- The paper introduces CompleteP, a novel parameterization strategy that transfers hyperparameters across model depths to enhance compute efficiency.
- It demonstrates a 12-34% improvement in compute savings by optimizing learning rates and weight initialization for various transformer architectures.
- The approach simplifies model tuning and adapts to hardware constraints, paving the way for scalable and sustainable deep learning deployments.
The paper "Don't be lazy: CompleteP enables compute-efficient deep transformers" provides an in-depth exploration on the parameterization strategies for training LLMs, focusing primarily on enhancing compute efficiency by superior hyperparameter (HP) transfer across model depth and width variations.
Introduction to CompleteP
The increasing computational demand of training large-scale deep learning models has motivated the need for strategic parameterization approaches. The paper introduces CompleteP, a unique parameterization designed to transfer optimal base model HPs effectively as model architecture scales. CompleteP achieves what is termed depth-wise HP transfer, allowing practitioners to sidestep repetitive and computationally expensive HP re-tuning. The concept hinges upon managing HPs such as learning rate and weight initialization across varying model sizes and avoids the pitfalls associated with the "lazy learning" regime, where model layers primarily learn linearized features.
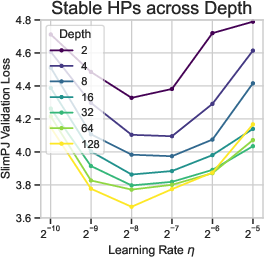

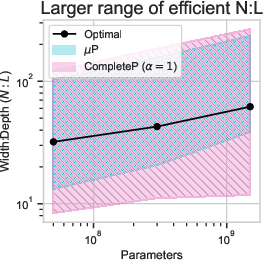
Figure 1: We introduce CompleteP, which offers depth-wise HP transfer (Left), FLOP savings when training deep models (Middle), and a larger range of compute-efficient width/depth ratios (Right).
Theoretical Framework and Empirical Justifications
CompleteP achieves substantial computational savings, reportedly enhancing efficiency by 12-34% over prior state-of-the-art strategies. The foundation of CompleteP's effectiveness lies in its robust theoretical underpinnings coupled with empirical validation:
- Depth-wise HP Transfer: CompleteP transfers learning rate and weight initialization HPs consistently across varying depths of models, maintaining or improving model performance without needing to re-tune for deeper configurations.

Figure 2: Depth-wise HP transfer, with 300M training tokens. Top: Learning rate (eta) transfer. Bottom: Initialization standard deviation (σinit) transfer.
Methodological Innovations
CompleteP's methodological strength lies in its simplicity and effectiveness in various architectural configurations of transformer models. Key innovations include:
- Adjustments in variance and learning rates to stabilize training as depth increases.
- Incorporation of LayerNorm and bias adjustments to ensure stable training dynamics.
- Scaling laws for a broader range of model shapes, facilitating more tailored architectures to specific computational resources.
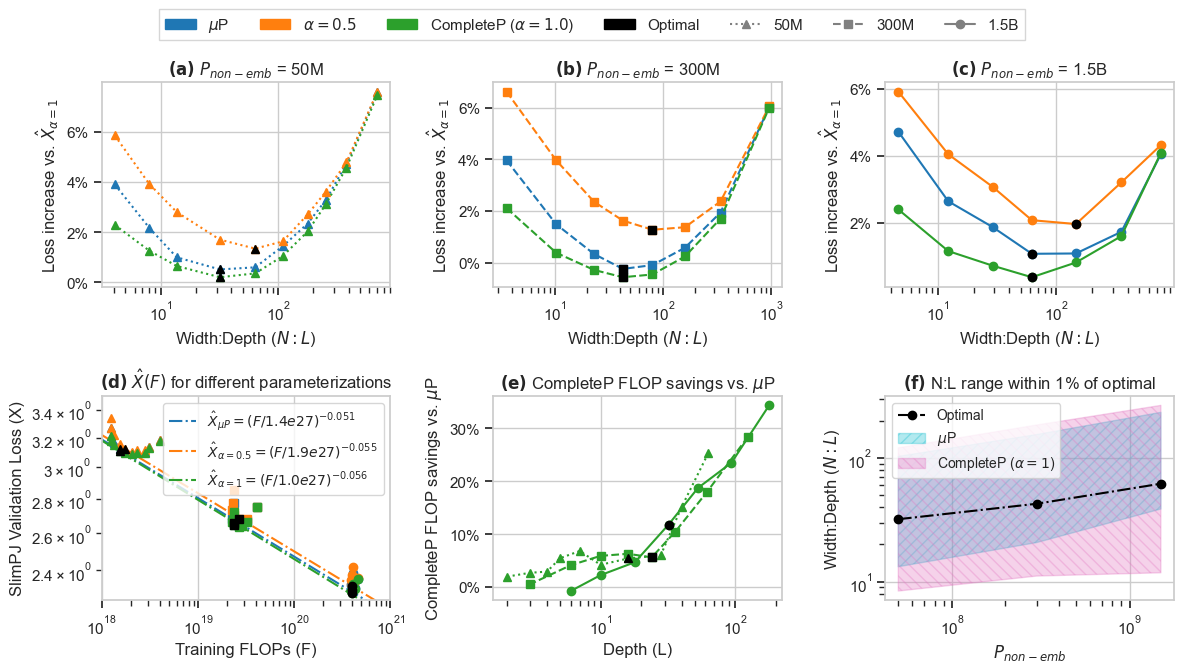
Figure 4: Optimal N:L across model sizes. (a)-(c) For models of size {50M,300M,1.5B}. (f) CompleteP (α=1) enables a larger range ofN:L that are within 1% of optimal.
Discussion and Implications
CompleteP represents a significant improvement in compute-efficient model training, especially pertinent as model architectures continue to grow in scale. By enabling comprehensive HP transfer, CompleteP potentially reduces the environmental and economic costs associated with LLM training. The theoretical and practical insights provided also pave the way for future research into more generalized and adaptive parameterization strategies, extending possibly beyond transformers to other architectures.
In terms of practical deployment, CompleteP offers a framework that could be adapted to various hardware settings, ensuring optimal use across both training and inference phases. This adaptability may extend the applicability of advanced deep learning models into domains constrained by compute resources.
Conclusion
The exploration into CompleteP marks a critical step towards optimizing training regimes for deep learning models by harnessing parameterization strategies that transcend traditional limitations. The empirical evidence and theoretical rigor highlighted in this paper establish a path forward for developing even more efficient and scalable AI systems. By mitigating the computational costs associated with deep model training, CompleteP not only contributes to the efficiency of AI systems but also addresses broader implications related to sustainable AI research practices.