- The paper introduces a universal audio model combining hybrid tokenization with a specialized LLM, achieving state-of-the-art performance in ASR, audio understanding, and generation.
- The paper details a three-step architecture—audio tokenizer, LLM, and detokenizer—that effectively transforms complex audio signals into coherent outputs.
- The paper leverages over 13 million hours of real-world data and rigorous evaluation to set new benchmarks in multimodal audio processing.
Kimi-Audio Technical Report
The "Kimi-Audio Technical Report" (2504.18425) presents the development and evaluation of Kimi-Audio, a comprehensive open-source audio foundation model designed to excel in various audio processing tasks, such as understanding, generation, and conversation. This document provides an in-depth exploration into the model's architecture, the methodologies underlying its training, the data curation strategies employed, and the evaluation benchmarks.
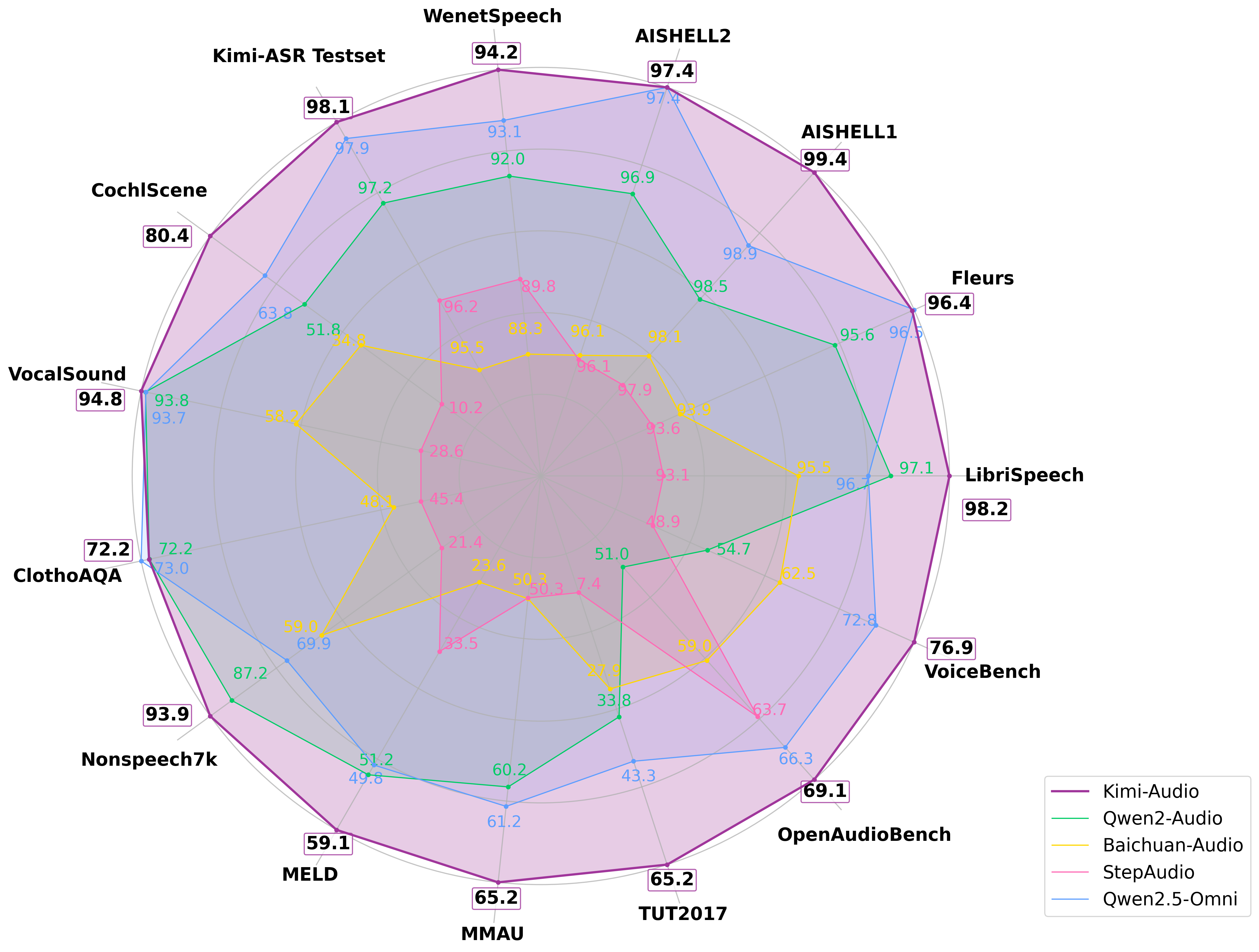
Figure 1: Performance of Kimi-Audio and previous audio LLMs including Qwen2-Audio and others on various benchmarks.
Background and Motivation
The relevance and complexity of audio in human interaction highlight its importance in the field of artificial general intelligence. While traditional approaches to audio modeling often addressed specialized tasks separately, recent advancements have encouraged a shift towards developing universal models. These models are capable of performing a broad spectrum of tasks, including ASR, audio understanding, and speech generation, by employing LLM architectures to leverage the underlying sequential nature and semantic correlations between audio and text modalities.
Though prior works have applied LLMs to segments of audio processing like generation, understanding, and recognition, they fell short of encompassing a universal model that addresses multiple audio tasks. Common limitations include a narrow task focus and limited pre-training on audio data, restricting their applications across diverse audio scenarios and tasks.
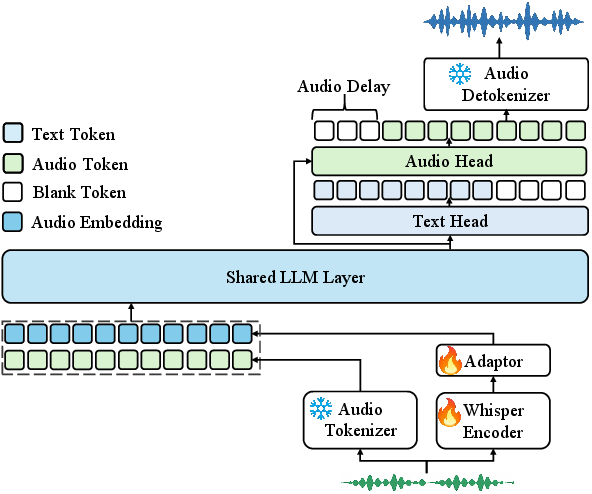
Figure 2: Overview of the Kimi-Audio model architecture: (1) an audio tokenizer that extracts discrete semantic tokens and a Whisper encoder that generates continuous acoustic features; (2) an audio LLM that processes audio inputs and generates text and/or audio outputs; (3) an audio detokenizer converts audio tokens into waveforms.
Model Architecture
Kimi-Audio's architecture is a three-step process involving an audio tokenizer, an audio LLM, and an audio detokenizer. The audio tokenizer is designed to capture essential audio characteristics by producing both discrete semantic tokens and continuous acoustic vectors, thereby enhancing perception capability. Utilization of discrete tokens via a vector quantization layer alongside continuous acoustic inputs allows the system to exploit both semantic-rich understanding and detailed audio representation.
The core of Kimi-Audio is its LLM, a specialized form of a standard LLM with adapted architecture. It processes multimodal inputs for generating seamless text as well as audio outputs. The shared layers in the model facilitate cross-modal representation integration, while specialized heads handle either text or audio generation.
Kimi-Audio incorporates a novel audio detokenizer capable of transforming semantic tokens into coherent audio waveforms. This chunk-wise streaming detokenizer adopts a flow matching approach to efficiently generate audio with high fidelity while maintaining low computational overhead.
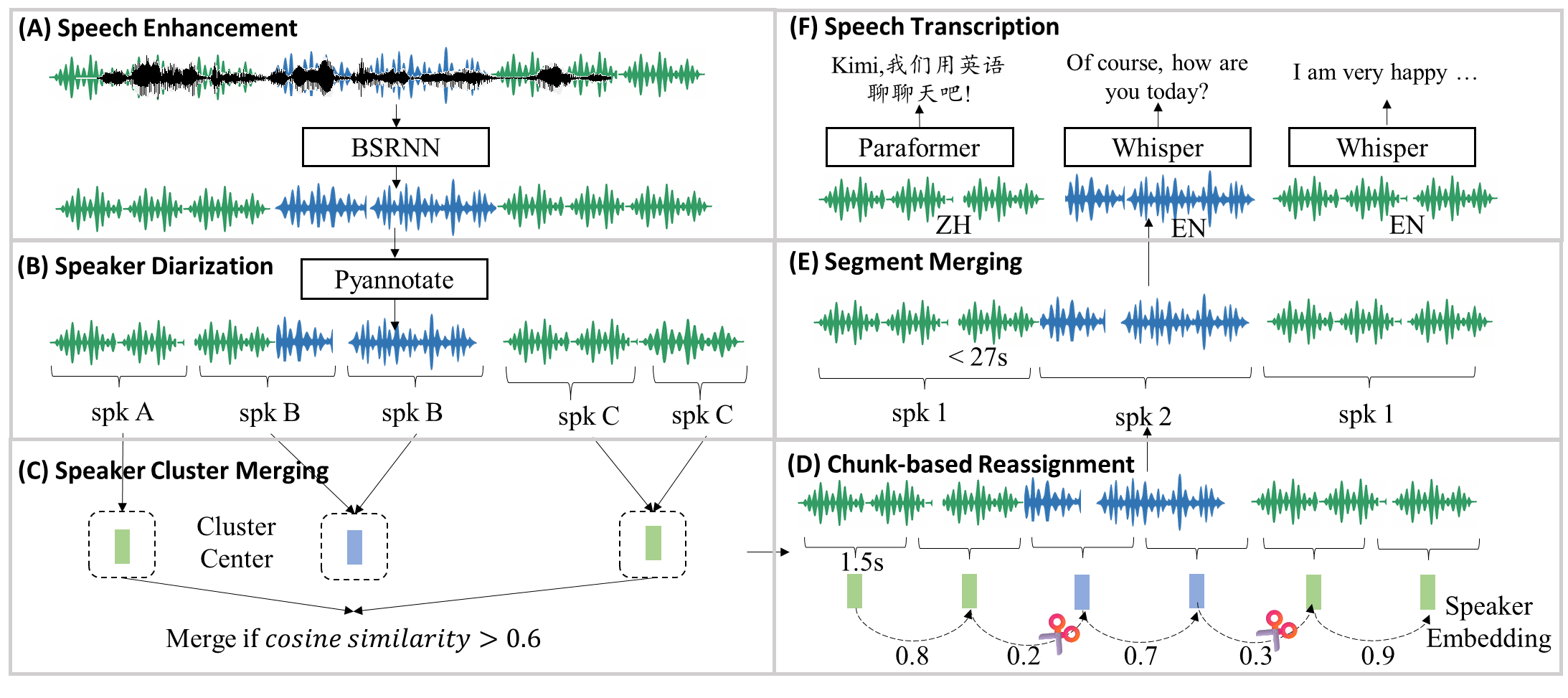
Figure 3: Processing pipeline for the audio pre-training data.
Given the complex landscape of real-world audio signals and existing limitations of audio models that rely heavily on unimodal data, Kimi-Audio leverages an extensive multimodal pretraining regime over 13 million hours of diverse, real-world audio data, supported by an efficient data processing pipeline (Figure 3). The model benefits greatly from a systematic approach to data curtailment, including speaker diarization and speech enhancement strategies, ensuring high-quality and diverse scenario coverage.
Kimi-Audio's pioneering use of flow matching in its audio detokenizer and its hybrid tokenization framework profoundly enhances its audio processing capability, enabling it to achieve state-of-the-art (SOTA) results across several audio-language tasks.
Through rigorous evaluation using a customized evaluation toolkit, Kimi-Audio has demonstrated superior performances on various benchmarks covering tasks such as ASR, audio understanding, and audio-to-text conversation.
Conclusion
The "Kimi-Audio Technical Report" (2504.18425) introduces a significant development in the domain of audio foundation models, integrating advanced techniques to achieve a truly universal audio-language processing framework. By leveraging advanced methods such as hybrid tokenization, robust LLM architecture, and a sophisticated pre-training methodology on a substantial dataset, Kimi-Audio excels across diverse audio benchmarks, setting a new standard for open-source models in this domain. Future research should look towards integrating audio transcription and description modalities more seamlessly, exploring enriched representations that balance semantic with acoustic fidelity while enhancing models' performance across modalities.