- The paper introduces Pixel3DMM, using dual vision transformer networks to predict UV-coordinates and surface normals for optimizing 3DMM parameters.
- It achieves a 15% improvement in geometric accuracy over methods like DECA and EMOCA, demonstrating robust performance in posed face reconstruction.
- The study establishes a new benchmark while addressing challenges in identity-expression disentanglement, paving the way for future research.
Overview of "Pixel3DMM: Versatile Screen-Space Priors for Single-Image 3D Face Reconstruction"
The paper presents Pixel3DMM, an innovative approach to address the problem of 3D face reconstruction from a single RGB image by leveraging pixel-aligned geometric cues. This method employs a pair of Vision Transformers (ViTs) that predict per-pixel surface normals and UV-coordinates, using these geometric cues to constrain the optimization of a 3D morphable face model (3DMM). The focus is to advance the robustness and fidelity of 3D face reconstructions, overcoming traditional challenges like depth ambiguities and expression disentanglement.
Methodology
Pixel3DMM Architecture
Pixel3DMM utilizes two vision transformer networks tailored to predict UV-coordinates and surface normals, effectively refining 3D face reconstruction. The foundational elements are drawn from the DINOv2 model, which provides robust latent features. The network architecture extends the standard ViT with a prediction head consisting of transformer blocks and up-convolutions to achieve high-resolution output predictions.
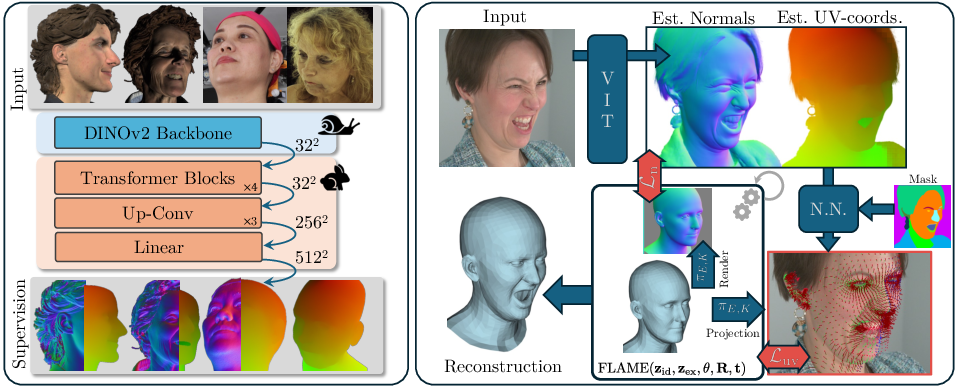
Figure 1: Method Overview: Pixel3DMM consists of (a) learning pixel-aligned geometric priors (left) and (b) test-time optimization against predicted UV-coordinates and normals (right).
Training and Data Preparation
The model is trained using high-quality 3D datasets, namely NPHM, FaceScape, and Ava256, registered against the FLAME model topology. Techniques such as non-rigid registration and random sampling of light and camera parameters enhance the model's robustness. This results in a comprehensive dataset encompassing diverse identities and expressions.
Fitting Strategy
The 3DMM parameters are optimized through a combination of surface normal and UV-coordinate predictions, utilizing both 2D vertex loss and a loss function based on estimated normals. This optimization is applied not only to single images but also extended to monocular video sequences, ensuring smoothness and fidelity across frames.
Benchmark Development
To evaluate the effectiveness of Pixel3DMM, a new benchmark was introduced using the multi-view video dataset NeRSemble. This benchmark is designed to test both posed and neutral geometries, offering a detailed evaluation protocol that includes metrics such as L1 and L2 Chamfer distances, normal consistency, and recall rates.

Figure 2: 3D Face Reconstruction Benchmark Analysis. We show the 5 most diverse images from each benchmark dataset, as measured by the expression codes of EMOCA.
Experimental Results
Pixel3DMM demonstrates superior performance in 3D face reconstruction tasks, significantly outperforming existing methods such as DECA and EMOCA in posed scenarios, with a 15% improvement in geometric accuracy. The results on the neutral task, however, highlight challenges in disentangling identity and expression when relying on optimization-based approaches.
Figure 3: Qualitative Comparison (Posed): We show overlays of the reconstructed meshes to judge the reconstruction alignment.
Implications and Future Work
Pixel3DMM marks a step forward in single-image 3D face reconstruction by integrating advanced geometric priors within the optimization process, however, challenges remain in enhancing the rapidity and scalability of these methods, particularly for real-time and generative applications. Future work could explore integrating multi-view information into the foundational architecture or refining the optimization strategies to improve identity-expression disentanglement further.
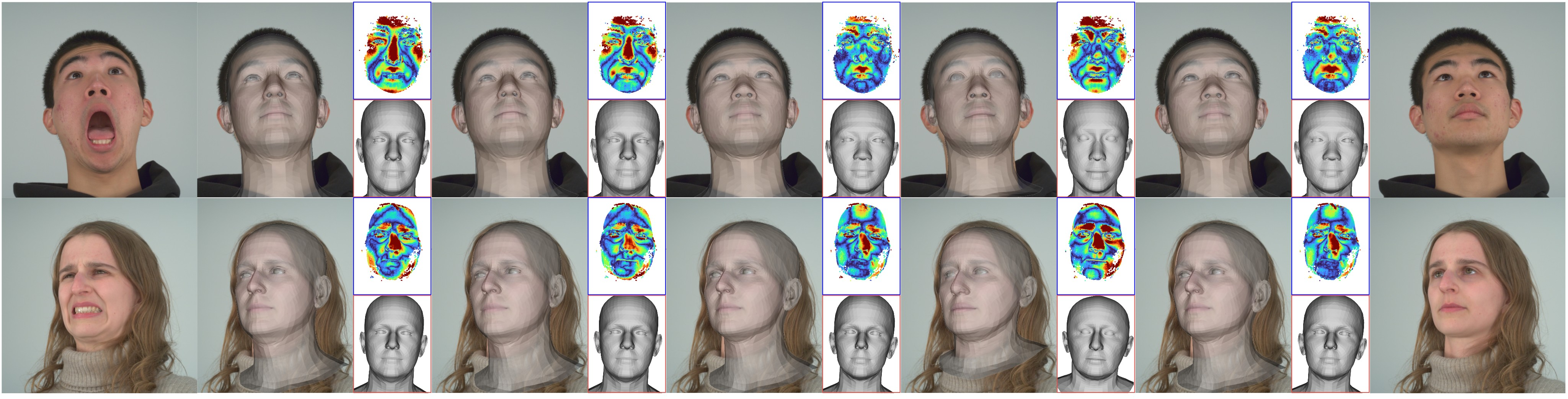
Figure 4: Qualitative Comparison (Neutral): Alignment of the neutral prediction against the neutral image and scan of a person.
The introduction of new benchmarks provides a pathway for more nuanced comparisons across methodologies, especially in facets of posed geometry reconstruction and underlying disentanglement strategies.
Conclusion
The paper introduces a novel method for single-image 3D face reconstruction that significantly advances the fidelity and applicability of face modeling techniques. Pixel3DMM leverages pixel-aligned geometric priors to refine 3DMM parameter estimation, establishing new standards against which future technologies in this domain can be assessed. The comprehensive use of public datasets and efficient training setups encourages continued exploration and innovation in related areas.