DianJin-R1: Evaluating and Enhancing Financial Reasoning in Large Language Models
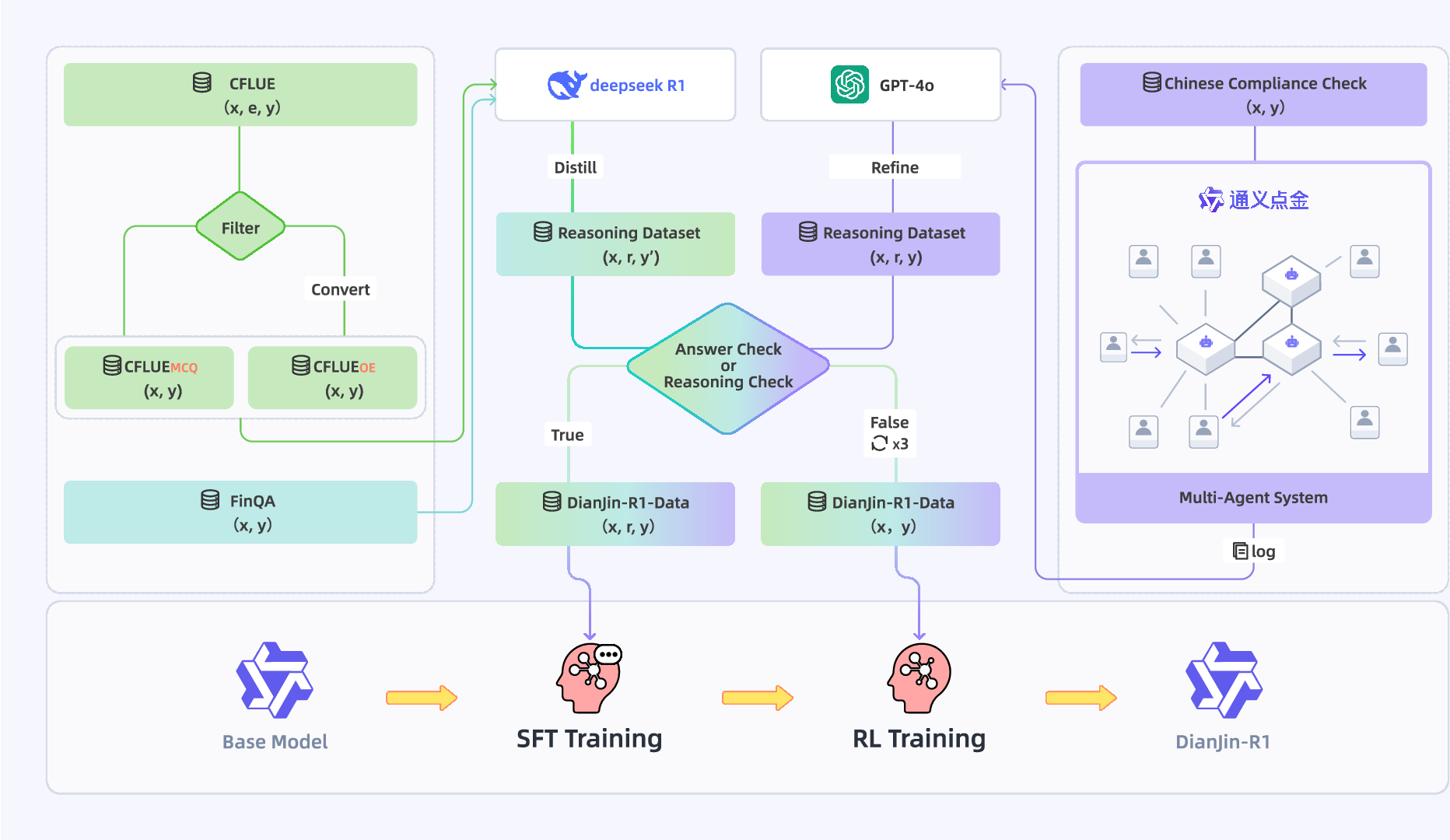
Abstract: Effective reasoning remains a core challenge for LLMs in the financial domain, where tasks often require domain-specific knowledge, precise numerical calculations, and strict adherence to compliance rules. We propose DianJin-R1, a reasoning-enhanced framework designed to address these challenges through reasoning-augmented supervision and reinforcement learning. Central to our approach is DianJin-R1-Data, a high-quality dataset constructed from CFLUE, FinQA, and a proprietary compliance corpus (Chinese Compliance Check, CCC), combining diverse financial reasoning scenarios with verified annotations. Our models, DianJin-R1-7B and DianJin-R1-32B, are fine-tuned from Qwen2.5-7B-Instruct and Qwen2.5-32B-Instruct using a structured format that generates both reasoning steps and final answers. To further refine reasoning quality, we apply Group Relative Policy Optimization (GRPO), a reinforcement learning method that incorporates dual reward signals: one encouraging structured outputs and another rewarding answer correctness. We evaluate our models on five benchmarks: three financial datasets (CFLUE, FinQA, and CCC) and two general reasoning benchmarks (MATH-500 and GPQA-Diamond). Experimental results show that DianJin-R1 models consistently outperform their non-reasoning counterparts, especially on complex financial tasks. Moreover, on the real-world CCC dataset, our single-call reasoning models match or even surpass the performance of multi-agent systems that require significantly more computational cost. These findings demonstrate the effectiveness of DianJin-R1 in enhancing financial reasoning through structured supervision and reward-aligned learning, offering a scalable and practical solution for real-world applications.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.