- The paper’s main contribution is applying sparse-to-sparse training to diffusion models to enhance both training and inference efficiency.
- It introduces three methods—Static-DM, RigL-DM, and MagRan-DM—that adjust sparsity dynamically, achieving optimal sparsity levels between 25-50%.
- Experimental results demonstrate a 10% reduction in FLOPs with maintained or improved FID scores across datasets, highlighting significant efficiency gains.
Sparse-to-Sparse Training of Diffusion Models
Introduction
The paper "Sparse-to-Sparse Training of Diffusion Models" (2504.21380) presents a novel approach to enhancing the efficiency of diffusion models (DMs) by applying sparse-to-sparse training techniques. Diffusion models are renowned for their outstanding performance in generative tasks such as image synthesis, but their computational intensity remains a significant challenge. Unlike previous efforts predominantly focused on improving inference speed, this work pioneers the application of sparse-to-sparse training directly to the training phase, thus addressing both training and inference efficiency simultaneously.
Methodology
The study introduces three methods: Static-DM, RigL-DM, and MagRan-DM, which vary in how they apply sparsity during training. Static-DM uses a fixed, predefined sparsity, while RigL-DM and MagRan-DM dynamically adjust sparsity patterns during training based on different regrowth criteria. The experiments involve two contemporary diffusion models: Latent Diffusion for continuous, pixel-level data and ChiroDiff for discrete, spatiotemporal sequence data, across several datasets. Notably, the paper identifies optimal sparsity levels (25-50%) and methodologies that maintain or even enhance model performance compared to dense counterparts.
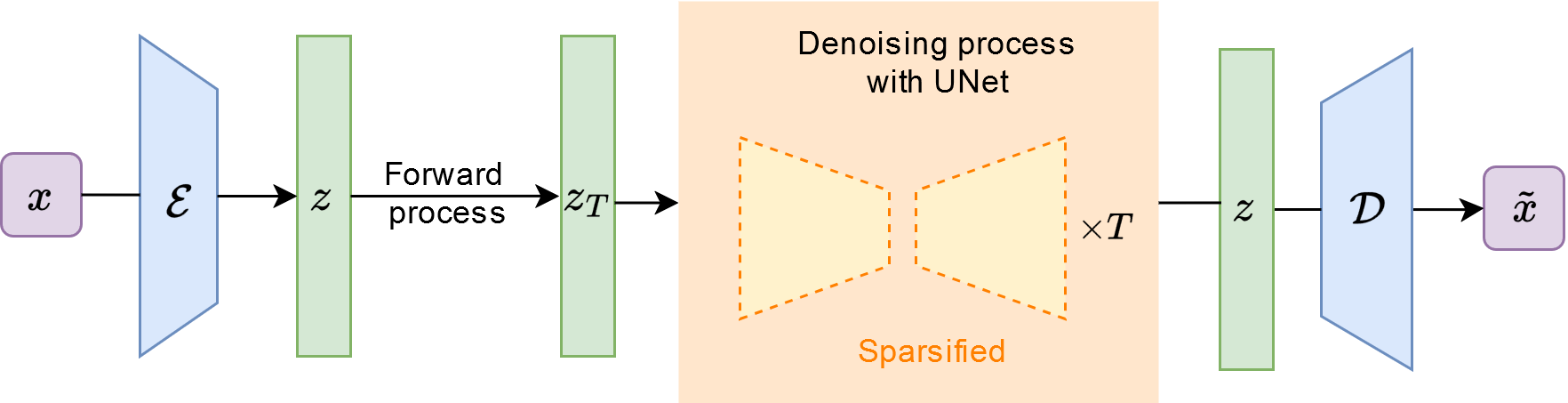
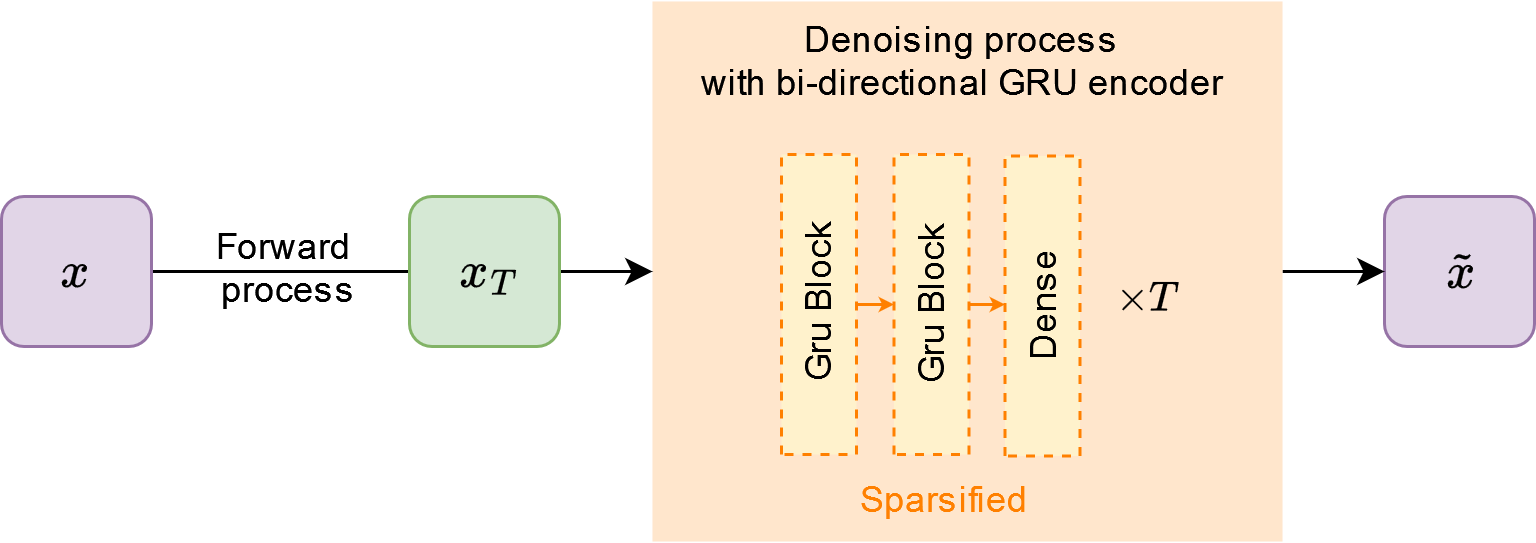
Figure 1: Sparsification of Latent Diffusion.
Experimental Results
The experiments demonstrate that sparse DMs can achieve comparable, and occasionally superior, performance to dense DMs while significantly reducing the number of trainable parameters and computational costs. Specific configurations, such as RigL-DM with a 25% sparsity level, show a reduction in FLOPs by approximately 10%, with maintained or improved FID scores in several datasets. This result suggests notable efficiencies in both memory and computational requirements without compromising generative quality.
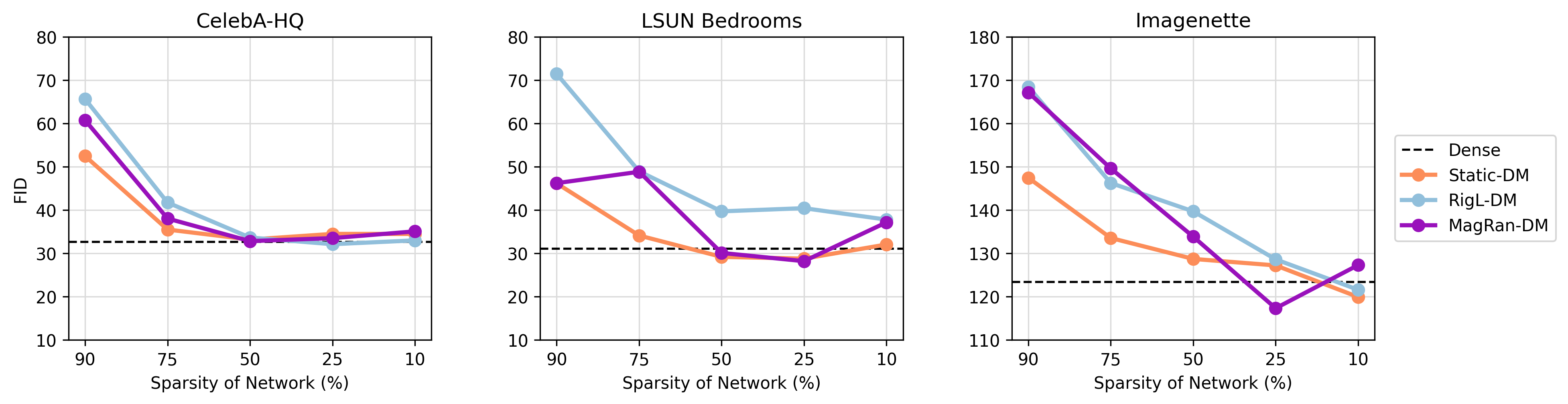
Figure 2: FID score comparisons between Dense, and Static-DM, MagRan-DM and RigL-DM with various sparsity levels, for Latent Diffusion, with prune and regrowth ratio p=0.5.
Implications and Future Directions
The implications of this research are profound for the deployment of generative models in resource-constrained environments. By reducing training and inference costs, sparse-to-sparse training facilitates broader access to high-performance generative models. Future research could explore the impact of different pruning and regrowth strategies, further refinement of sparse network architectures, and potential applications in diverse domains beyond image generation. The findings could also spur hardware innovations that better cater to the necessities of sparse training, as most current hardware is optimized for dense operations.
Conclusion
The presented sparse-to-sparse training frameworks for diffusion models showcase substantial potential for making generative models more computationally accessible. By achieving performance parity or surpassing dense models with significantly reduced resource requirements, this approach not only holds promise for practical applications but also offers a blueprint for future enhancements in DM training efficiency.


Figure 3: Samples from Latent Diffusion trained on LSUN-Bedrooms. The top row presents samples generated by Dense models, whereas the bottom row presents samples generated by the top-performing sparse model.