- The paper introduces gg-bench, a novel benchmark that dynamically generates strategy games to evaluate LLMs' general intelligence.
- It employs a procedural approach where LLMs generate game descriptions and implementations, with RL agents trained through self-play to provide measurable win rates.
- The findings highlight LLMs' strategic reasoning limitations and set the stage for scalable, evolving evaluation frameworks in AGI research.
Measuring General Intelligence with Generated Games
Introduction
The pursuit of AGI remains at the forefront of AI research, with numerous challenges in assessing the capacity of AI systems to generalize across novel, unseen environments. The paper "Measuring General Intelligence with Generated Games" (2505.07215) introduces {gg-bench}, a sophisticated benchmark designed to evaluate the reasoning abilities of LLMs through the lens of dynamically generated gaming environments. This work departs from static evaluation paradigms by utilizing a data-generating process that produces diverse and original game instances driven by LLM capabilities.
Benchmark Overview
{gg-bench} comprises a collection of game environments where LLMs are tasked with competing against reinforcement learning (RL) agents in synthesized games. These games are generated through a procedural method leveraging LLMs for crafting descriptions and implementations of two-player strategy games (Figure 1). The process begins with LLMs producing natural language descriptions of novel games, followed by coding these games into Gym environments. RL agents are then trained using self-play to establish competitive benchmarks against which the LLMs are evaluated. This paradigm emphasizes evaluating models based on their win rates against RL-trained agents rather than merely solved static tasks.

Figure 1: Overview of our benchmark creation process. We start by generating descriptions of two-player strategy games, after which we generate implementations of these games as Gym environments. Lastly, we employ self-play reinforcement learning to train agents on these games.
Evaluation Process
The evaluation utilizes various state-of-the-art LLMs and reasoning models, such as GPT-4o and DeepSeek-R1, assessing their performance through win rates against RL agents. The benchmark is notably challenging; non-reasoning LLMs achieve win rates between 7% and 9%, while advanced reasoning models demonstrate win rates from 31% to 36%. The primary failure of current LLMs stems from their inability to execute strategic reasoning over extended gameplay sequences, highlighting the necessity for structured decision-making and adaptability.
Analysis of Generated Games
The games within {gg-bench} exhibit considerable diversity in terms of gameplay mechanics and strategic elements. The generated environments are scrutinized for code similarity using Dolos, ensuring the originality and non-plagiarized nature of each instance (Figure 2). Despite the procedural generation process, the games span categories from number-based puzzles to combinatorial strategy, ensuring a broad spectrum of complexity and challenge.
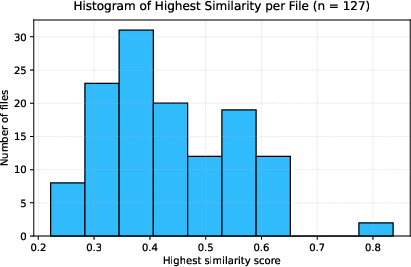
Figure 2: Distribution of the highest similarity score for every one of the 126 games in {gg-bench}.
Implications and Future Work
The scalability of {gg-bench} as a dynamic benchmark offers a robust platform for future expansions and refinements as AI progresses. This dynamic aspect ensures that as more sophisticated models are developed, the benchmark can evolve through generating new, increasingly complex games. The approach also proposes empirical demonstrations that models can generate tasks they themselves are unable to solve, suggesting a trajectory for future model development aiming towards AGI. Future work will focus on enhancing the benchmarks’ difficulty and breadth, illustrating continuous improvements in both game complexity and model reasoning ability.
Conclusion
The paper presents a forward-thinking approach to measuring general intelligence in LLMs through dynamically generated games, setting a precedent for scalable, procedurally generated benchmarks. By releasing the data generation code, the paper opens new avenues for exploring and expanding AGI evaluation methods, ultimately contributing significantly to the field’s understanding and pursuit of truly intelligent systems.