- The paper demonstrates that the Chatbot Arena leaderboard is susceptible to biases due to selective private testing and overfitting.
- It employs a Bradley-Terry based methodology across over 2 million pairwise comparisons to expose performance disparities among 243 models.
- The findings underscore the need for transparent testing protocols to ensure fair competition between proprietary and open-source AI systems.
The Leaderboard Illusion – An Expert Overview
"The Leaderboard Illusion" (2504.20879) critically examines the systematic biases in Chatbot Arena, a widely adopted leaderboard for evaluating AI models. This essay reviews the paper's methodology, findings, and recommended solutions, providing insights for fellow researchers.
Introduction to Benchmarks and Leaderboards
Benchmarks have long been instrumental in guiding machine learning development, shaping the trajectories of research and resource allocation [church_2017, koch2024protoscience]. As LLMs and other generative AI technologies gain prominence, the significance of leaderboards has escalated dramatically, with industry and academia relying on them to gauge model performance in real-world applications.
Chatbot Arena, launched in 2023, rapidly gained traction as the go-to platform for generative AI evaluation. Its model comparison mechanism utilizes human-driven pairwise comparisons, generating Arena scores underpinned by the Bradley-Terry (BT) model, which estimates skill levels based on paired comparisons.
However, the reliance on a central benchmarking system introduces potential risks, such as overfitting to leaderboard-specific nuances rather than broader AI capabilities (Figure 1). These concerns raise questions about the reliability of the rankings generated on this platform.
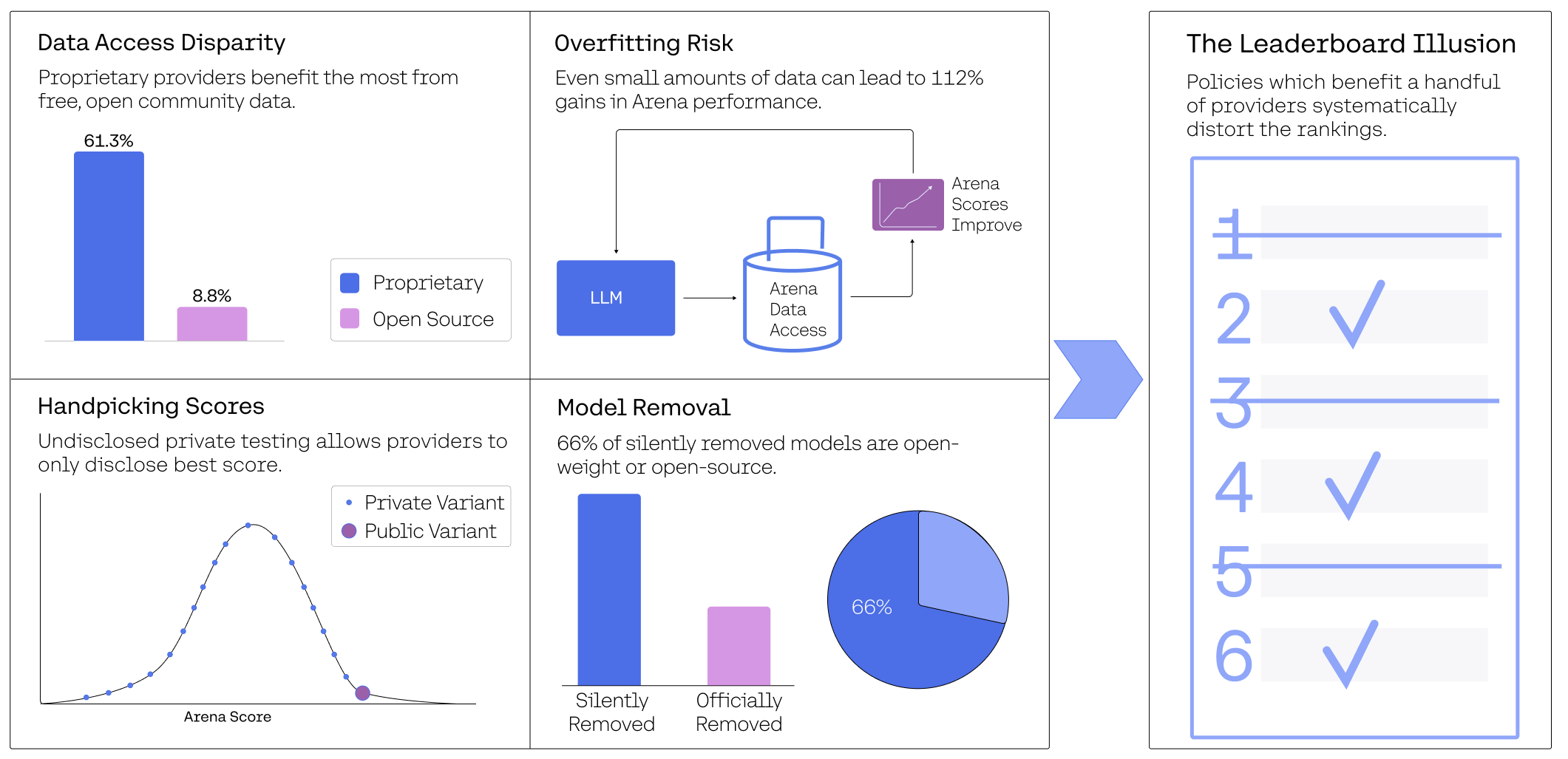
Figure 1: Overview of key insights.
Methodology and Evaluation Metrics
The examination relies on data sourced from 2 million battles, auditing 42 providers and 243 models on the Chatbot Arena platform from January 2024 to March 2025. The core metric, the Arena Score, is a normalized derivation of the Bradley-Terry (BT) model [bradley1952rank]. This model estimates skill levels through probabilistic pairwise comparisons. Its effectiveness presumes several key assumptions, including unbiased sampling and a well-interconnected comparison network, which are critical for consistent and reliable rankings.
Impact of Private Testing and Selective Retraction
Significant bias emerges from undisclosed private testing practices, wherein a select few providers benefit from the ability to privately test numerous model variants before public release, subsequently maximizing their visible scores through selective disclosure, thereby violating the non-degeneracy and unbiased sampling assumptions of the Bradley-Terry model.
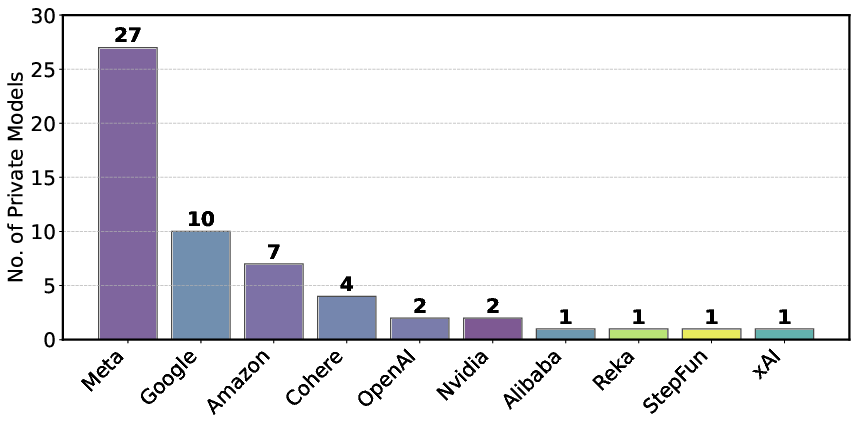
Figure 2: Number of privately-tested models per provider based on random-sample-battles.
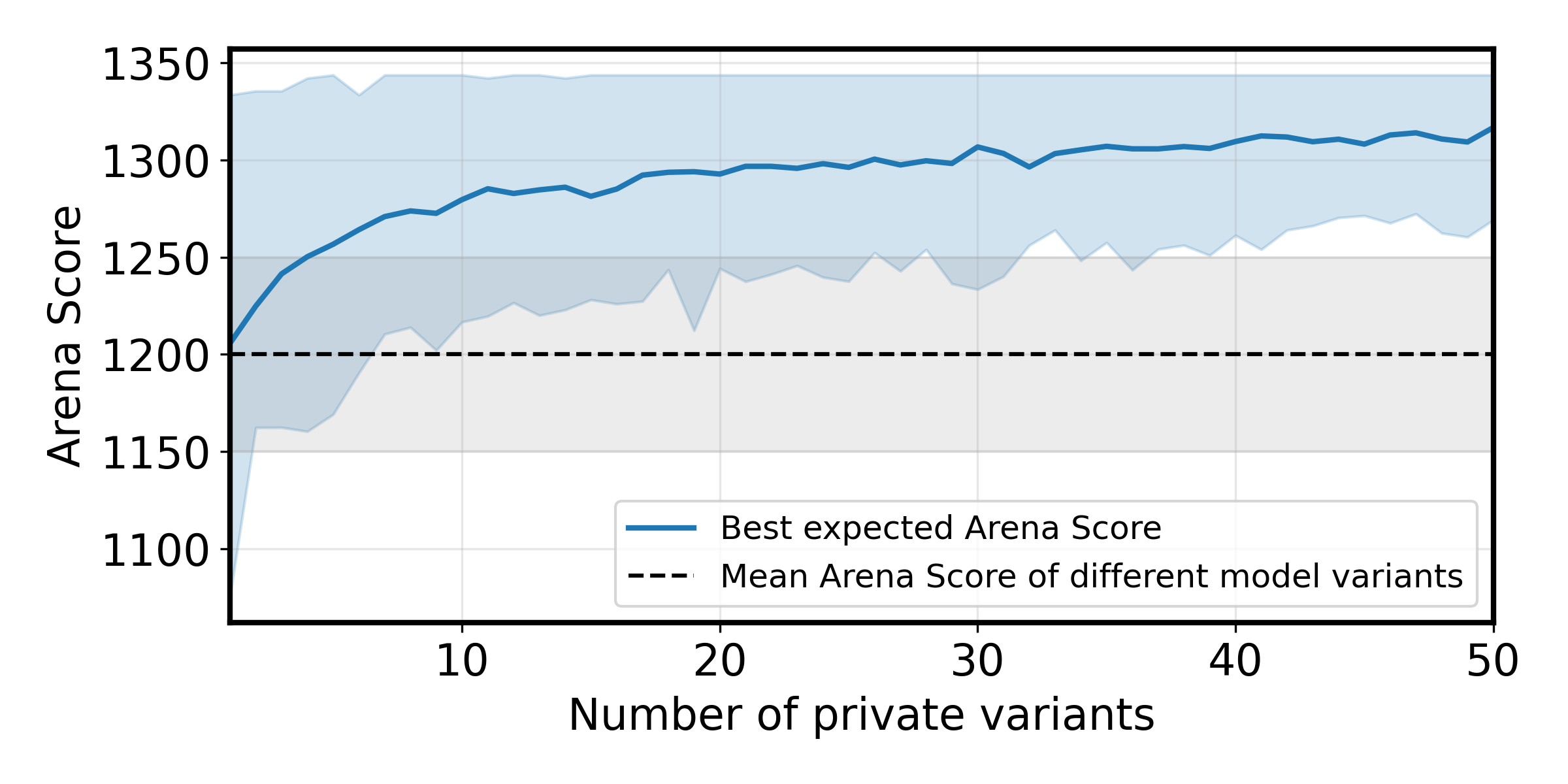
Figure 3: Impact of the number of private variants tested on the best Expected Arena Score.
Notably, real-world experiments confirm these theoretical simulations. Identical checkpoints of the Aya-Vision-8B model yielded noticeably different Arena Scores (1069 vs. 1052), demonstrating that even conservative private testing variations enable meaningful scoreboard manipulation.
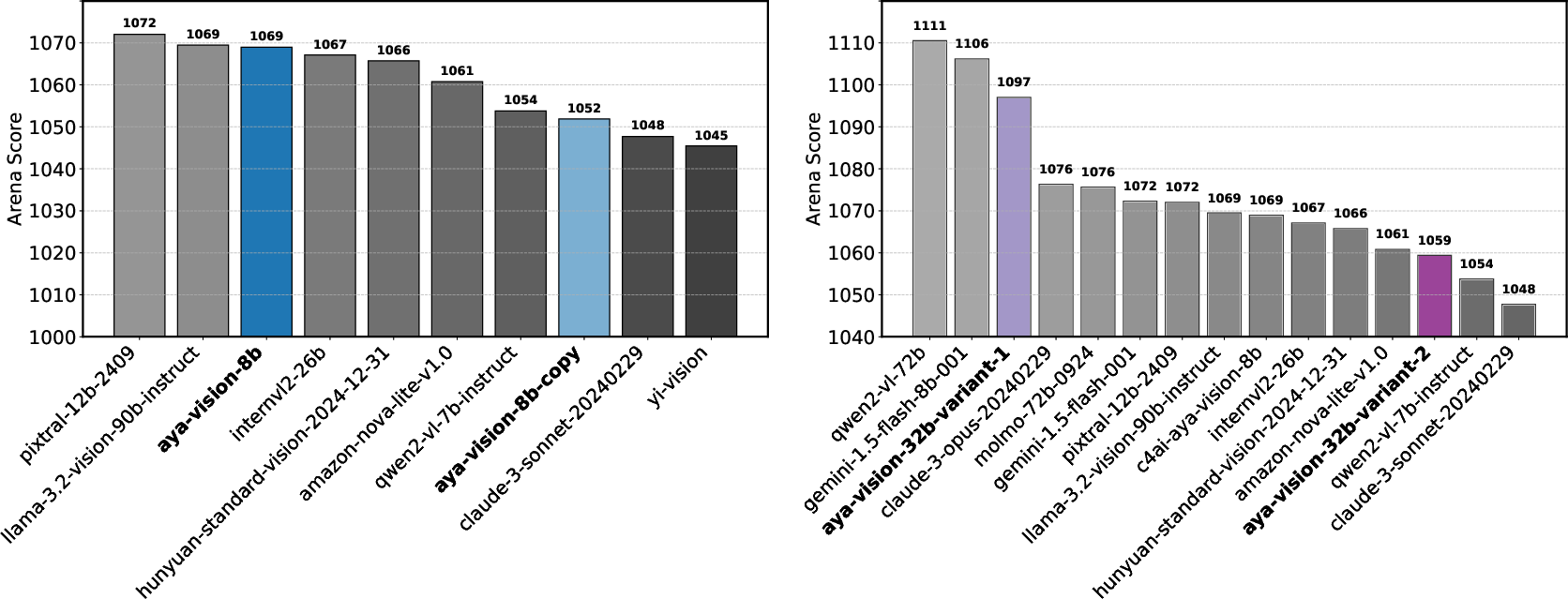
Figure 4: Allowing retraction of scores allows providers to skew Arena scores upwards.
Data Access Disparities and Overfitting
The analysis reveals remarkable disparities in the access to data, with proprietary model providers such as OpenAI and Google receiving approximately 19-20% of all test prompts (Figure 5). In contrast, 83 open-weight models collectively receive just 29.7% of the Arena's data, highlighting the inequities in data distribution that favor proprietary providers.
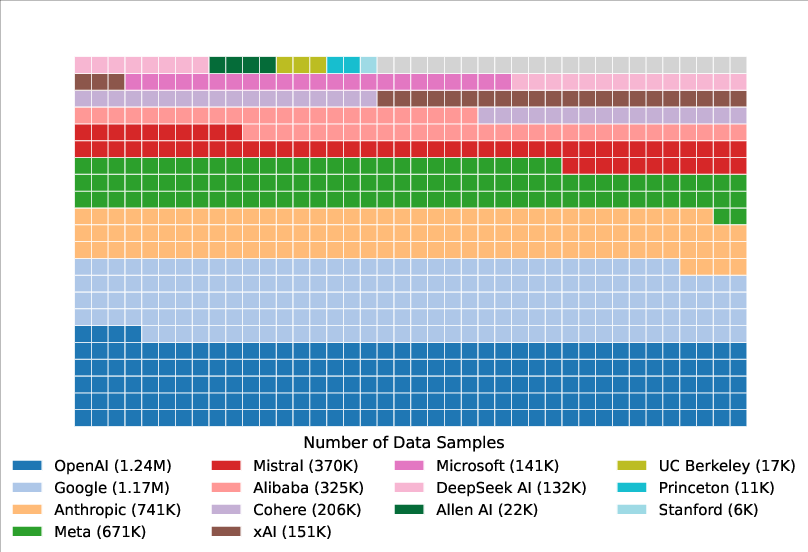
Figure 5: Data availability to model providers.
This uneven data distribution, combined with the practice of submitting and strategically retracting scores for multiple private models (Figure 2), leads to notable overfitting to the Arena's evaluation scheme, as evidenced by substantial performance advantages on Arena-specific tasks.
Figure 2: Number of privately-tested models per provider based on random-sample-battles (January--March 2025).
A further study using Arena data in a supervised fine-tuning mixture confirms performance gains up to 112% on ArenaHard, underscoring the outsized influence of Chatbot Arena data on model performance improvements.
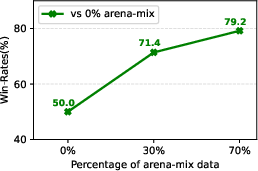
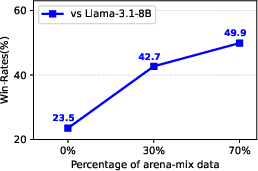
Figure 6: Use of Chatbot Arena dataset significantly improves win-rates on ArenaHard.
Discussion on Model Deprecation
Model deprecation—a necessary maintenance practice—occurs disproportionately across model categories. Open-weight and fully open-source models experience higher rates of deprecation (Figure 7), exacerbating data access imbalances and thereby exasperating the performance discrepancy.
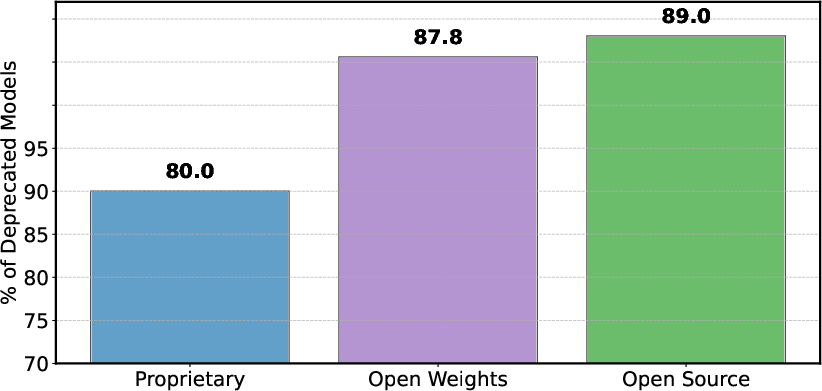
Figure 7: Share of proprietary and open models that either officially deprecated or inactive on the arena based on leaderboard-stats during the period March 3rd-April 23rd, 2025.
Premature model removal under evolving prompt distributions can lead to inaccuracies, as shown in Figure 8, where changes in task distribution and unchecked deprecations produced divergent and unreliable model rankings.
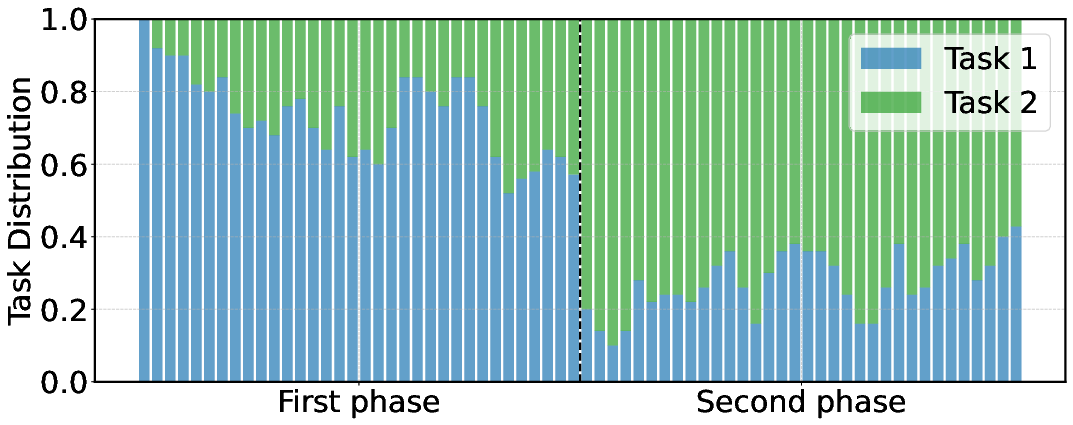
Figure 8: Impact of evolving task distributions and model deprecation on model rankings.
Combining deprecation with biased data access practices compromises the reliability of the overall ranking structure on Chatbot Arena.
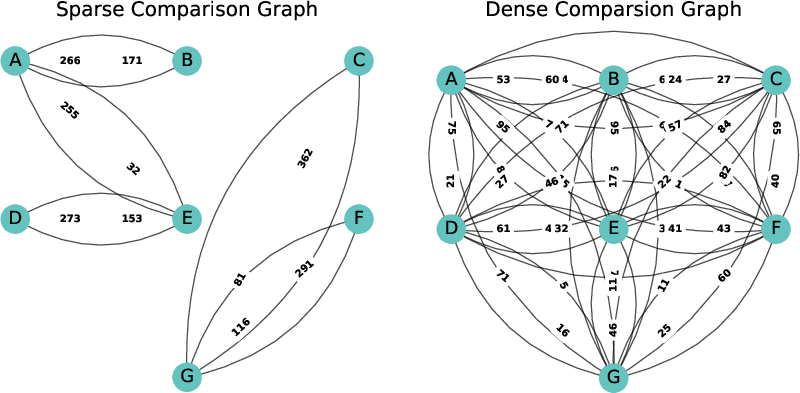
Figure 9: Impact of comparison graph sparsity on model rankings.
Conclusion
"The Leaderboard Illusion" illuminates significant vulnerabilities in the current state of Chatbot Arena's leaderboard methodology and policies. The work emphasizes the inherent challenges in maintaining a fair evaluation framework amidst preferential treatments and dynamic test environments. The study underscores the necessity for transparent and equitable practices, especially for a community-driven benchmark like Chatbot Arena. Essential recommendations include enforcing transparent limits on private testing, eliminating score retraction, and ensuring fair sampling and deprecation practices to maintain a valid and equitable ranking mechanism.
The findings in this analysis have broad implications for the benchmarking of LLMs and generative AI models at large. As AI continues to advance and capture interest across multiple sectors, the efficacy, transparency, and integrity of evaluation platforms like Chatbot Arena are imperative in reflecting meaningful progress. Failure to address these concerns could further widen existing disparities and lead to adverse gaming of evaluation systems at the expense of genuine advancements in AI capabilities.
```
Figures:
Figure 1: Overview of key insights. Chatbot Arena has become the de facto standard for comparing AI models, but our analysis reveals several policies that favor a select few providers and undermine ranking reliability.
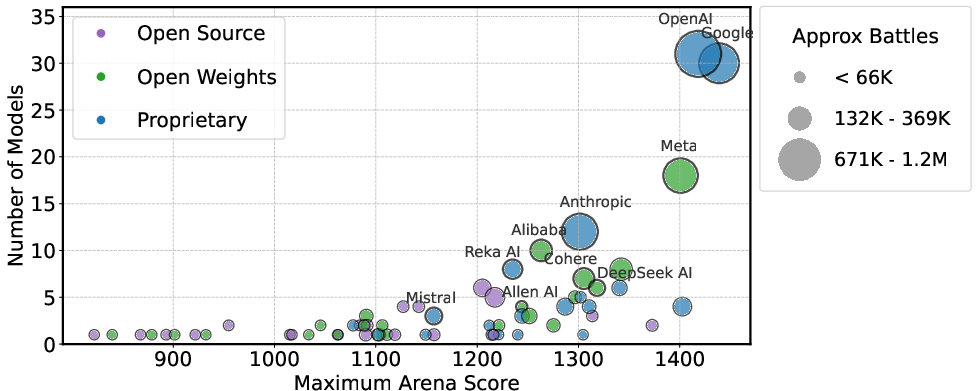
Figure 10: Number of public models vs. maximum arena score per provider. Marker size indicates total number of battles played.
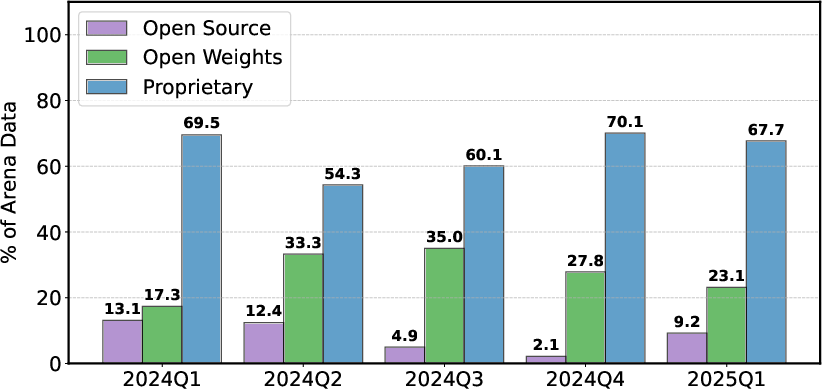
Figure 11: Volume of Arena battles involving proprietary, open-weight, and fully open-source model providers from January 2024 to March 2025, based on leaderboard-stats. Proprietary models consistently received the largest share of data---ranging from 54.3\% to 70.1\%. Open-weight and fully open-source models receive significantly less data, in some cases receiving less than half the amount of data as proprietary developers.
Figure 5: Data availability to model providers. We observe large differences in data access between providers, with 61.4\% of all data going to proprietary providers.
Figure 2: Number of privately-tested models per provider based on random-sample-\battles (January--March 2025). Meta, Google, and Amazon account for the highest number of private submissions, with Meta alone testing 27 anonymous models in March alone.
Figure 3: Impact of the number of private variants tested on the best Expected Arena Score.
Figure 4: Allowing retraction of scores allows providers to skew Arena scores upwards. We run a real-world experiment to measure the benefits of private testing. We show that it is possible to increase Arena scores even in the most conservative case of identical checkpoints, and further amplify the difference by strategically testing different checkpoints. Left: Identical Checkpoints. Arena Scores for Aya-Vision-8B yield different Arena scores (1069 vs. 1052). Right: Strategically Selected Checkpoints. Arena Scores for two different variants of Aya-Vision-32B, which were both considered high-performing final round candidates according to internal metrics. We observe large differences in final scores (1097 vs. 1059) for the two different model variants.
Figure 6: Increasing the amount of arena data in a supervised fine-tuning mixture significantly improves win-rates of the resulting model against both the model variant where no Chatbot Arena data is used and also Llama-3.1-8B.
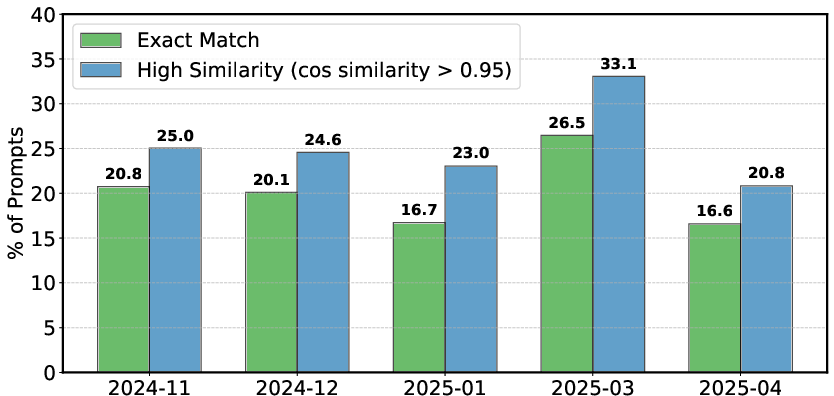
Figure 12: Monthly prompt duplication rates.
Figure 7: Share of proprietary and open models that either officially deprecated or inactive on the arena based on leaderboard-stats during the period March 3rd-April 23rd, 2025. Overall, open-weight and fully open-source models are more likely to become deprecated or inactive compared to proprietary models.
Figure 8: Impact of evolving task distributions and model deprecation on model rankings. This deprecation causes Scenario II to produce a completely different ranking over models as compared to Scenario I.
Figure 9: Rankings for models diverge from the gold rankings when the comparison graph is sparse.