- The paper introduces the Tina model family that uses LoRA and reinforcement learning to enhance reasoning in a compact 1.5B parameter model.
- The methodology employs parameter-efficient updates, achieving robust performance with as low as $9 training cost and sub-$100 overall expenditures.
- The study demonstrates that Tina models rival SOTA reasoning benchmarks, offering a cost-effective and scalable approach for advanced AI research.
"Tina: Tiny Reasoning Models via LoRA"
Introduction
The paper "Tina: Tiny Reasoning Models via LoRA" introduces the Tina model family, which aims to enhance reasoning abilities in LLMs through cost-effective techniques. Tina utilizes low-rank adaptation (LoRA) in combination with reinforcement learning (RL) to improve reasoning capabilities in a 1.5 billion parameter model. The focus is on achieving competitive reasoning performance while dramatically reducing computational and financial costs associated with contemporary state-of-the-art (SOTA) models.
Methodology
Low-Rank Adaptation
LoRA is utilized to perform parameter-efficient updates on pre-trained LLMs. This involves training only a limited number of parameters, which significantly reduces computational resources and costs.
Reinforcement Learning
The Tina models leverage RL to refine reasoning abilities from verifiable reward signals. By building upon a compact model architecture (DeepSeek-R1-Distill-Qwen-1.5B), Tina applies RL by updating minimal parameters, providing a scalable approach to reasoning performance improvement.
Training and Evaluation
Tina models underwent rigorous evaluation against multiple reasoning benchmarks, including AIME24/25, AMC23, and MATH500. The evaluation process revealed that Tina models could rival or surpass existing SOTA models in reasoning tasks despite their smaller scale and reduced training cost.
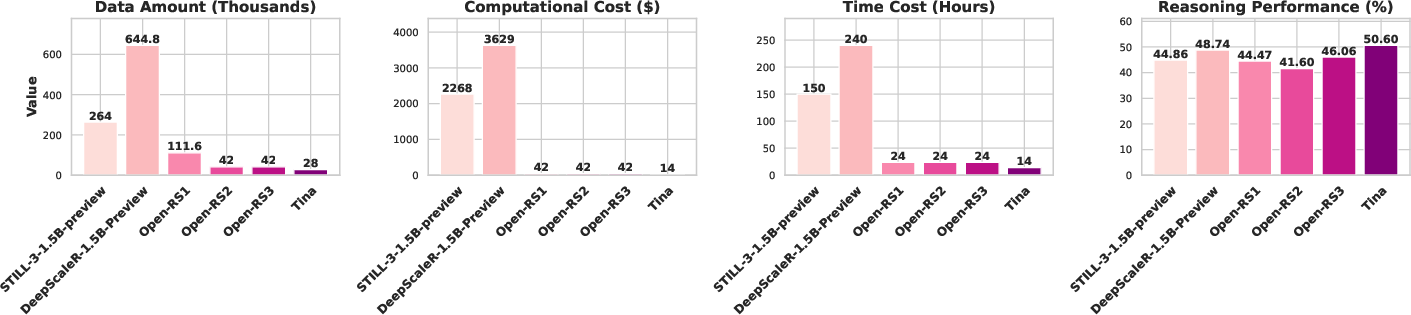
Figure 1: Overall comparison between Tina and baseline models.
The research presents a compelling trade-off: adopting a lightweight model architecture with parameter-efficient fine-tuning (via LoRA) maintains robust reasoning performance at a reduced cost. The study highlights:
Computational Costs
The study's training and evaluation setups were strategically optimized to limit expenditure while maximizing performance gains. Financial breakdowns, as presented in the appendix, emphasize cost-effectiveness: the best-performing models of each experiment were achievable with sub-\$100 expenses.
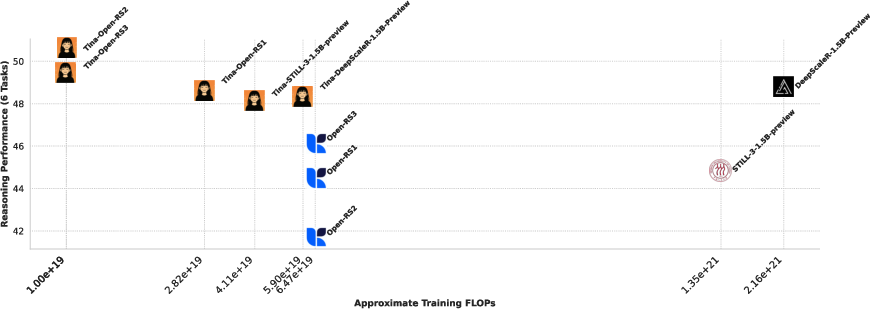
Figure 3: Less is more in LoRA-based RL.
Implications and Future Work
The success of the Tina model family suggests broader implications for the AI community, particularly in democratizing access to advanced reasoning model development. The research posits that LoRA derives its efficiency from a rapid adaptation to output formats rewarded during RL, emphasizing structural learning over comprehensive knowledge revision. This discovery suggests new avenues for continued exploration using parameter-efficient techniques at small scales.
Conclusion
The paper concludes that robust reasoning capabilities can be achieved economically in smaller models by leveraging parameter-efficient updates. Tina represents significant progress in making advanced AI technology more accessible. Despite its promising contributions, the work notes limitations in scaling for more complex tasks and potential gains through further parameter optimization.
Overall, the research reveals a promising pathway for enhancing LLM reasoning abilities through cost-effective strategies, enabling broader, more accessible experimental opportunities within the AI research community.