- The paper presents Epistemic AI, a paradigm shift that enables models to explicitly quantify and update ignorance using credal and random-set methods.
- The paper distinguishes epistemic from aleatoric uncertainty, demonstrating that set-based approaches outperform traditional Bayesian and ensemble methods on tasks like ImageNet-A classification.
- The paper provides theoretical and empirical evidence that epistemic models enhance calibration and robust generalization in high-stakes applications such as autonomous driving and medical imaging.
Epistemic Artificial Intelligence: Towards Trustworthy Uncertainty Quantification in Machine Learning
Introduction and Motivation
Machine learning models have achieved superior performance in a range of supervised and generative tasks, yet their ability to quantify uncertainty and recognize when they lack knowledge remains fundamentally limited. This paper presents a rigorous analysis of the failure modes of traditional, Bayesian, ensemble, and evidential uncertainty modeling approaches, and advances a position for a paradigm shift—Epistemic Artificial Intelligence (Epistemic AI). The central thesis is that AI systems require the capacity to explicitly model and manage epistemic uncertainty, thereby truly "knowing when they do not know", which is essential for robust deployment in open, adversarial, and safety-critical environments.
Uncertainty Quantification: Core Challenges
Despite the widespread integration of softmax-based confidence estimation in neural architectures, empirical evidence demonstrates systematic overconfidence, especially on OoD and adversarially filtered examples such as ImageNet-A. Traditional deep networks produce inflated probability estimations on samples far from the training distribution, largely due to their calibration reflecting only relative confidence, not total uncertainty.

Figure 1: Misclassifications made by a traditional deep model (ResNet50) are assigned excessively high confidence compared to an epistemic (uncertainty-aware) model on adversarial (ImageNet-A) samples.
This overconfidence directly undermines the safety and reliability of AI in domains such as autonomous driving, medical imaging, and scientific modeling, where unknown-unknowns are the norm. Importantly, this challenge is not fully addressed by regularization, domain adaptation, or classical Bayesian inference, as these techniques model parameter or data variability but conflate epistemic (knowledge-based) and aleatoric (irreducible) uncertainty.
Taxonomy of Uncertainty Approaches
The paper systematically distinguishes major algorithmic paradigms for uncertainty estimation:
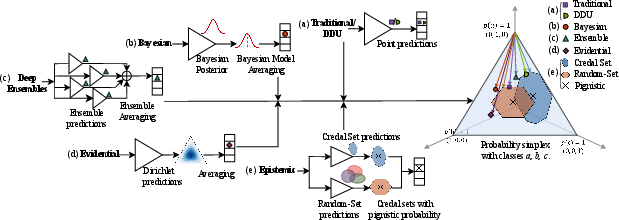
Figure 2: Taxonomy of main uncertainty modeling frameworks, including deterministic, Bayesian, ensemble, evidential, and epistemic methods.
- Deterministic and DDU Methods: Provide single-point probability vectors and limited uncertainty awareness, often fail to distinguish unknown classes or express model ignorance.
- Bayesian Deep Learning: Models weight uncertainty but integration through model averaging (BMA) "averages out" epistemic ignorance and cannot represent society's state of knowledge when data is scarce or pilots are missing.
- Ensembles and Deep Ensembles: Aggregate independent point predictions to approximate predictive uncertainty, yet are theoretically problematic with poor scaling properties.
- Evidential Deep Learning: Employ Dirichlet outputs to capture higher-order uncertainty, yet do not always decrease epistemic uncertainty with more data and have limited theoretical justification for epistemic-aleatoric separation.
- Credal Sets, Random Sets, and Epistemic Modeling: Rely on convex sets/intervals of distributions or belief function assignment on sets of hypotheses (not single outcomes), offering a genuine mechanism to encode and update ignorance, supported by robust learning theory and recent algorithmic advances.
Epistemic AI is defined by a commitment to explicitly learn with and from ignorance. The model is constructed to represent second-order uncertainty: not simply the likelihood of an outcome, but the uncertainty over those likelihoods. This “paradoxical” principle—that models must first learn what they do not know—yields concrete learning architectures wherein predictions are set-valued (credal sets, random sets, belief functions), as opposed to point probabilities.
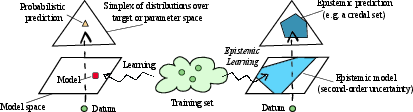
Figure 3: Contrasting classical learning (left) where models output a single probability, with epistemic learning (right) which produces a second-order uncertainty measure (set of plausible probabilities).
Epistemic learning architectures now exist for supervised, unsupervised, and reinforcement learning, and are under exploration for large-scale generative models and LLMs. Notably, recent benchmark analyses (CIFAR-10, ImageNet) report that credal and random-set neural networks outperform ensemble, Bayesian, and evidential models in accurate uncertainty quantification, out-of-distribution detection, and adversarial robustness—while maintaining comparable inference costs to traditional models.
Theoretical and Empirical Advantages
Key theoretical implications include:
- Ignorance Representation: Bayesian approaches impose total belief constraints (sum to 1), hindering their ability to flexibly model ignorance. Set-based (credal, random set) architectures permit mass assignment to ignorance, and their size can be reduced as more data is acquired (consistency with asymptotic learning).
- Epistemic Learning Theory: The use of convex sets of distributions generalizes PAC learning bounds; epistemic learning accommodates both finite and infinite hypothesis spaces with uniform generalization guarantees.
- Parameter vs. Target Space Uncertainty: Epistemic models can represent both uncertainty in the target/prediction space and in model parameters, facilitating explicit separation between aleatoric and epistemic components.
Application Domains and Generalization
Epistemic approaches have been extended to the following domains:
- Supervised Classification and Regression: Credal-set neural networks (CreINNs, CreDEs) provide interval-valued predictions and improve robustness. Random-Set Neural Networks (RS-NNs) naturally handle ambiguous and incomplete data. These models demonstrate improved calibration and uncertainty estimation over standard Bayesian and ensemble architectures.
- Clustering/Unsupervised Learning: Evidential and credal clustering algorithms (e.g., ECM, EVCLUS, credal c-means) enhance traditional c-means/fuzzy clustering by supporting ambiguity and cluster uncertainty, critical as dimensionality and data complexity grow.
- Reinforcement Learning: Epistemic quantification in RL (e.g., Diverse Projection Ensembles, SMC-DQN) supports cautious exploration and sharper separation of risk, but theoretical and algorithmic development is nascent.
Toward Epistemic Generative and Foundation Models
The paper directly addresses the challenges of applying epistemic uncertainty modeling to generative models and LLMs. Random-set approaches can produce belief distributions over vocabulary and token clusters, supporting measures of sentence uncertainty and better management of hallucinations in text generation. For diffusion models, learning a second-order distribution (e.g., inverse gamma) over noise parameters can furnish systematic sample diversity control and more faithful data mimetics than current models.
Open Challenges and Future Directions
Though scaling random-set and belief-function models to foundation-scale architectures remains challenging, advances in clustering, dynamic set budgeting, and efficient credal set computation enable application to large datasets (e.g., ImageNet). Particularly critical is the availability of unified evaluation frameworks for epistemic predictions to ensure comparability across model classes, as well as the extension to online, continual, and neurosymbolic learning paradigms.
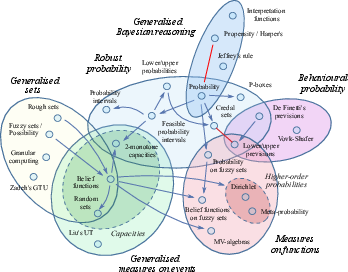
Figure 4: Uncertainty theories are arranged into a hierarchy of theoretical generality, with epistemic methods providing the most nuanced representation of knowledge and belief.
Major research directions include:
- Integration with Continual Learning and Symbolic Knowledge: Epistemic models can more reliably support knowledge transfer and lifelong model updates, especially under changing and unbounded data distributions.
- Calibration and Statistical Guarantees: Statistical validity—such as coverage, confidence interval generalizations, and conformalization—is being rapidly advanced within the epistemic paradigm.
- AI for Science and Society: Epistemic models are specifically poised to address the unique uncertainty demands of pandemic prediction, climate science, and scenarios with rare or emerging data, providing better tools for scientific and ethical deployment.
Conclusion
The paper constructs a compelling and technically rigorous argument for centering epistemic uncertainty in AI architectures. It advances the epistemic AI paradigm as a means for models to “know when they do not know,” thereby mitigating failure modes of overconfidence and enhancing decision-making reliability under true uncertainty. As epistemic modeling frameworks (credal sets, random sets, belief functions) are integrated with scalable deep architectures and statistical learning theory, they offer a tractable path to more robust, trustworthy, and scientifically groundable machine learning systems.
The implications are profound: only by endowing our models with the capacity to explicitly represent and update their ignorance can we ensure generalization far from the training data, achieve resilience in critical applications, and approach the genuine reliability demanded for operating AI in open and high-stakes environments.