- The paper presents novel integration of vision, language, and action modalities to address complex tasks in dynamic settings.
- It demonstrates advanced multimodal architectures and training strategies using real-world and synthetic datasets.
- The study outlines key applications in robotics, autonomous driving, healthcare, and precision agriculture while noting ongoing challenges.
Vision-Language-Action Models: Concepts, Progress, Applications, and Challenges
Vision-Language-Action (VLA) models have introduced an advanced paradigm in artificial intelligence by seamlessly integrating perception, language understanding, and action generation into unified frameworks. This essay provides an expert overview of these models, evaluating their conceptual foundation, progress, applications, and the technical challenges they face, along with prospective solutions.
Introduction
Prior to the advent of VLA models, key components of robotics and AI were predominantly developed as isolated entities, such as vision systems for recognizing images, LLMs for text processing, and action systems for executing movements. These systems, while effective in isolation, failed to offer integrated solutions to complex, real-world challenges where cross-modal interaction is necessary. Traditional computer vision models, often based on CNNs, and task-specific LLMs, limited the ability of robots to adapt and act in multifaceted environments (Figure 1).
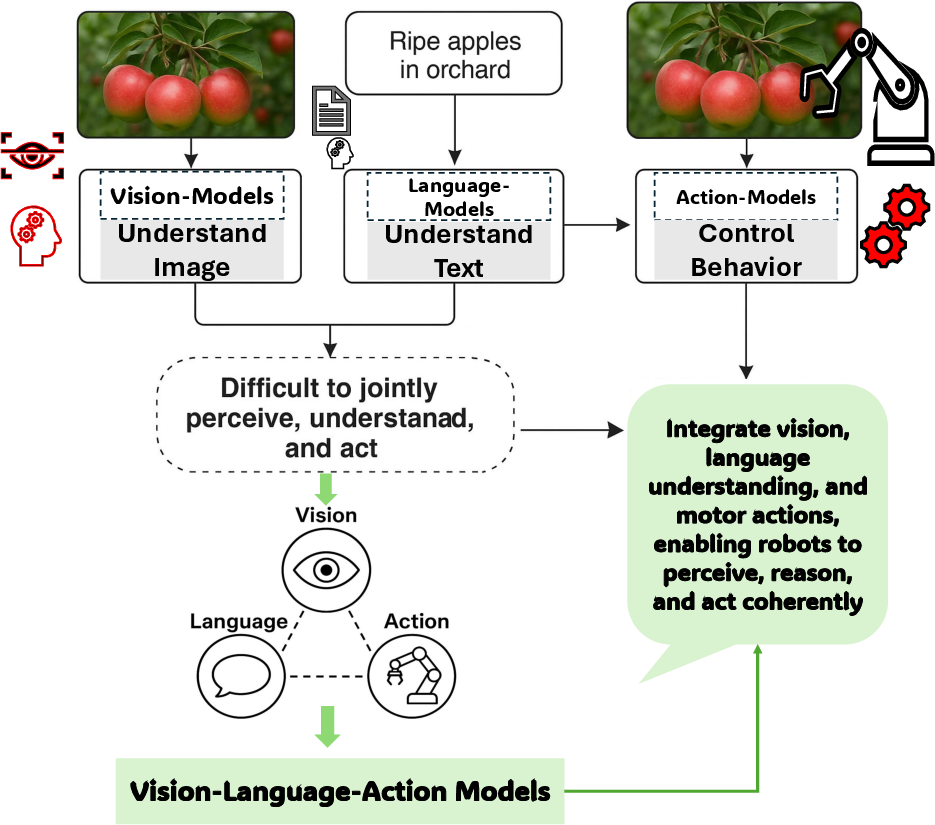
Figure 1: Evolution from Isolated Modalities to Unified Vision-Language-Action Models. This figure illustrates the transition from separate vision, language, and action systems-each limited to its own domain-to integrated VLA models.
Conceptual Foundations and Developmental Trends
VLA models fuse vision, language, and action modalities through tokenization and multimodal integration, creating a single framework that supports perception, reasoning, and action in dynamic settings. These models employ sophisticated architectures such as transformers, ViTs, and LLMs like T5 and BERT, often employing multimodal fusion techniques for seamless integration across domains (Figure 2). The past few years have seen VLA systems evolve along three main developmental pathways focusing on foundational integration, domain specialization, and robustness.
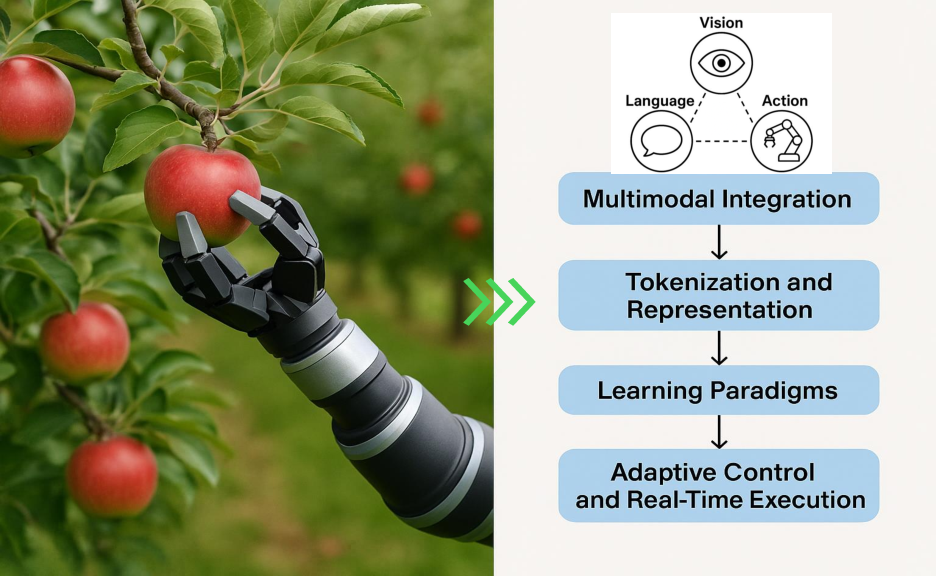
Figure 2: Foundational Concept of VLA Models (in an Apple-Picking Scenario), guided by a VLA model.
Progress and Training Strategies
Significant architectural innovations and training methodologies have driven the capacity of VLA models, with notable advances in data-efficiency and parameter optimization strategies. Leveraging web-scale semantically rich datasets, in conjunction with real-world and synthetic robotic demonstrations, VLA models achieve rapid convergence on new tasks while minimizing compute overhead. Table \ref{tab:vla_challenges_extended} outlines the spectrum of recent VLA systems and their applications, highlighting diversity in vision, language, and action decoder choices.
Key Application Domains
- Humanoid Robotics
Humanoid robots, as showcased by systems like Helix (Figure 3), harness VLA models for complex domestic and healthcare tasks via real-time, voice-to-action pipelines. Helix demonstrates a hierarchical VLA controller, combining SigLIP for visual grounding and LLaMA-2 for language understanding, translating intricate commands into full-body motion plans for domestic operationsâfrom clearing tables to collaborative cookingâwith dynamic task adaptation and safety assurance \cite{li2024cogact, kaya2025adaptive}.

Figure 3: This figure illustrates âHelix,â a next-generation humanoid robot executing a household task using a VLA framework.
- Autonomous Vehicle Systems
In autonomous vehicles, VLAs such as CoVLA and OpenDriveVLA unify visual grounding and trajectory planning (Figure 4). CoVLAâs comprehensive dataset \cite{arai2025covla} and OpenDrive's hierarchical planners tackle path planning and reasoning challenges \cite{zhou2025opendrivevla}. By fusing vision and language, these models achieve robust decision-making and obstacle negotiation in real-world driving scenarios.
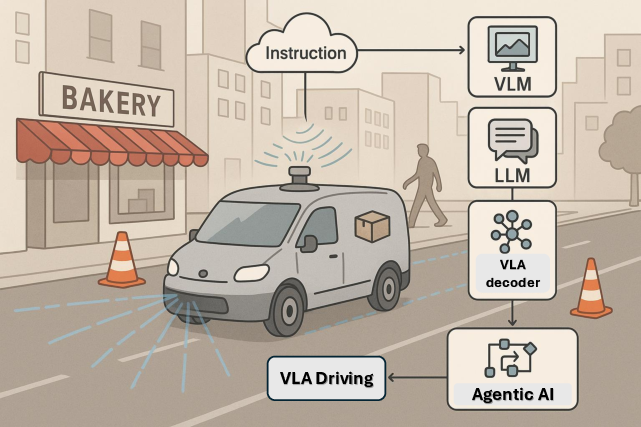
Figure 4: This illustration depicts an autonomous delivery vehicle powered by a VLA system, integrating VLMs for visual grounding, LLMs for instruction parsing, and a VLA decoder for path planning.
- Industrial and Medical Robotics
The deployment of VLAs in industrial robotics and healthcare amplifies productivity and safety. Models like CogACT \cite{li2024cogact} emphasize action robustness through diffusion-based control, while RoboNurse demonstrates task adaptability and real-time action execution \cite{li2024robonurse}, aligning language instructions with nuanced tool manipulation in clinical settings (Figure 5).
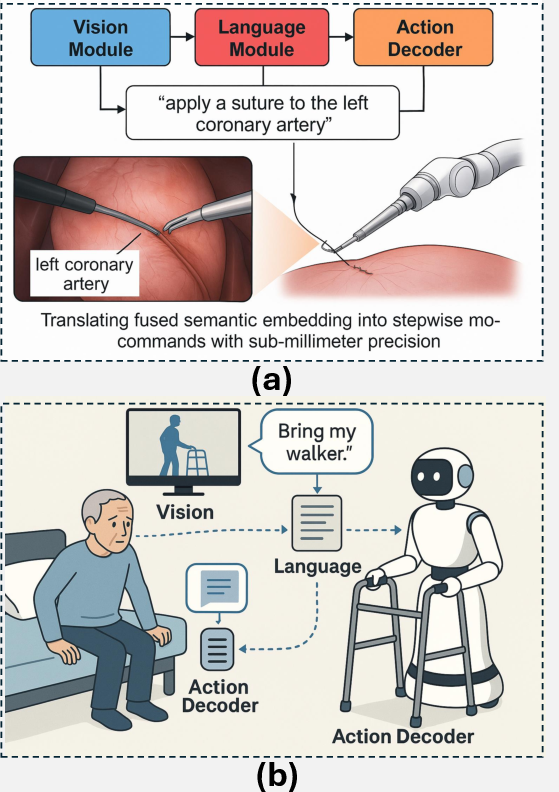
Figure 5: This figure depicts a VLA surgical system executing the task âapply a suture to the left coronary artery.â
- Precision and Automated Agriculture
VLAs enhance precision agriculture by integrating vision, language, and action cues into a single adaptive control loop, as seen in Figure 6. Models like Dexterous GraspVLA \cite{zhong2025dexgraspvla} adapt to varied terrain and crop types, enabling intelligent, context-aware fruit picking and drone-assisted irrigation planning, increasing yield and sustainability.
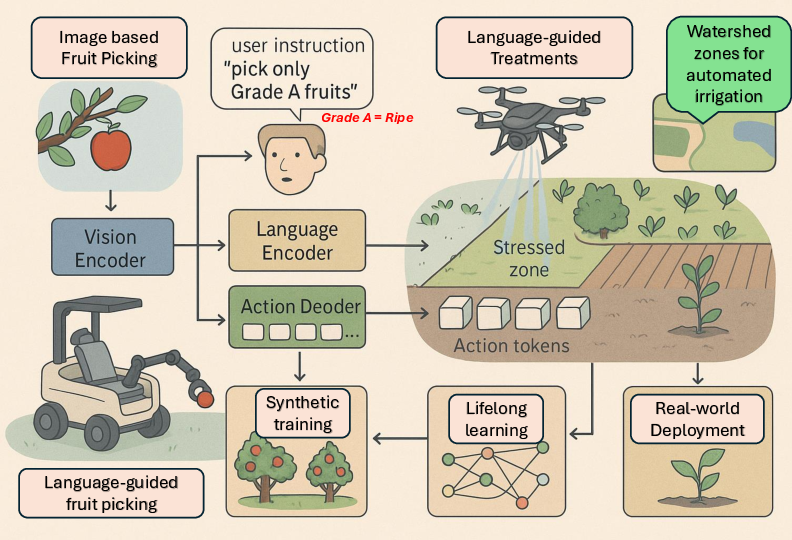
Figure 6: This diagram illustrates the application of VLA models in precision and automated agriculture.
- Interactive AR Navigation
VLA models empower AR navigation, transforming urban and indoor wayfinding through real-time scene interpretation, robust semantics, and personalized guidance (Figure 7). In dynamic urban landscapes, these agents seamlessly adjust to shifting contexts, supporting accessible, transparent, and hazard-aware mobility.
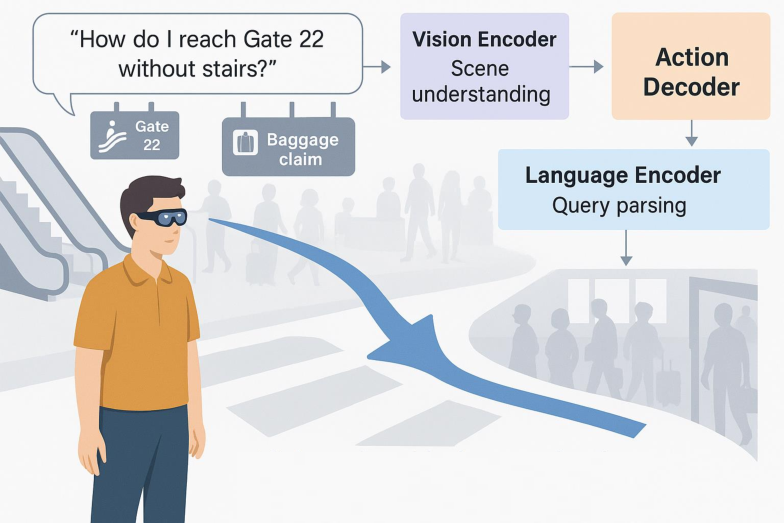
Figure 7: Showing how VLA models enable interactive AR navigation by fusing real-time visual perception, language understanding, and action planning in dynamic environments.
\section{Challenges and Future Directions}
Addressing the limitations of VLAs is essential to their practical deployment. Real-time inference remains a computational hurdle; solutions such as parallel processing and quantization techniques promise efficiency gains \cite{li2024improving, kim2025fine}. Multimodal representationâreconciling vision, language, and actionârequires hybrid architectures blending diffusion and autoregressive policies \cite{pertsch2025fast}. Safety is paramount in unpredictable scenarios; risk-aware planning ensures compliance and adaptability \cite{zhang2025safevla, ma2024survey}. Dataset biases affect alignment, demanding debiasing and diverse data collection \cite{sahili2025scaling, kim2024openvla}. Finally, ethical challenges necessitate governance frameworks that emphasize privacy and stakeholder engagement \cite{mumuni2025large, zhang2025slim}. Addressing these challenges will lay the groundwork for deployable VLA-driven autonomy.
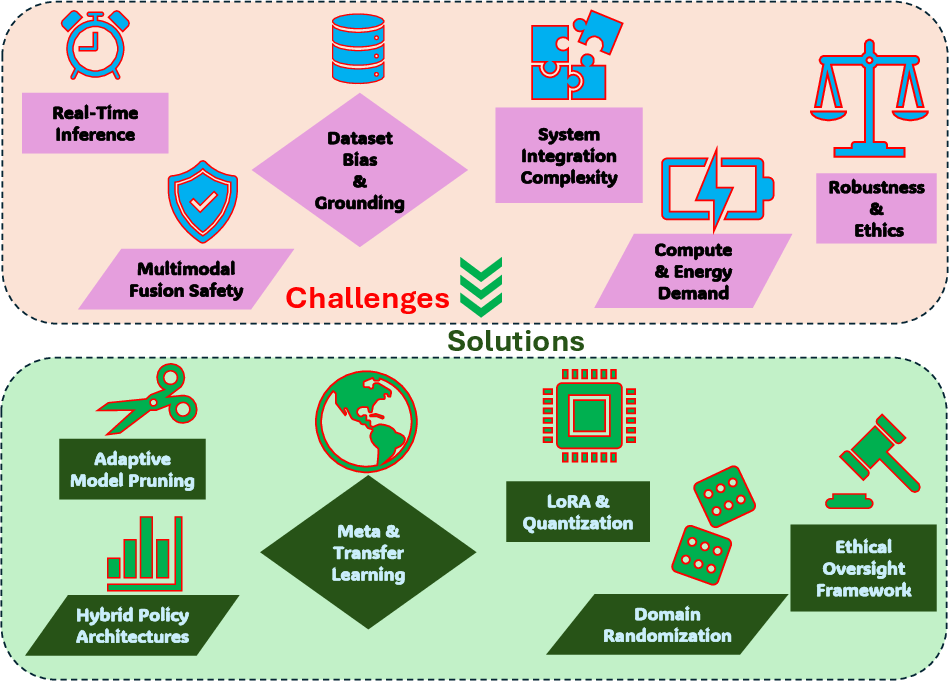
Figure 8: This diagram maps six core VLA challenges against targeted solutions, clarifying pathways to robust, efficient, and safe deployment across diverse domains.
\section{Conclusion}
Vision-Language-Action models epitomize the synthesis of visual, linguistic, and action modalities, heralding intelligent, context-aware robotics. Progress is reflected in multimodal integration, architectural design, and real-world adaptability. Models like Helix, OpenDriveVLA, and RoboNurse illustrate VLAs' capacity in complex domains, from home assistance to autonomous driving and medical tasks. Yet, challenges such as real-time requirements, safety, and generalization persist. Addressing these through advanced architectures, data strategies, and ethical oversight will enable VLAs to fulfill their transformative potential across embodied AI. Future VLAs, empowered by global datasets and continual self-improvement, herald scalable autonomy and socially aware task execution.