- The paper introduces semi-PD, a system that integrates phase-wise disaggregated computation with unified storage to overcome latency interference and storage inefficiencies.
- The system employs a dynamic resource controller and an SLO-aware algorithm to efficiently manage resource partitioning between prefill and decode phases.
- Performance evaluation shows up to 2.58× lower latency and 1.72× increased throughput compared to state-of-the-art methods.
Efficient LLM Serving with Phase-Wise Disaggregated Computation and Unified Storage
This paper explores a novel system for serving LLMs called semi-PD, which strategically combines disaggregated computation with unified storage. The design addresses significant inefficiencies in existing LLM-serving architectures, particularly focusing on computational and storage paradigms. The study emphasizes enhancing service-level objective (SLO) compliance while reducing latency and increasing throughput.
Introduction and Motivation
The rapid proliferation of LLM deployments in applications such as chatbots and code assistants necessitates systems capable of handling high throughput with minimal latency. Traditional serving systems fall into two categories: unified and disaggregated designs. Unified systems, where prefill and decode phases share resources, struggle with latency interference. In contrast, disaggregated systems alleviate computational interference, but at the cost of storage inefficiencies. This paper identifies four critical issues in disaggregated designs: storage imbalance, KV cache transfer overhead, resource adjustment overhead, and replicated weights.

Figure 1: Illustration of the pros and cons of the different computation and storage patterns. semi-PD can have the advantages of both disaggregated computation and unified storage.
System Design
Disaggregated Computation and Unified Storage
Semi-PD introduces a serving system that effectively combines the advantages of disaggregated computation and unified storage. This system deploys a computation resource controller to manage SM-level disaggregation, enabling efficient resource partitioning between prefill and decode phases. For storage, semi-PD uses a unified memory manager to coordinate asynchronous access, addressing issues of KV cache transfer and resource adjustment overhead.
Low-Overhead Resource Adjustment
Semi-PD’s standout feature is a low-overhead switching mechanism that dynamically adjusts computational resources between phases. By maintaining a resident process that consistently loads weights and KV cache, the system avoids the high latency of reloading and adjustments. This dynamic adjustment is guided by an SLO-aware algorithm that periodically tunes the resource division based on real-time demand and latency requirements.
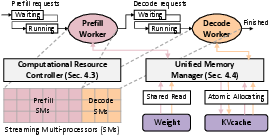
Figure 2: System overview of semi-PD.
Evaluation
The evaluation of semi-PD demonstrates substantial reductions in request latency and increases in throughput under varied deployment scenarios. Compared to state-of-the-art methods like DistServe and vLLM, semi-PD shows up to 2.58× lower latency and 1.72× more requests served under given SLOs. The system consistently achieves high SLO adherence due to its adaptive resource management, even under high-load conditions.
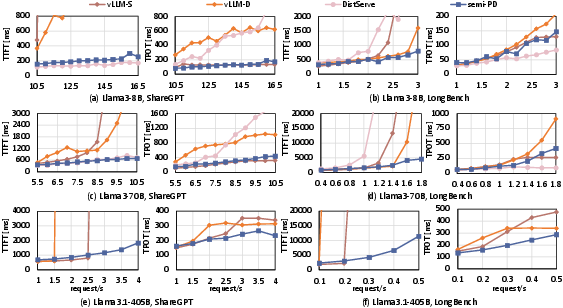
Figure 3: The P90 TTFT and TPOT comparison on Llama series models (lower is better). For Llama3.1-405B, only semi-PD was tested with vLLM-S and vLLM-D, as DistServe couldn't be deployed due to storage constraints.
Implications and Future Work
The findings from semi-PD suggest significant potential for improving LLM-serving infrastructures, particularly in environments with dynamic workloads and tight latency constraints. Future developments could focus on further optimizing the low-overhead resource adjustment mechanism for even finer granular control and adapting the architecture for emerging hardware accelerators.
Conclusion
Semi-PD demonstrates significant potential in addressing the dual challenges of computational interference and storage inefficiency in LLM serving. Its architectural innovations in phased disaggregated computation and unified storage provide a compelling framework for enhancing LLM service performance, particularly in adherence to stringent latency constraints. With its demonstrated reductions in latency and improvements in throughput, semi-PD offers a robust solution for next-generation LLM serving systems.