- The paper introduces VideoMimic, a real-to-sim-to-real pipeline that enables contextual humanoid control from monocular videos.
- It employs a multi-stage optimization process to reconstruct and align human and scene geometry, ensuring accurate motion retargeting.
- The unified policy, pre-trained on MoCap data and refined via RL, demonstrates robust performance in complex real-world environments.
Visual Imitation Enables Contextual Humanoid Control
Introduction
The paper, "Visual Imitation Enables Contextual Humanoid Control" (2505.03729), presents VideoMimic, a scalable real-to-sim-to-real system that enables a physically embodied humanoid to learn context-aware skills directly from monocular RGB human videos. Unlike previous paradigms that rely heavily on MoCap, hand-crafted rewards, or constrained environments, VideoMimic reconstructs both the human actor and the scene geometry in metric scale, retargets the motion to the robot, and trains a generalist policy in simulation capable of executing complex whole-body skills such as stair climbing, sitting, and terrain traversal in diverse environments.

Figure 1: VideoMimic system overview—a monocular video input produces robust humanoid policies for environment-aware skills, directly transferable from simulation to the real robot.
Real-to-Sim Pipeline
A core technical contribution is the robust scene-aware 4D reconstruction from casually captured monocular videos. The system leverages a multi-stage pipeline: (1) extraction of per-frame SMPL human pose and body shape, (2) 2D keypoint detection and scene depth estimation, (3) joint human-scene optimization to metrically align human and environment, and (4) meshification and gravity alignment of the reconstructed terrain.
The joint metric alignment stage utilizes SMPL body shape priors to resolve scale ambiguity, employing a Levenberg–Marquardt optimization scheme in JAX to minimize both 2D and 3D joint errors, along with a temporal smoothness regularizer. The system supports reshaping to the robot embodiment (e.g., for Unitree G1), providing reference motion and terrain mesh apt for physics-based policy learning.
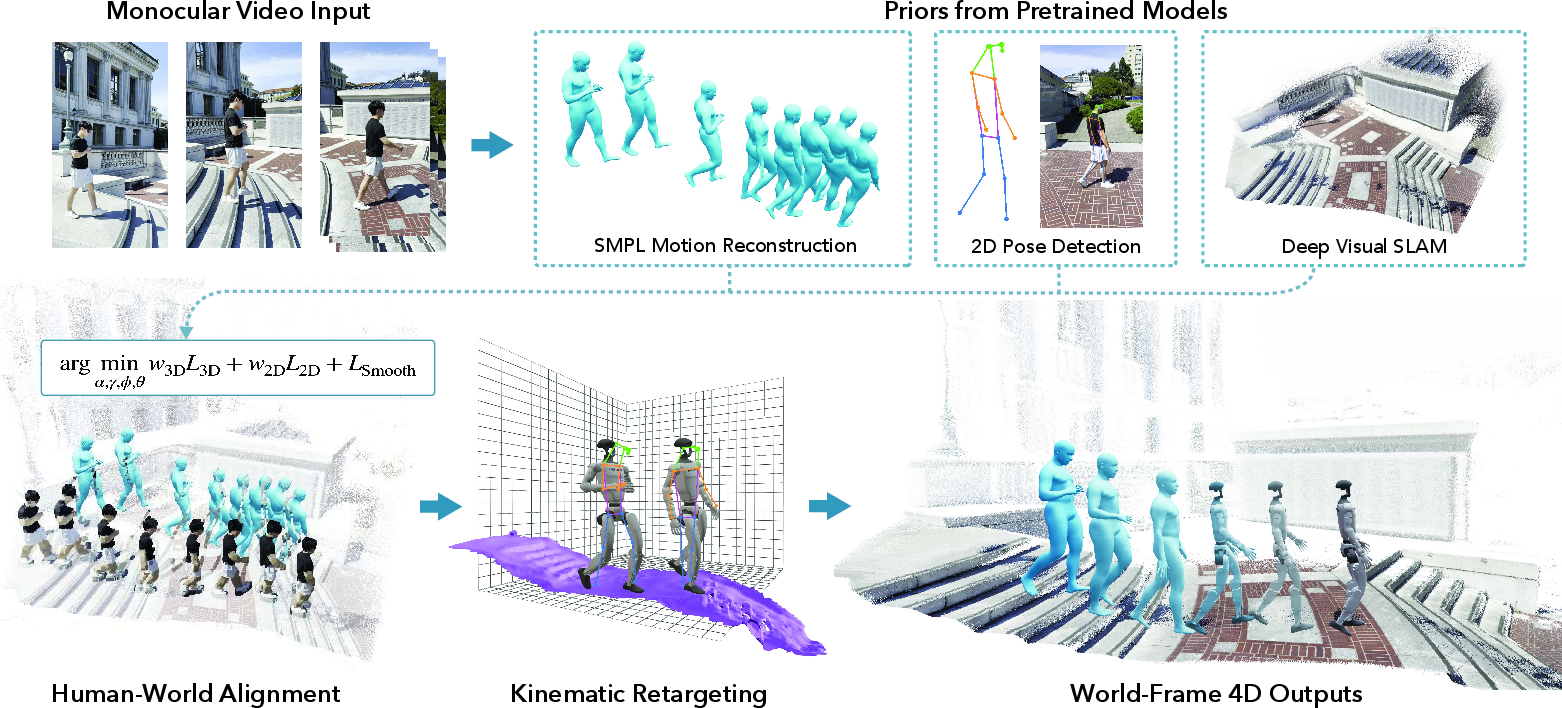
Figure 2: Detailed real-to-sim pipeline: video input yields per-frame human and environment geometry, which is metrically optimized, aligned to gravity, and made simulation-ready.
System versatility is underscored by robust tracking in diverse, unstructured Internet videos, support for multi-human retargeting, and capability for both standard and egocentric (ego-view) RGB-D renderings.
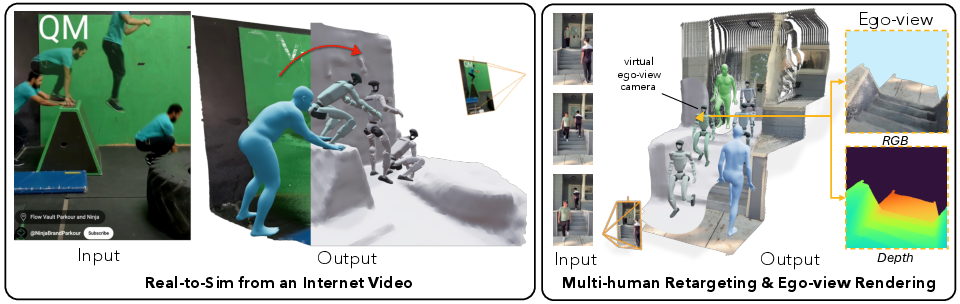
Figure 3: Real-to-sim pipeline qualitative examples: accurate reconstruction and retargeting across complex environments and motion types, including multiple humans and ego-view synthesis.
Policy Learning: From Reference to Generalist Control
The RL pipeline comprises several sequential stages:
- MoCap Pre-Training: Policy is first trained on curated MoCap data to stabilize learning and mitigate the noise in monocular reconstruction.
- Scene-Conditioned Tracking: The policy is exposed to reference motions in their reconstructed environment, with observation of proprioception and local height-map.
- Distillation via DAgger: To deploy on real hardware with sparse sensing, a distilled student policy is trained that only observes proprioception, a fixed-size local height map, and a root-direction vector—removing direct conditioning on reference motion.
- Under-Conditioned RL Finetuning: The distilled policy is further refined via RL, improving generalization and robustness, with increased tolerance for imperfect, noisy references.
Key elements include an explicit focus on scalable reward design (primarily for motion tracking, with minimal hand-crafted priors), strong domain randomization covering friction, noise, delay, and observation dropouts, and deployment-focused observation constraints (matching real available sensors on the robot).
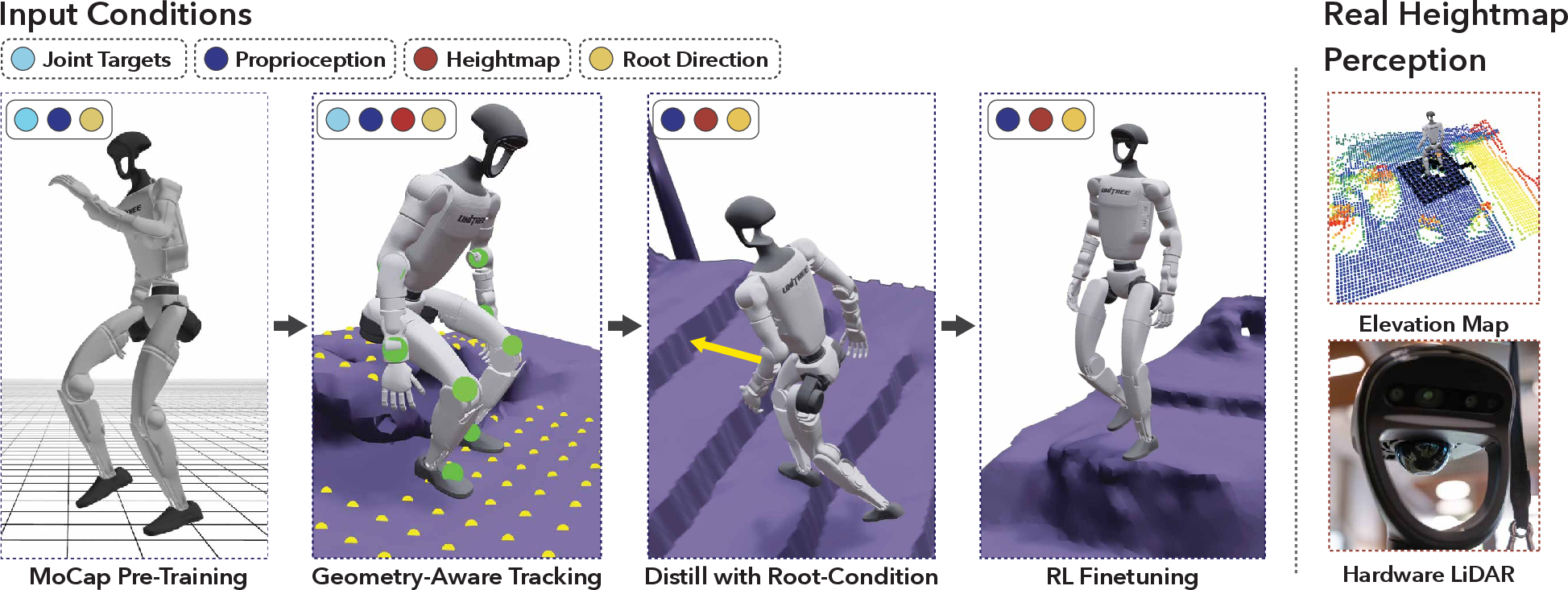
Figure 4: Policy learning pipeline: pretrain on MoCap, track scene-aware video references, perform distillation, and fine-tune to achieve unified contextual control.
Ablation shows that MoCap pretraining is crucial: training from scratch on noisy video references leads to suboptimal controllers that struggle to balance or recover.
Real-World Deployment and Results
The distilled and fine-tuned policy is deployed onboard a 23-DoF Unitree G1 at 50 Hz, using only proprioceptive data and an online LiDAR-based height-map for environmental context. The controller seamlessly produces complex, whole-body behaviors (e.g., stair ascents/descents, sitting and standing in chairs, terrain traversal) with a single model that generalizes across unseen environments—without task-specific supervision or skill selection.
Numerical comparisons on SLOPER4D benchmarks demonstrate that the joint scene-human reconstruction surpasses prior work in human trajectory accuracy (lowest WA/W-MPJPE) and scene geometry (lowest Chamfer Distance).
Qualitative analysis confirms repeatable, robust control under challenging real-world conditions—the robot recovers from foot slips, copes with ambiguous or noisy input, and synthesizes contextually correct behaviors purely based on local sensorimotor input.

Figure 5: Generalist policy deployment: policy robustly performs terrain traversal, stair climbing/descending, and sit-stand actions—all with a unified controller driven solely by environment observation and joystick guidance.
System Capabilities and Versatility
VideoMimic’s reconstruction supports multi-human tracking, dynamic motion, and ego-centric rendering, offering a promising path towards embodied perception and semantics-driven active vision in future extensions.

Figure 6: Ego-view RGB-D rendering—dense point cloud enables realistic first-person sensory input for future vision-conditioned policies.
Evaluation through progressive real-world stages (MoCap tracking, generalist policy, unseen trajectory tracking) further validates robust sim-to-real transfer and generalization.


Figure 7: Real-world evaluation—progressive deployment from MoCap tracking to unified policy tracking unseen trajectories in complex environments.
Limitations and Future Directions
The pipeline, while robust, is limited primarily by the inherent brittleness of monocular human-scene recovery (e.g., scale ambiguity, ghosts and occlusions in low-texture environments, mesh artifacts), nontrivial transfer across embodiment gaps, and limited perceptual bandwidth from low-resolution height-maps. Policy smoothness is occasionally compromised due to modest data scale and reference motion quality.
Addressing these constraints—especially with improved scene dynamics modeling, denser/smarter perceptual inputs, adaptive cost formulations, and richer datasets—will likely close the remaining gap to scalable, high-fidelity context-conditioned humanoid skill learning.
Conclusion
VideoMimic (2505.03729) demonstrates, for the first time, a scalable system for acquiring and deploying contextually conditioned humanoid policies in the wild, directly from monocular human videos. It sets a new standard in real-to-sim-to-real pipelines, highlighting the feasibility of learning robust, repeatable, whole-body contextual skills with only passive video acquisition, minimal reward engineering, and a unified network for varied complex behaviors. This framework paves the way for future developments in scalable visual imitation, multi-agent interaction, and semantics-conditioned embodied AI.