- The paper introduces GSR, a novel rotation technique using grouped Walsh matrices to efficiently reduce quantization errors in low-bit quantization scenarios.
- The paper details a sequency reordering strategy that isolates outlier influences within quantization blocks, achieving a perplexity drop from 20.29 to 11.59 on WikiText-2.
- The paper demonstrates that GSR attains performance comparable to optimization-based methods without retraining, offering a practical enhancement for LLM deployments.
Introduction to LLM Quantization Challenges
The deployment of LLMs often encounters high computational and memory demands, particularly in constrained environments. Post-Training Quantization (PTQ) emerges as a solution by minimizing model size while maintaining performance. Within this paradigm, rotation-based transformations are a key technique to manage quantization issues, but such methods, including QuaRot, exhibit substantial performance drops at very low bit-widths like 2-bit quantization.
Proposed Methodology: Grouped Sequency-arranged Rotation (GSR)
The paper introduces a novel rotation technique termed Grouped Sequency-arranged Rotation (GSR), intended to be a zero-training enhancement to the rotation matrix construction process for PTQ. Leveraging the Walsh-Hadamard transform, GSR arranges frequency components to attenuate quantization errors more efficiently than previous Hadamard-based approaches. Specifically, GSR deploys block-diagonal matrices with grouped Walsh matrices, isolating outliers’ influence within quantization blocks. This innovation achieves comparable performance to existing optimization-based methods, eliminating the need for training phases.
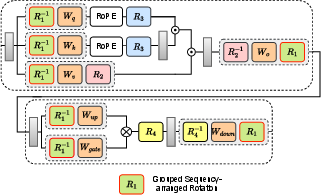
Figure 1: Overall diagram of rotation scheme. We applied Grouped Sequency-arranged Rotation (GSR) on R1.
Theoretical Framework
The basis for GSR is the transformation of Hadamard matrices into Walsh matrices via sequency ordering, where rows are reordered to manage bit flips strategically—this process clusters elements with similar frequency characteristics. The implication is a reduction in intra-group variance, beneficial for mitigating quantization errors.
Rotation for LLM Quantization
Within the context of LLM activation paths, different rotation matrices (R1, R2, R3, R4) perform unique roles. The sequencing optimization of GSR efficiently handles outliers by distributing their effect across smaller partitions, as opposed to global rotations that spread the influence extensively (Figure 2).
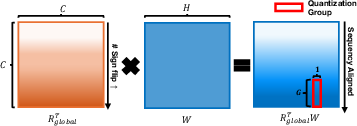
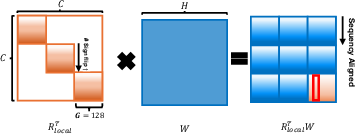
Figure 2: Global rotation applies a full-matrix transformation across all dimensions and spreads outlier effects widely.
Empirical Validation
Experimental Setup
GSR was validated across several LLM benchmarks including WikiText-2 and zero-shot reasoning tasks with Llama-2 models. Comparison with incumbent techniques—QuaRot, SpinQuant, and OSTQuant—demonstrated GSR’s superiority particularly in low-bit quantization scenarios.
Results and Analysis
Across tested configurations, GSR consistently reduced perplexity (PPL) scores: for instance, from QuaRot’s GH at 20.29 on WikiText-2 to GSR’s adjusted 11.59. Zero-shot task performance also benefitted significantly from GSR’s efficient transformation, affirming its efficacy without supplementary model training.
Future Implications and Extensions
The potential of GSR extends beyond current benchmarks, suggesting applicability in various model architectures requiring PTQ without intensive retraining. However, as quantization precision increases, gains from GSR diminish, directing future research towards broadening the method’s scalability and efficiency improvements for higher bit-width scenarios.
Conclusion
GSR presents an advance in PTQ for LLMs through a signal processing-inspired strategy, enhancing model adaptability without training overhead. Its methodical application of sequency principles fosters robust performance across quantization levels, establishing a foundation for future explorations into efficient model deployment strategies within resource-limited settings.