- The paper introduces AttentionInfluence, a supervision-free method that uses attention head ablation to measure reasoning intensity and select high-utility pretraining data.
- Its methodology computes sample-level loss deltas between an original and a degraded model, yielding significant improvements on benchmarks such as MMLU, GSM8K, and HumanEval.
- The framework enhances data diversity and scalability by eliminating manual labeling and reinforcing mechanistic insights on retrieval heads to boost LLM generalization.
AttentionInfluence: A Supervision-Free, Mechanistic Data Selection Framework via Attention Head Influence
Introduction and Motivation
The selection of high-quality pretraining data is established as a primary determinant of LLMs' generalization, with prior methods heavily weighted towards constructing supervised or LLM-labeled classifiers to extract reasoning-intensive data subsets (2505.07293). However, supervised protocols incur significant manual overhead and are subject to domain-specific biases, often resulting in limited diversity and scalability constraints. The authors address how to scalably, reliably, and automatically identify reasoning-rich, high-utility data with minimal human curation and zero reliance on supervised signals.
To this end, this work introduces AttentionInfluence: a practical, training-free, and supervision-free framework that leverages mechanistic interpretability insights from Transformer architectures. The core assertion is that the degradation of specific attention heads—retrieval heads—with ablation provides a natural proxy to measure the reasoning utility and influence of data samples. This enables a small pretrained LLM to act as a performant selector of data that, when used to pretrain larger LLMs, yields consistent and marked improvements, especially on knowledge-intensive and reasoning-heavy benchmarks.
Methodology
Mechanistic Basis: Retrieval Heads and Influence Estimation
Mechanistic interpretability research has elucidated that, while FFN modules store atomic knowledge, attention heads—particularly retrieval heads—mediate in-context retrieval and procedural reasoning [wu2024retrieval, olsson2022context].
AttentionInfluence builds on this insight by:
- Identifying retrieval heads in a base LLM via proxy retrieval tasks and scoring token-level head attribution.
- Masking (ablating) these influential heads to construct a degraded reference model from the original, resulting in a significant drop in reasoning and retrieval capacity.
- Computing the sample-level loss delta (relative increase in cross-entropy loss) between the original and degraded model on candidate data. The relative delta for each sample quantifies the extent to which the sample relies on the presence of retrieval heads, and thus, its reasoning intensity.
This mechanistic, model-intrinsic signal replaces any need for labels or external supervision.
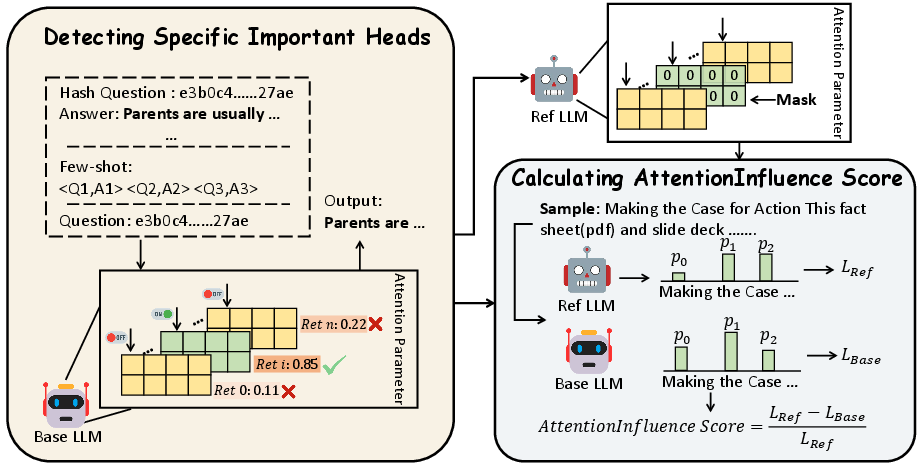
Figure 1: Illustration of the AttentionInfluence framework, showing how retrieval heads are identified, masked, and used to compute a loss-based selection signal.
Training-Free Data Selection and Weak-to-Strong Generalization
AttentionInfluence is implemented by applying the above procedure on a 1.3B-parameter dense, LLaMA2-alike model over the SmolLM-Corpus (241B tokens). The top 20% samples by AttentionInfluence score, amounting to 73B tokens, are mixed back with the full corpus, and then a 7B-parameter model is trained on 1T tokens. The protocol is free of training any bespoke classifiers and does not require human or LLM label generation at any stage.
Empirical Analysis
The selection schema was evaluated via comprehensive pretraining and downstream evaluation on a suite of benchmarks, partitioned into aggregate, math/code/reasoning, commonsense, and reading comprehension tasks.
Key findings include:
- Consistent, robust gains on challenging knowledge-reasoning tasks: +1.4pp on MMLU, +2.7pp on MMLU-Pro, +1.8pp on AGIEval-en, +2.7pp on GSM8K, +3.5pp on HumanEval, and notable improvements on BBH, ARC-Challenge, DROP, and MATH.
- The delta in aggregate benchmark performance emerges early (well before 100B training tokens) and persists across all training regimes, including the learning rate annealing phase (Figure 2).
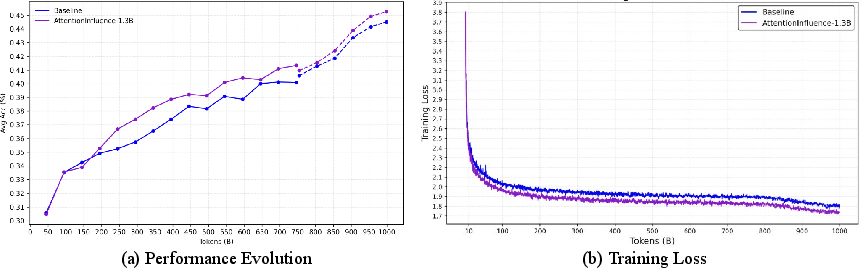
Figure 2: (a) Evolution of aggregate benchmark performance during pretraining, showing sustained and early advantage of AttentionInfluence. (b) Training loss comparison, with consistently lower loss from AttentionInfluence selection.
- On knowledge-light, factual tasks (ARC-Easy, TriviaQA, CSQA, PIQA), there is no regression, indicating that targeting reasoning-intensive data does not cannibalize basic knowledge acquisition (Figure 3). The reverse holds: improvements are concentrated on evaluation requiring multi-step reasoning, retrieval, and composition (Figure 4).
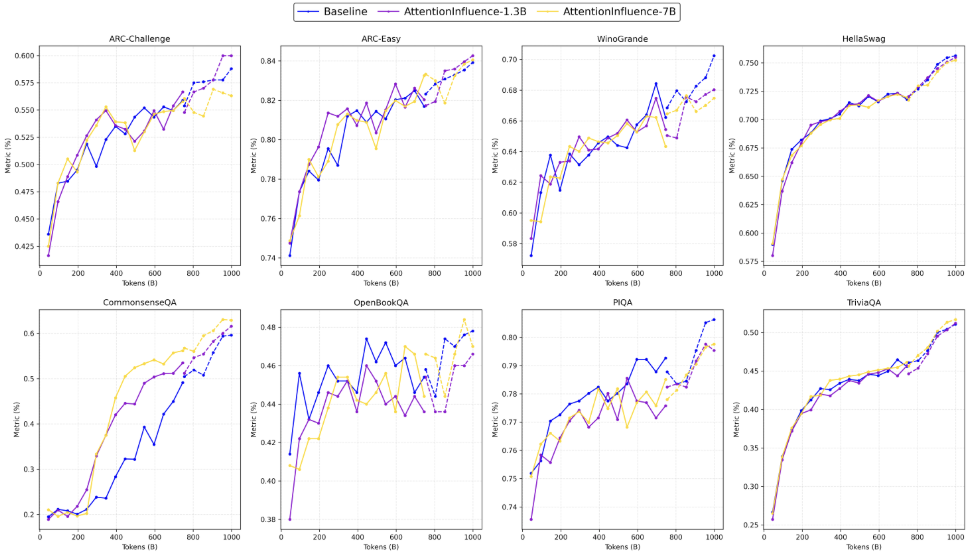
Figure 3: Performance evolution on factual and commonsense benchmarks; both methods yield similar outcomes.
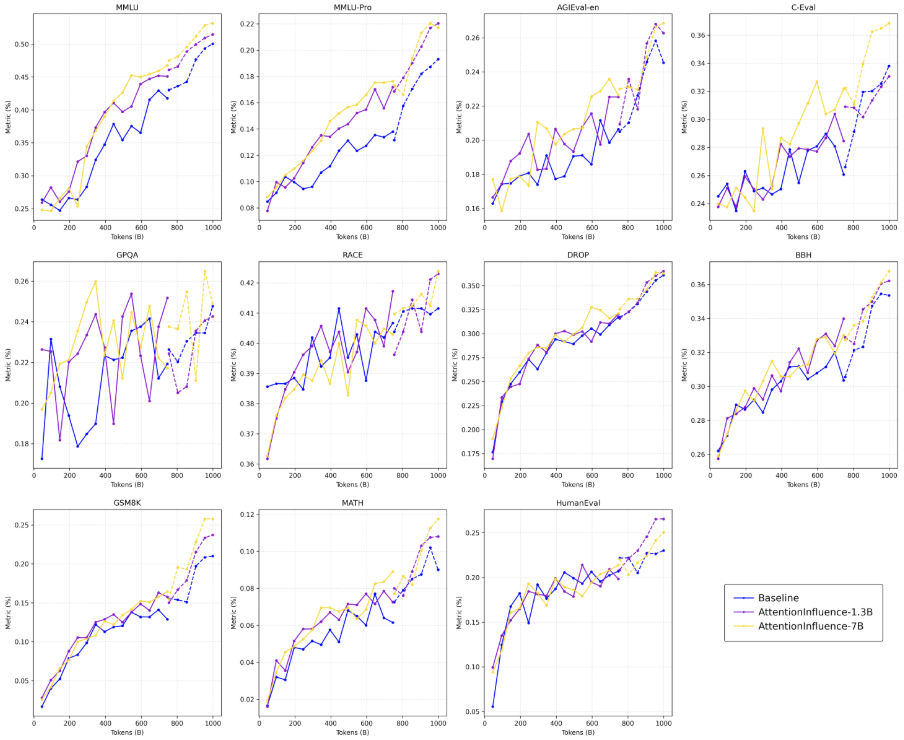
Figure 4: Substantial and persistent advantage on knowledge- and reasoning-intensive benchmarks by AttentionInfluence selection.
Mechanistic Effects and Interpretability
Ablation of retrieval heads yields drastic declines on reasoning benchmarks, whereas randomly ablating other heads has only minor effect, directly tying head influence to model generalization. Notably, data that is most sensitive to retrieval head ablation is precisely the data that, when used for pretraining, yields maximum LLM scaling improvements—a "mirror effect" linking mechanistic analyses to empirical generalization.
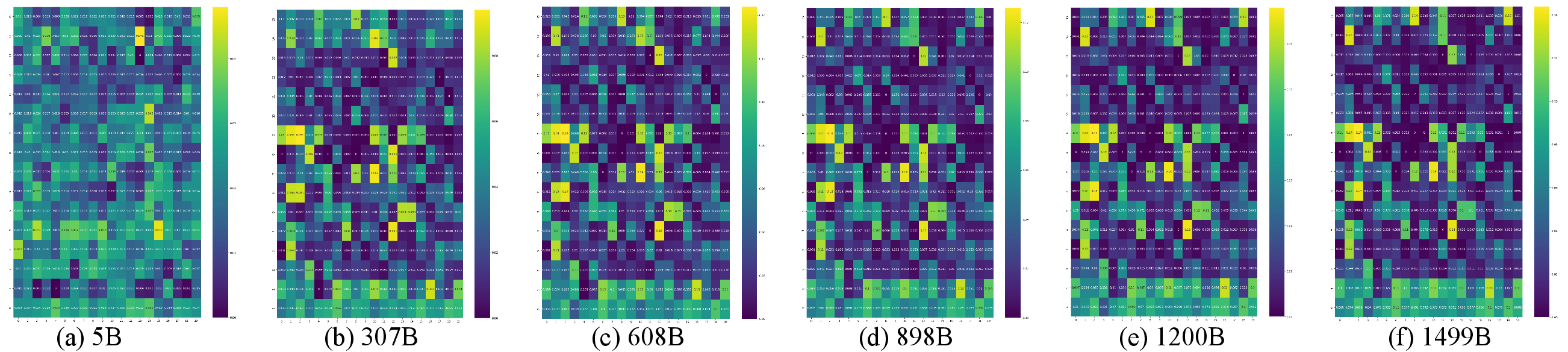
Figure 5: Emergence and strengthening of retrieval heads during LLM pretraining, supporting the mechanistic basis for their downstream role.
Data Diversity and Distributional Properties
Clustering and embedding-based analyses show AttentionInfluence selects a more balanced, diverse distribution of samples across domains and content categories than classifier-based methods, with strong but not redundant overlap (Figure 6). It preferentially selects longer, more comprehensive samples, amplifying procedural reasoning (e.g., problem solutions, code), rather than short factual snippets.
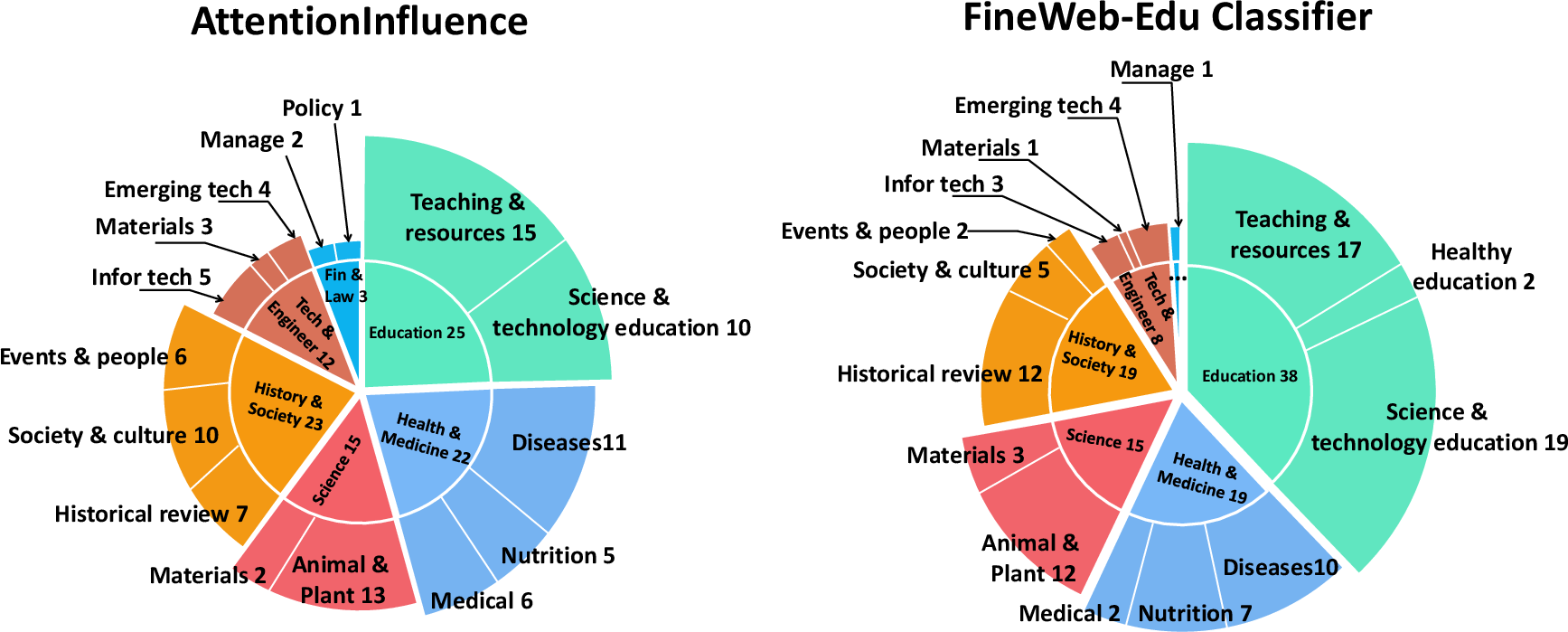
Figure 6: Clustering statistics: AttentionInfluence (left) yields balanced coverage across domains, complementing classifier-based selection (right).
Human evaluation with GPT-4o demonstrates that samples selected by AttentionInfluence consistently receive higher scores on reasoning intensity, matched in educational value but superior in complexity and logical depth.
Model Scale and Adaptivity
Applying AttentionInfluence with a 7B selector model results in even higher-quality selection, as evidenced by increased generalization and coverage across additional domains, including those underrepresented in the baseline corpus. The data selection pipeline is fully modular, allowing plug-and-play replacement of the head selection proxy or base model to target domains or task families of interest.
Practical and Theoretical Implications
Practical Impact
This framework eliminates the need for costly LLM or human annotation in data selection pipelines, thereby dramatically increasing the scalability, diversity, and generalizability of high-quality pretraining corpora—even in resource-constrained or domain-agnostic settings. The "weak-to-strong" property ensures small models can efficiently and mechanistically select data for much larger models with persistent gains.
Theoretical Insights
These results reinforce the centrality of retrieval heads for enabling reasoning and in-context learning in Transformers, providing a practical avenue for mechanistic findings to directly inform large-scale engineering. The correlation between head contribution and data utility implies that the operational footprint of deep models supplies a sufficient signal for data filtration and distillation—suggesting a new direction for self-aware, data-driven LLM optimization.
Future Prospects
Potential future directions include automated selection for task-adaptive pretraining, multi-level mixture modeling (using domain- or skill-specific proxies for head importance), and extensions to multilingual or long-context regimes. The modular nature of AttentionInfluence opens the door for generalized mechanistic frameworks where domain- or capability-specific data can be selected by targeting targeted internal model components or circuits.
Conclusion
AttentionInfluence establishes a robust, mechanistically grounded, and training-free methodology for reasoning-centric data selection by exploiting retrieval head attribution. It consistently delivers nontrivial gains in reasoning and knowledge-intensive benchmarks without degrading factual capabilities, scales efficiently with selector model size, and outperforms or complements classifier-based baselines in both diversity and quality. This work underlines the value of integrating mechanistic insights with practical LLM development and presents a scalable pathway for improved LLM training protocols.