- The paper introduces ReplaceMe, a method that replaces multiple transformer blocks with a linear transformation to compress large language models.
- It employs cosine and L2 distance metrics for effective layer selection, achieving up to 25% size reduction while maintaining ~90% performance.
- Extensive experiments on architectures like LLaMA and Falcon demonstrate that ReplaceMe avoids costly retraining while ensuring deployment efficiency.
Introduction
The paper "ReplaceMe: Network Simplification via Depth Pruning and Transformer Block Linearization" introduces a novel method named ReplaceMe, which targets the optimization of LLMs through a generalized training-free depth pruning technique. This method achieves compression by replacing selected transformer blocks with a linear transformation, effectively reducing model size while maintaining performance. This approach addresses the computational and memory limitations often associated with deploying LLMs, making them more suitable for environments with limited resources.
Methodology
ReplaceMe operates under the hypothesis that a series of transformer blocks can be approximated by a single linear transformation. By removing these blocks and inserting a linear transformation estimated via a small calibration dataset, the method achieves significant model compression without requiring post-pruning retraining. The linear transformation is integrated seamlessly with the remaining model weights, allowing for simplified deployment.
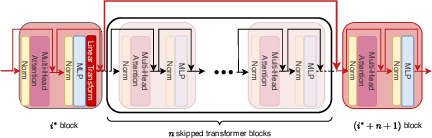
Figure 1: ReplaceMe compresses and accelerates LLMs by bypassing a contiguous sequence of transformer blocks (illustrated by the red line) while preserving model performance.
Layer Selection
The approach begins by identifying which layers to prune based on their significance, assessed via the cosine distance between activation outputs of transformer blocks. This distance is particularly effective for identifying layers that can be removed with minimal impact on model performance.
To approximate the pruned blocks, the paper details two primary objectives for estimating the linear transformation: L2-distance and cosine distance. The L2 approach results in a closed-form solution, while cosine distance, more effective for identifying unimportant blocks, requires numeric optimization solutions such as Adam. This estimated transformation then replaces the layers, with the aim of preserving key performance metrics like accuracy and response consistency.
The paper explores regularization strategies to further improve the linear transformation's effectiveness, introducing L1 and L2 regularizations to balance performance metrics. Additionally, the methodology extends to support multiple linear transformations for non-consecutive block pruning, enhancing flexibility under higher compression ratios.
Experiments
The paper conducts extensive experiments across various LLM architectures, including LLaMA and Falcon, demonstrating ReplaceMe's competitive performance against state-of-the-art methods that rely on costly post-pruning retraining, such as UIDL and LLM-Pruner.
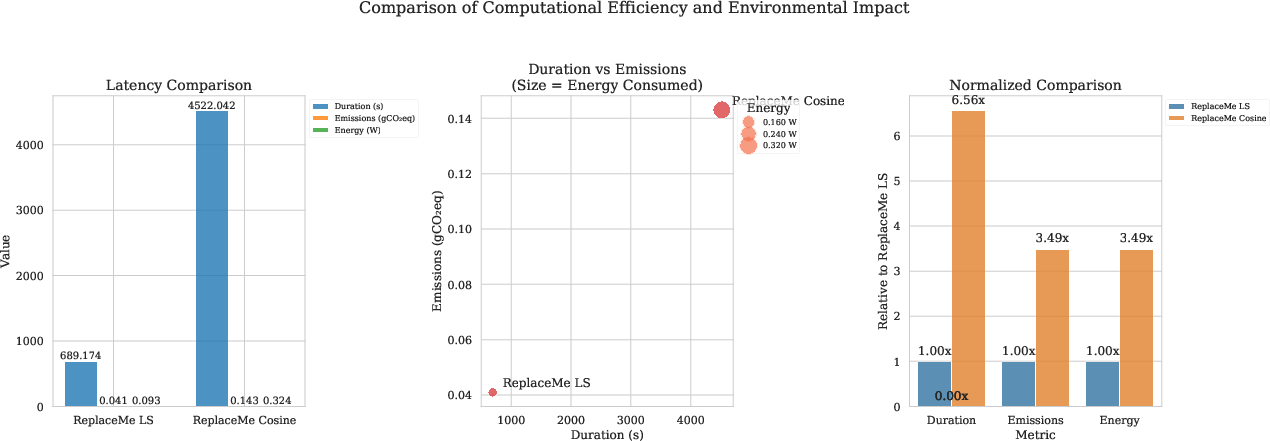
Figure 2: Comparison between LS and Cosine in terms of computation and environmental impact.
The critical trade-offs identified include balancing accuracy retention with compression efficiency. ReplaceMe achieves up to a 25% reduction in size while maintaining approximately 90% of the uncompressed model's performance. The experiments also explore the impact of different calibration datasets and regularization techniques, offering insights on the practical considerations when deploying ReplaceMe in various scenarios.
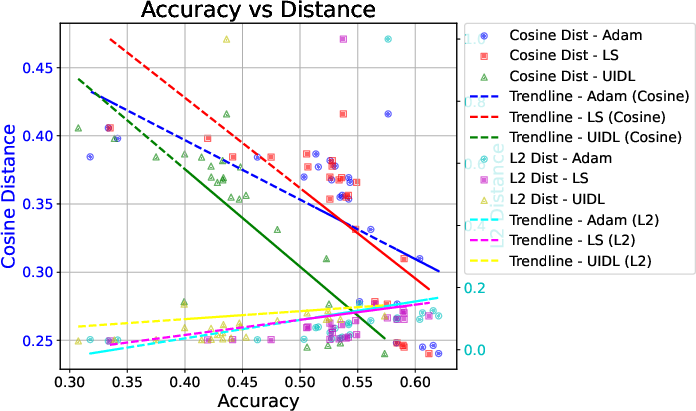
Figure 3: Comparative analysis of distance metrics and predictive accuracy across layer pruning configurations.
Conclusion
ReplaceMe emerges as a potent strategy for LLM compression, allowing significant reductions in model size without sacrificing performance, all without the computational overhead of retraining. Its broader implications suggest that similar techniques could be applied to other neural network architectures, paving the way for more efficient AI models suited for diverse hardware constraints. Further research is expected to refine the method and explore its applicability to a wider range of models and tasks.