- The paper demonstrates ARTI, a framework that integrates agentic reasoning, reinforcement learning, and external tool use to enable dynamic decision-making in LLMs.
- It employs the GRPO algorithm with outcome-based reward learning, achieving a 22% performance boost on AMC math tasks compared to baseline models.
- The framework enhances multi-turn function calling with adaptive tool selection and iterative self-correction, improving handling of long-context tasks.
Agentic Reasoning and Tool Integration (ARTI) is a framework aimed at enhancing the capabilities of LLMs by integrating dynamic agentic reasoning with reinforcement learning (RL) and external tool use. This approach addresses the limitations of LLMs which rely solely on static internal knowledge and text-based reasoning, especially in complex real-world problem-solving scenarios.
Methodology
Framework and Architecture
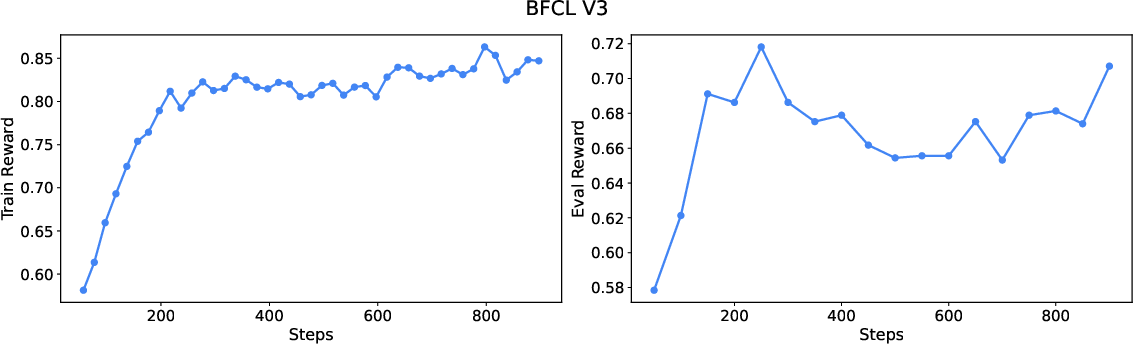
ARTI unifies agentic reasoning, RL, and tool integration, allowing LLMs to autonomously decide when, how, and which tools to invoke within reasoning chains. The framework employs outcome-based reward learning to develop strategies for tool use and environment interaction without needing step-level supervision.

Figure 1: The architecture. Agentic reasoning is achieved by interleaving text-based thinking, tool queries, and tool outputs, enabling dynamic coordination of reasoning, tool use, and environment interaction within a unified framework.
Agentic Reasoning Process
The process involves the interleaving of internal text reasoning, tool invocation, and tool-output integration in reasoning rollouts. This structure allows the model to coordinate effectively between its internal thought process and external tool use (Figure 2).
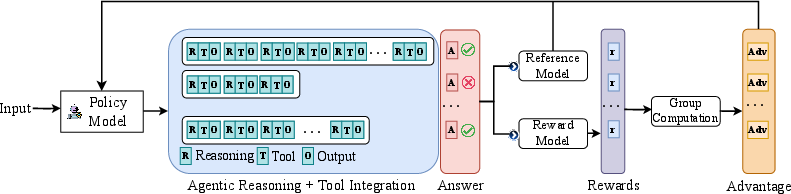
Figure 2: Overview of the methodology. The framework illustrates how reasoning rollouts alternate between internal thinking, tool use, and environment interaction, with outcome-based rewards guiding learning. This enables the model to iteratively refine its reasoning and tool-use strategies through reinforcement learning.
Reinforcement Learning Algorithm
To train agentic LLMs with tool integration, ARTI utilizes a Group Relative Policy Optimization (GRPO) approach. GRPO leverages outcome-based rewards without step-level feedback, allowing models to optimize tool interactions efficiently. It employs a loss masking strategy to focus the learning process on model-generated reasoning rather than deterministic tool outputs.
Experimental Evaluation
Complex Mathematical Reasoning
ARTI achieves substantial improvements in complex mathematical reasoning tasks, particularly on benchmarks like AMC, AIME, and MATH-500.
- Performance Gains: Qwen2.5-14B-Instruct + ARTI outperformed baselines, achieving a 22% improvement on AMC tasks over base models.
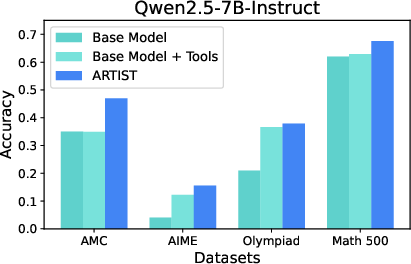
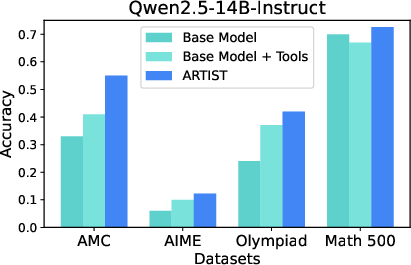
Figure 3: Qwen2.5-7B-Instruct: Performance on Math datasets.
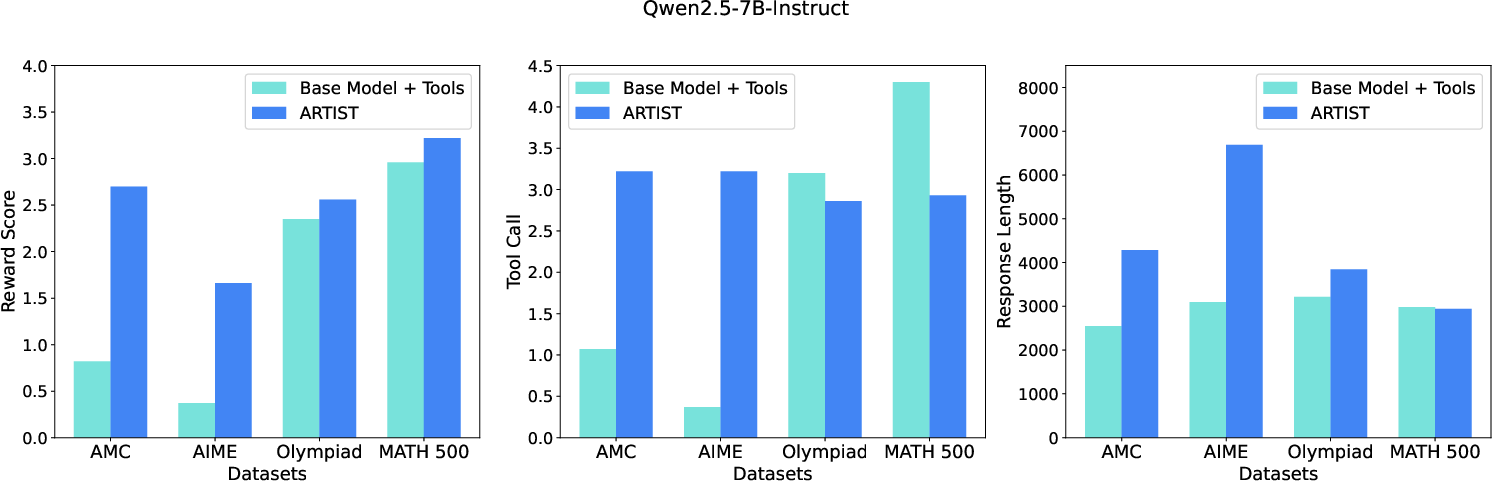
Figure 4: Average reward score, Tool call and the response length metric across all math datasets.
Multi-Turn Function Calling
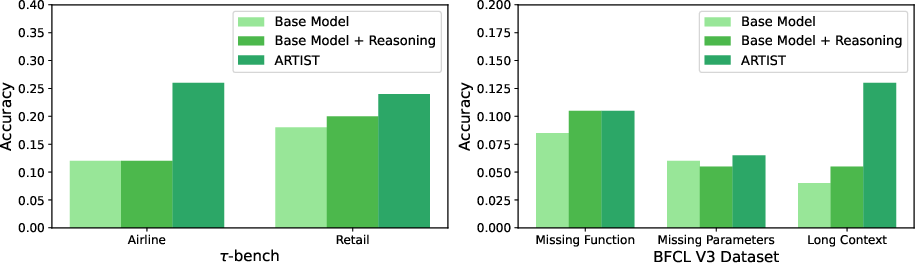
On multi-turn function calling tasks, such as those in the tau-bench and BFCL v3 datasets, ARTI demonstrated significant accuracy improvements, highlighting its agentic capabilities for orchestrating tool use in dynamic, multi-turn environments.
Implications and Future Work
The integration of RL with agentic reasoning marks a shift in LLM capabilities, facilitating robust problem-solving in diverse and complex environments. ARTI not only enhances performance metrics but also improves model interpretability and adaptability. Future developments could explore more diverse tool integrations and broader applicability across various domains, refining ARTI to support even more complex tasks and dynamic real-world challenges.
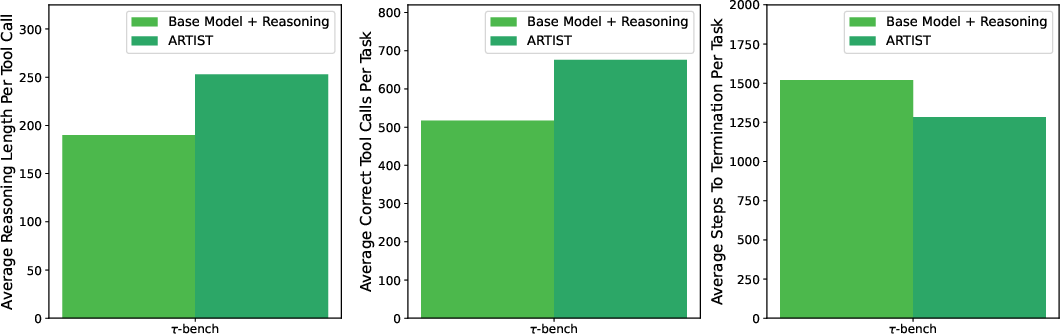
Figure 7: Metrics Analysis for Multi-Turn Function Calling on tau-bench.
Conclusion
Agentic Reasoning and Tool Integration via Reinforcement Learning offers a promising advancement in LLMs, bridging the gap between static inference and dynamic, tool-augmented reasoning. This framework’s ability to strategically integrate external tools enhances problem-solving effectiveness, adaptability, and interpretability, setting a new standard for real-world AI applications.