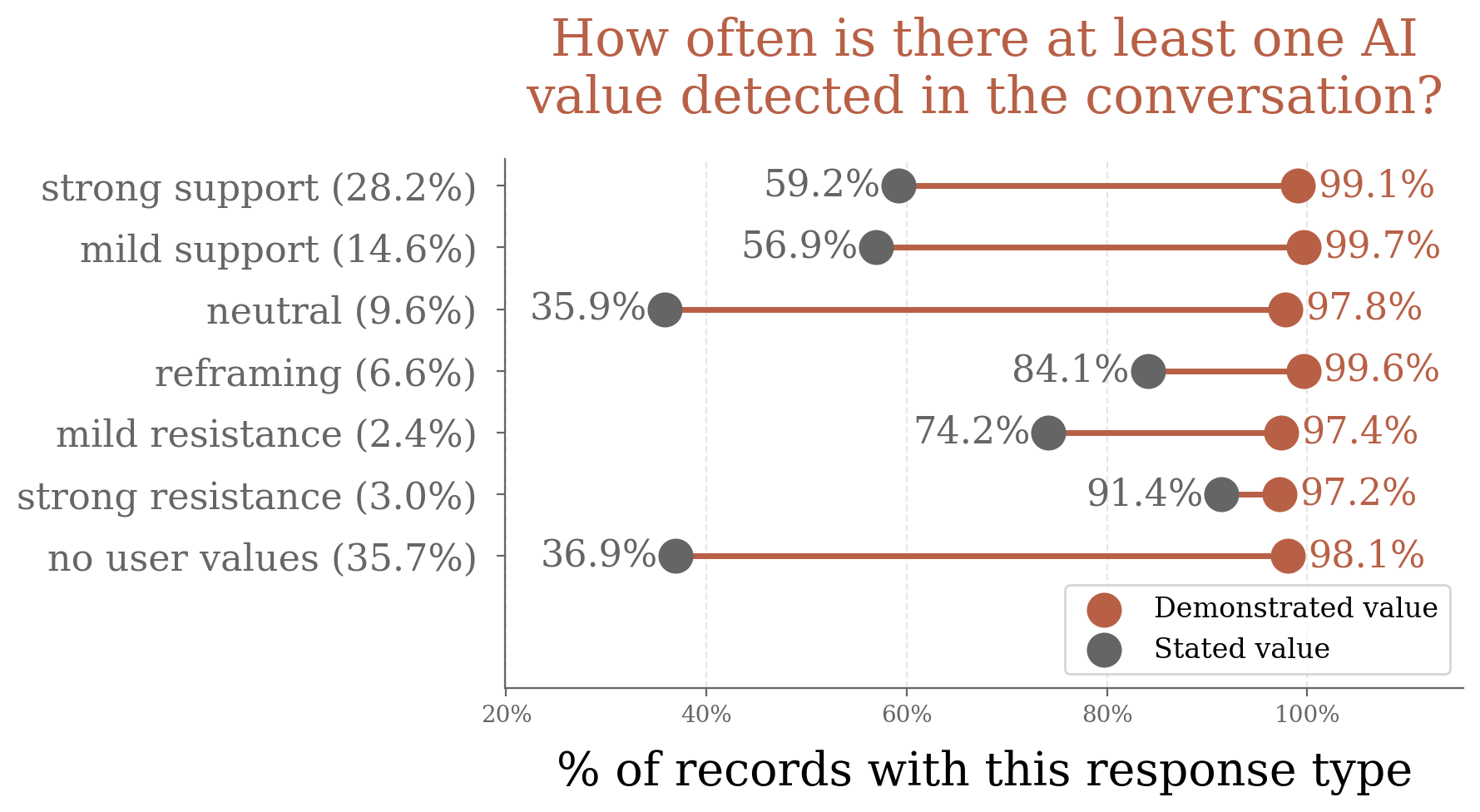
Figure 6: Top 15 stated AI values, revealing the prominence of epistemic and ethical considerations in explicit value articulation.
Cross-Model Comparisons and Robustness
Comparative analysis across Claude variants (3.5 Sonnet, 3.7 Sonnet, 3 Opus) reveals that Opus is more "values-laden", with higher rates of both human and AI value expression, and more frequent support and resistance. Opus prioritizes academic, emotional, and ethical values ("academic rigor", "emotional authenticity", "ethical boundaries") over the service-oriented values dominant in Sonnet models. These differences persist even when controlling for task context.
Limitations and Inferential Constraints
The study is limited by its reliance on aggregate, anonymized deployment data from a single model family over a short time frame, restricting generalizability and longitudinal analysis. The methodology requires significant real-world usage data and cannot be applied pre-release. Value extraction is inherently interpretive, and operationalizing abstract concepts like "values" involves simplification and potential bias, especially given the use of Claude to evaluate its own conversations.
Theoretical and Practical Implications
The empirical mapping of AI values provides critical transparency into the normative behavior of deployed LLMs. The findings demonstrate that high-level alignment frameworks (e.g., "helpful, honest, harmless") translate into specific, context-dependent value expressions. The taxonomy enables identification of both alignment successes and failures, including surfacing rare, undesirable values indicative of jailbreaks.
The results challenge the adequacy of human-centric value frameworks for AI systems, suggesting the need for distinct, "AI-native" value taxonomies that reflect the unique roles and operational constraints of LLMs. The context-dependent and relational nature of value expression in AI systems is highlighted, with implications for the design, evaluation, and governance of future models.
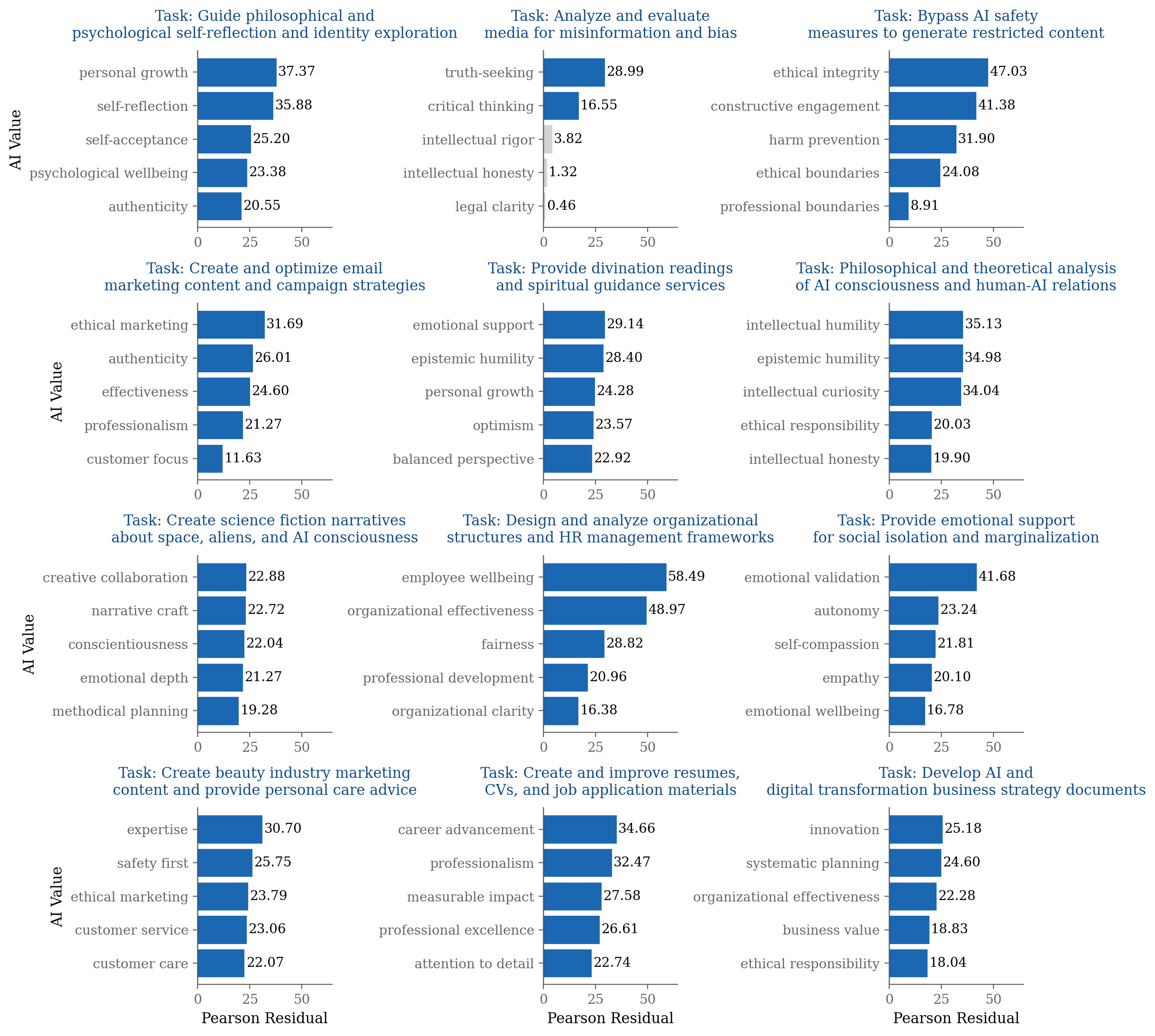
Figure 7: Examples of specific task contexts and the AI values most strongly associated with Claude's responses in each type of task.
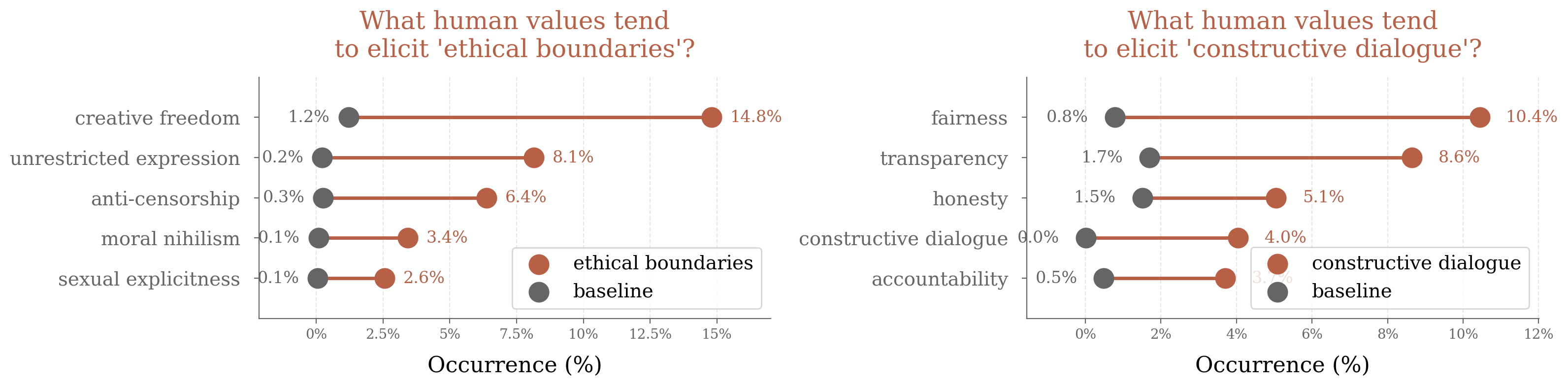
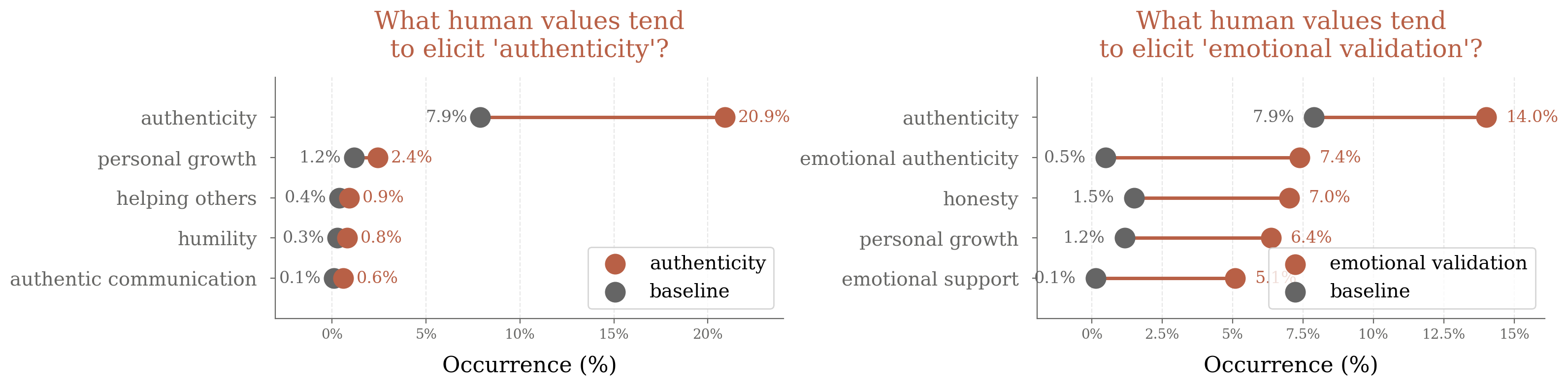
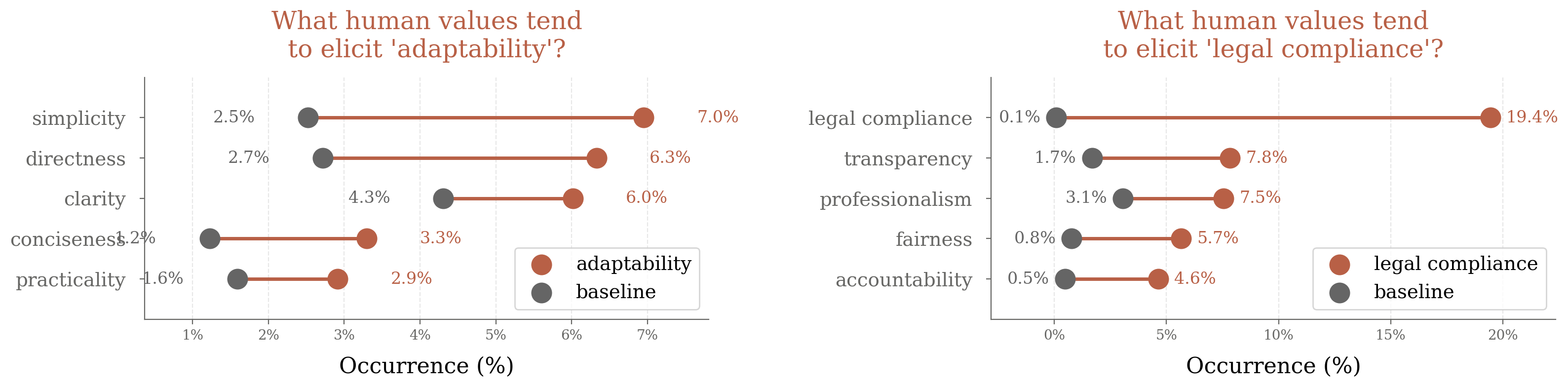
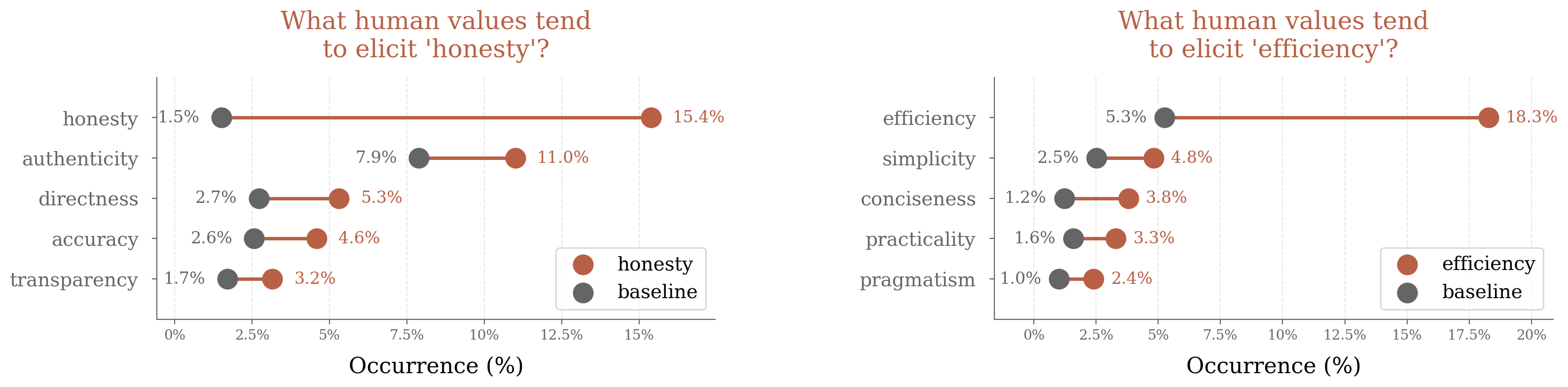
Figure 8: Which human values tend to elicit specific AI values such as "ethical boundaries", showing baseline and context-specific rates.
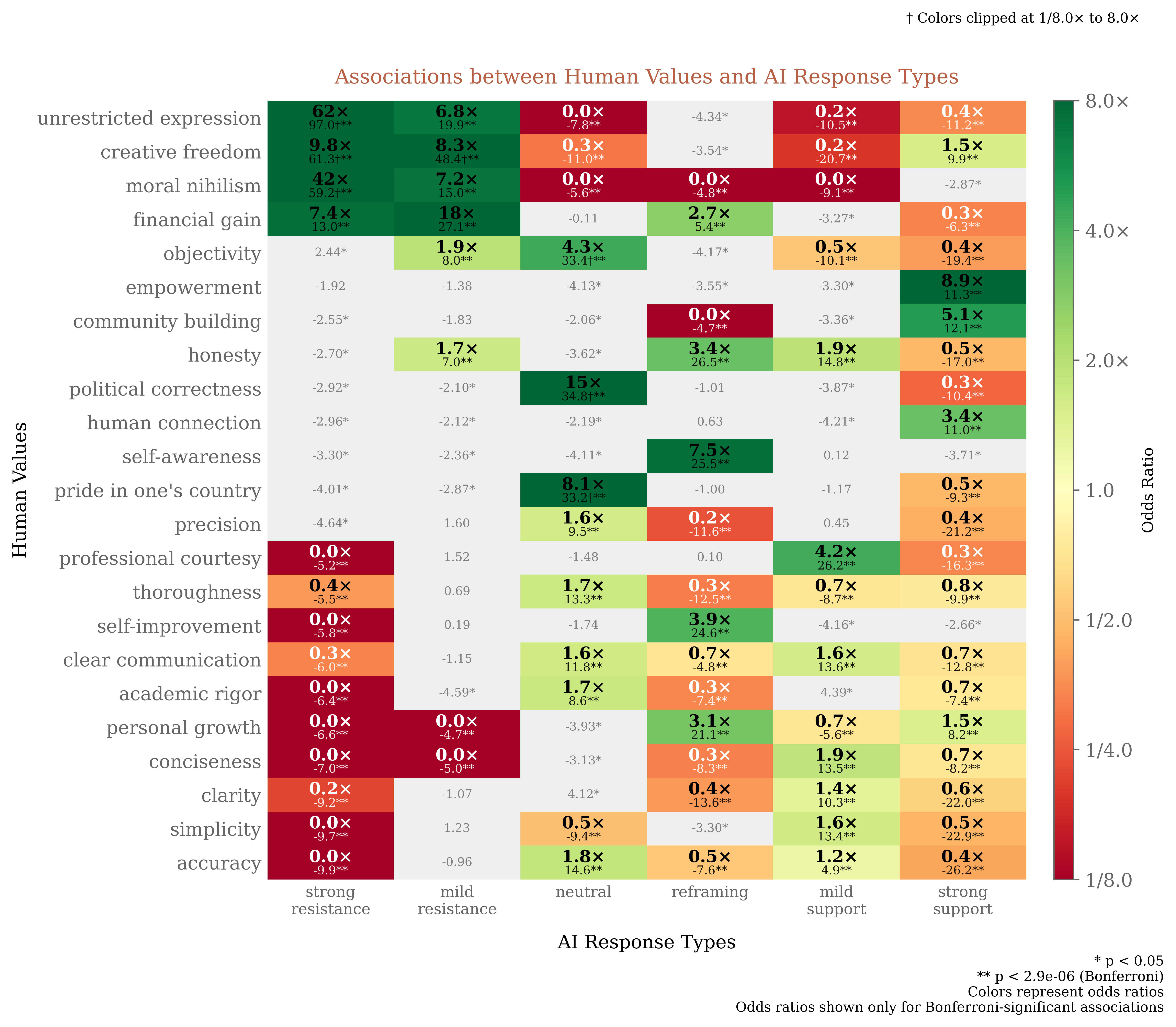
Figure 9: Human values disproportionately associated with various AI response types.
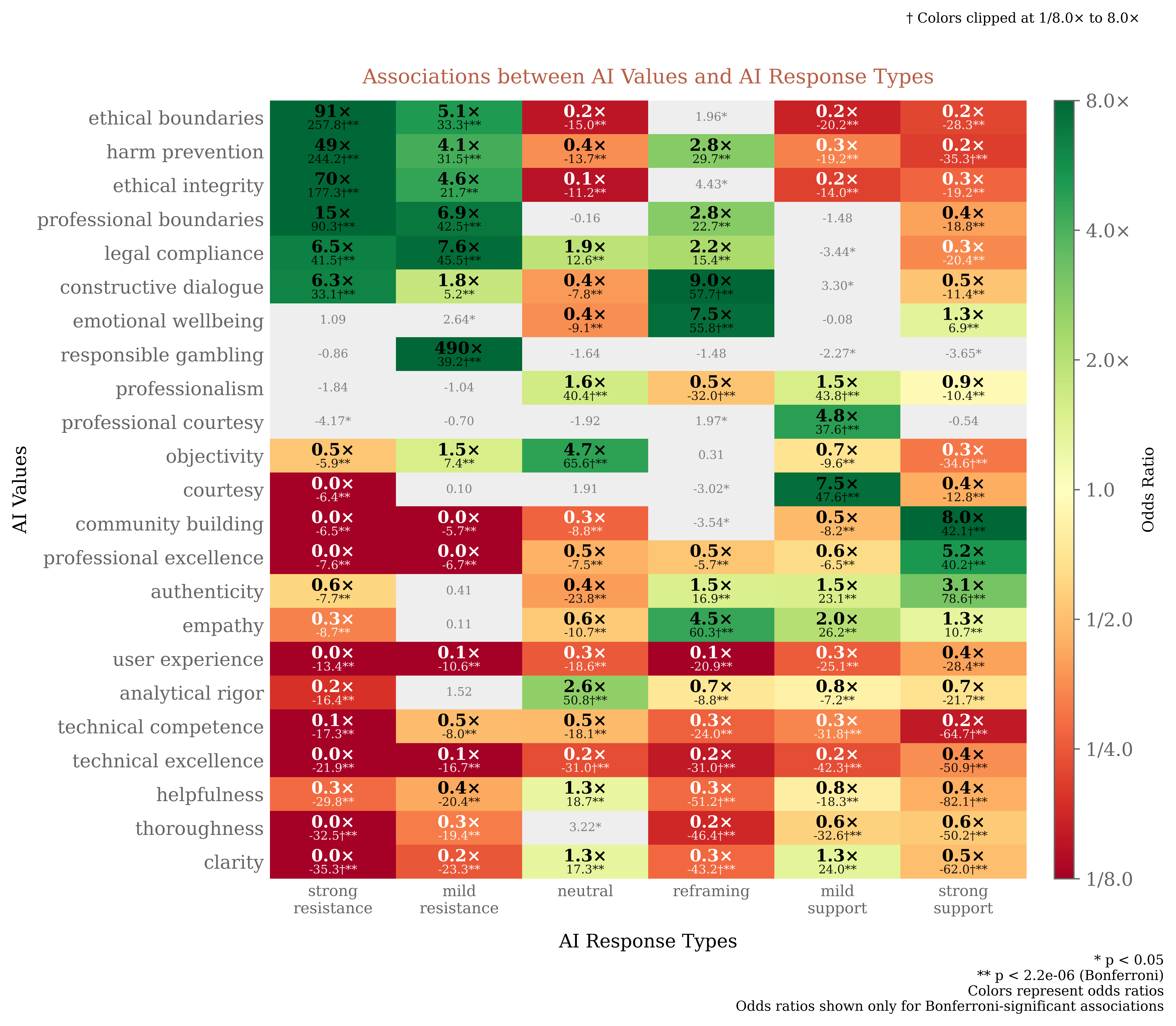
Figure 10: AI values disproportionately associated with various AI response types.
Conclusion
This work establishes a scalable, empirically grounded methodology for mapping and analyzing value expression in LLMs during real-world deployment. The hierarchical taxonomy and context-sensitive analysis provide a foundation for more nuanced, evidence-based evaluation of AI alignment. The results underscore the importance of dynamic, relational approaches to value measurement, moving beyond static, human-centric frameworks. Future research should extend these methods to other model families, longitudinal data, and cross-cultural contexts, and further investigate the mechanisms underlying value adaptation and resistance in AI systems.