- The paper proposes a novel prefix consensus model that allows partial block commits via non-binary voting to enhance scalability and robustness in BFT systems.
- It integrates parallel data dissemination with strict quorum certificate formation, achieving 260k TPS under geo-distributed conditions with sub-second latency.
- System-level optimizations such as aggregate signatures, dedicated communication channels, and reputation mechanisms reinforce resilience against network faults.
Introduction
The paper "Raptr: Prefix Consensus for Robust High-Performance BFT" (2504.18649) introduces Raptr, a Byzantine Fault-Tolerant (BFT) state machine replication (SMR) protocol that tightly integrates high-throughput data dissemination with rigorous consensus and robustness primitives. The main insight of Raptr is to depart from conventional binary block voting and leverage prefix-based consensus, allowing partial block commits and non-binary quorum certificates. This approach unifies the scalability and parallelization strengths of DAG-based BFT protocols with the optimal latency, safety, and robustness guarantees of leader-based designs. In extensive geo-distributed deployments, Raptr sustains up to 260,000 transactions per second (TPS) with sub-second latency on 100 replicas and demonstrates negligible performance degradation under both partial and network-wide message drops.
Background and Motivation
Leader-based BFT SMR systems (e.g., PBFT, HotStuff, Jolteon) achieve optimal good-case latency but suffer from a leader bottleneck: one replica broadcasts the full block, capping throughput as the system scales. Prior work, notably quorum store approaches and DAG-based consensus mechanisms (e.g., Narwhal, Tusk, Shoal++, Mysticeti), has addressed throughput via parallel data dissemination, often sacrificing optimal latency or resilience, especially in adverse network conditions or under faults.
DAG-based BFT protocols offer high throughput and resilience by distributing both proposal and data dissemination responsibilities. Their primary limitation is increased latency due to deep DAG dependencies and the need for additional fetches (especially in non-certified designs like Mysticeti, where even minimal losses can cause significant throughput collapse). In contrast, leader-based protocols offer minimal message delays but are limited by leader bandwidth and degrade under scale.
The core bottleneck—ensuring simultaneous low latency, high throughput, and robustness—remains unresolved in existing systems. Raptr's prefix consensus model addresses this by decoupling data availability and block safety, allowing for partial progress and commit, even in the presence of latency heterogeneity and partial data propagation.
Prefix Consensus: Protocol Architecture
Raptr’s primary innovation is non-binary voting on block prefixes. Each consensus block contains a sequence of batch digests (or PoAs), but votes and certificates encode not just agreement on the block as a whole, but on prefixes of the block corresponding to the maximal set of batches each replica has locally available. This allows Raptr to form quorum certificates on committable prefixes, so consensus can proceed even if some batches are missing at some replicas, as long as an availability threshold (S≥f+1) is satisfied for the prefix.
Upon proposing a new block, the leader includes references to as-yet-uncertified batches. Replicas receive the proposal and locally select the longest available prefix of batch digests they can verify. They then sign and broadcast a vote for this prefix. Quorum certificates (QCs) are formed as soon as $2f+1$ votes are obtained, and the prefix encoded in the QC is determined by the S-th maximum prefix in the votes—a guarantee that at least one honest replica can provide all data in the committed prefix.
This non-binary scheme ensures that all committed prefixes across honest replicas are nested (i.e., total order is preserved via prefix containment), and liveness is maintained as long as at least one honest replica can provide the data for any committed prefix.
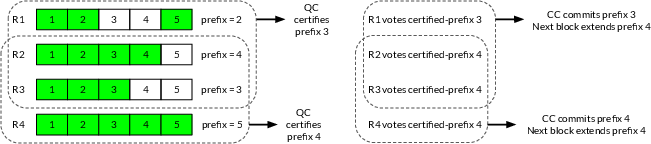
Figure 1: Illustration of the non-binary voting on prefixes in Raptr, with different replicas voting for the longest received available prefix, and prefix containment ensuring safety and commit progression.
Algorithmic Details and Safety
Raptr’s consensus proceeds as a pipeline of rounds, where each round has a unique leader responsible for extending the highest known committed prefix. Raptr’s commit logic is as follows:
- QC Formation: Each QC aggregates votes for prefixes of a proposal. The certified prefix in the QC is the S-th largest among all votes, guaranteeing retrievability.
- Commit Certificates: Sequential QC votes aggregate into commit certificates, where the minimum certified prefix in a quorum of CC votes is committed.
- Entry Reasons: Advancement to the next round occurs upon seeing a full-prefix QC, a commit certificate, or a timeout certificate (formed analogously to classical BFT timeouts).
- Safety: Prefix containment ensures total order and non-duplication; formal safety proofs are constructed via quorum intersection arguments and induction on round numbers, guaranteeing that all commits are to nested prefixes.
The protocol decouples the availability quorum (for prefix data retention) from the consensus (safety) quorum, enabling high throughput without stalling on outlier batch propagation delays.
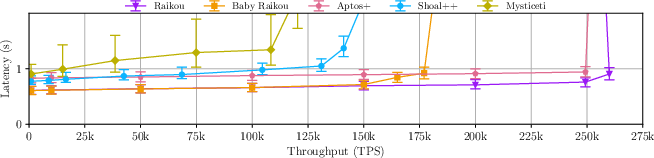
Figure 2: Common-case performance of Raptr versus other protocols, with Latency (y-axis) versus Throughput (x-axis), showing Raptr's superior performance at scale.
System-Level Optimizations
Raptr supports several implementation and systems enhancements, crucial for achieving the reported performance:
- Aggregate and Non-Interactive Signatures: Raptr uses optimized aggregate signature schemes (notably no-commit proofs) that support efficient certification of distinct prefixes, amortizing signature verification costs.
- Parallel Data and Consensus Channels: Dedicated network channels for consensus versus data and non-data messages reduce head-of-line blocking and transmission-induced latency.
- Reputation Mechanisms: Both leader and batch author reputation is tracked to discourage selection of slow or unreliable peers, efficiently mitigating Byzantine or non-Byzantine proposer and author failures.
- Batch Age Enforcement: Raptr delays proposal inclusion of newly created batches until they are likely to be sufficiently disseminated, aligning critical-path latency with real-world network conditions and minimizing unnecessary timeout or partial commit events.
Empirical Evaluation
Evaluation is conducted on 100 geo-distributed Google Cloud replicas, each with 64 vCPUs and 256GB RAM, running in 10 global regions. Traffic mixes, network parameters, and consensus behaviors are chosen to reflect real-world deployments at the scale of top blockchain networks.
Key empirical results:
- Throughput/Latency: Raptr achieves 260k TPS at sub-second latency (755ms at 250k TPS), outperforming state-of-the-art DAG (Mysticeti, Shoal++) and optimized leader-based (Aptos+) protocols.
- Latency Breakdown: Raptr removes proof creation steps from the critical path, yielding up to 25% lower latency than proof-centric quorum store designs at high load.
- Robustness: Under partial network glitches (1% drop at 5% of nodes; total message loss 0.05%), Raptr's throughput and latency are essentially unaffected, in stark contrast to DAG protocols, which experience >35% latency increases and severe throughput collapses.
- Network-Wide Degradation: With 1% egress drops at all nodes, Raptr incurs only a modest additional latency uptick (~15%), maintaining flat TPS, compared to Shoal++ and Mysticeti, which enter sinusoidal throughput/latency cycles or stall.
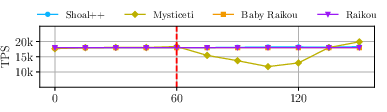
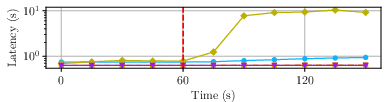
Figure 3: Impact of a partial network glitch on Raptr and competing protocols, showcasing Raptr's resilience and stable performance.
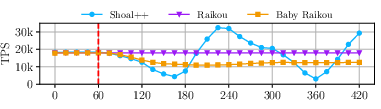
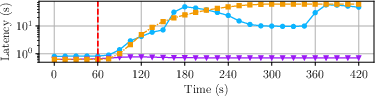
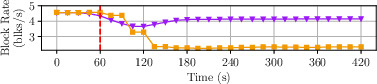
Figure 4: Impact of a full network glitch on performance; only Raptr maintains near-constant throughput and graceful latency degradation.
Practical and Theoretical Implications
Raptr demonstrates that prefix voting and partial commits resolve the resilience-latency-throughput trilemma in BFT SMR protocols at large scale. Decoupling data and safety quorums enables robust operation even under adversarial or network-fault stress, without incurring the latency overheads that undermine existing scalable BFT protocols.
From a systems standpoint, prefix consensus could become foundational in upcoming high-performance permissioned and permissionless blockchains, offering optimal tradeoffs for decentralized applications requiring both fast commit and resilience.
Theoretically, Raptr’s approach may inform both further developments in non-binary consensus theory and protocol designs that seek to index progress in partial proposal aggregation (e.g., sharding, dynamic committee, or multi-chain/single-chain hybrid protocols).
Future Directions
Potential extensions include:
- Adaptive quorum sizes and dynamic prefix granularity for further optimizing under heterogeneous network conditions.
- Integration of dynamic membership and reconfiguration, leveraging the prefix property for seamless validator rotation.
- Generalization to permissionless contexts or asynchronous consensus models, where partial commits may accelerate liveness recovery.
- Automated batching and slotting strategies using Raptr’s prefix abstraction to better utilize bandwidth under adversarial workload models.
Conclusion
Raptr establishes prefix consensus as a robust paradigm, bridging the gap between high-throughput DAG-based and low-latency leader-based BFT architectures. Its combination of non-binary prefix voting, partial block commit, and system-level optimizations yields strong empirical and theoretical guarantees, enabling robust, scalable, and efficient SMR suitable for real-world globally distributed deployments. The protocol sets a new standard for BFT system design under both ideal and adverse conditions, opening avenues for subsequent research on scalable, resilient consensus for modern distributed ledgers and replicated services.