- The paper presents a novel non-spatial autoregressive tokenization that uses reverse diffusion to align image tokens with causal AR principles.
- The paper demonstrates improved image-text consistency and RL metrics by avoiding anti-causal dependencies inherent in spatial tokenizations.
- The paper outlines a unified VLM training approach merging visual and textual tokens, resulting in enhanced multimodal synergy and robust performance.
Selftok: Discrete Visual Tokens of Autoregression, by Diffusion, and for Reasoning
Introduction and Motivation
The Selftok framework posits a decisive shift in the discrete visual token paradigm for vision-LLMs (VLMs). It fully dispenses with the spatial prior traditionally embedded in image tokenization systems and introduces a purely autoregressive (AR) token structure for visual data. By leveraging the AR inductive priors, foundational to LLMs, Selftok enables seamless unification of vision and language modalities under a shared discrete autoregressive architecture. Unlike hybrid models utilizing continuous AR (cAR) for image data, Selftok maintains compatibility with established LLM training and RL post-training protocols.
The design pivots on the observation that prevailing spatial or hybrid tokenizations inject anti-causal dependencies, violating Markov decision process (MDP) structure required for RL optimality. Selftok addresses this by constructing visual tokens through the reverse diffusion process, enforcing causality aligned with AR principles.

Figure 1: The Selftok pipeline encodes images into non-spatial, autoregressive discrete tokens, reconciling diffusion and AR generation.
Theoretical Foundation: Non-Spatial Autoregressive Tokenization
Critique of Spatial and Continuous Visual Tokens
Spatial tokenization fragments the image into grids or patches treated as independent variables in conventional transformers. However, the act of observing an image patch creates collider dependencies (see Pearl, 2009), undermining the core autoregressive factorization, and impeding application of Bellman’s policy improvement theorem. Conversely, continuous autoregressive models (cAR) are less robust to error propagation, less disentangled, and complicate RL formulation due to their infinite MDP structure.
Selftok’s driving hypothesis is that the non-AR dependence structure of spatial tokens is directly responsible for the mismatch between RL and visual generation capabilities in VLMs—an effect unobserved in LLMs, whose tokenization is strictly AR.
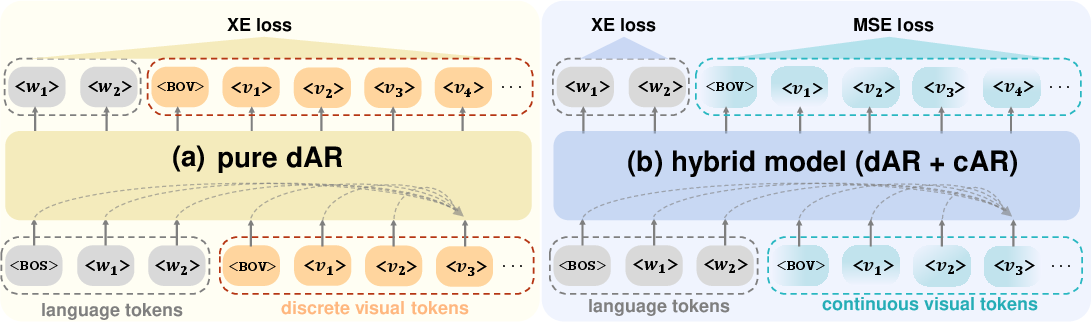
Figure 2: Spatial tokens induce anti-causal dependencies (red), which corrupt RL policy optimization via feedback loops; AR tokens by contrast maintain strict causal order.
Diffusion as an Autoregressive Process
Selftok constrains image encoding/decoding with a recursive AR prior, structurally aligned with the ODE form of reverse diffusion. The token sequence [v1,v2,...,vK] is constructed such that P(VK)=P(v1)i=2∏KP(vi∣v1:i−1), with each token corresponding to a reversed diffusion timestep. This formulation ensures:
- Each token addition maps to a deterministic, autoregressive update in the reconstruction process.
- The token sequence is empirically AR, as measured by strictly decreasing next-token entropy trends under sequence shuffling (segmented monotonicity, not observed in other tokenizations).

Figure 3: Progressive reconstruction and token interpolation reveal that only Selftok avoids spatial bias—token scope is global, not local.
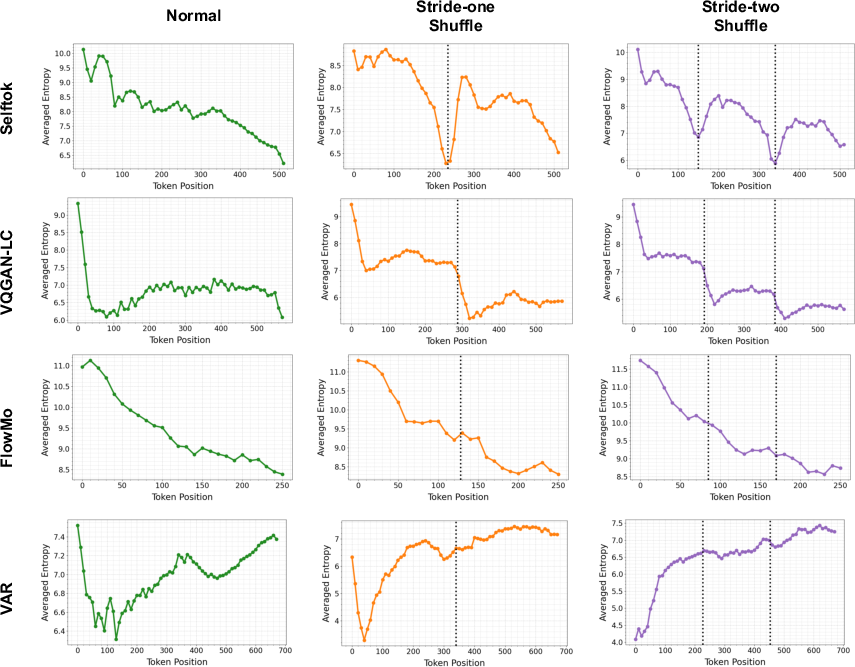
Figure 4: Only Selftok exhibits distinctly segmented, monotonic entropy drops consistent with the AR property even under shuffled sequence orders.
Architecture and Implementation
Encoder and Quantizer
Selftok employs a dual-stream MMDiT transformer: one stream for visual patch embeddings, another for positionally-aware AR token embeddings. Token quantization utilizes a large codebook (e.g., 215 entries) with quantization losses promoting embedding diversity. Codebook update leverages EMA; underutilized embeddings are reactivated to prevent dead codes.
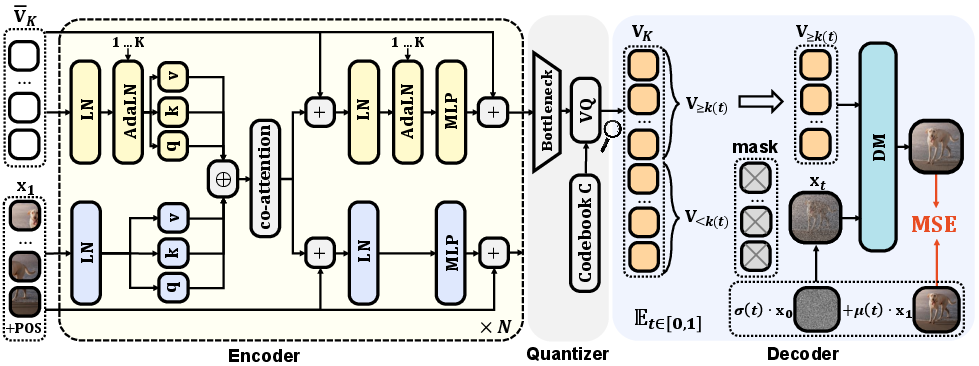
Figure 5: The encoder and quantizer pipeline: dual streams, codebook EMA, and AdaLN for token-awareness.
Decoder and One-Step Renderer
The decoder is a diffusion model, customized to accept Selftok’s AR sequence. A one-step renderer trained via MSE, LPIPS, and GAN losses allows for fast, deterministic reconstructions, outperforming multi-step diffusion decoders both in fidelity and throughput.

Figure 6: Left: One-step renderer yields visually superior reconstructions compared to multi-step diffusion. Right: Renderer architecture detail.
Ablation studies demonstrate that increased token count and codebook size enhance reconstruction, and token schedule aligns with known properties of diffusion (more tokens for higher t). The pipeline substantially outperforms spatial and 1D tokenizers (see PSNR and rFID measures).

Figure 7: Comparative reconstructions: Selftok achieves highest fidelity with non-spatial tokens.
AR VLM Training and Synergy
Selftok enables a unified VLM, trained autoregressively with a vocabulary containing both text and visual tokens, using a standard cross-entropy objective. Multimodal alignment is enforced with formats for text-to-image, image-to-text, image-only, and text-only, facilitating task transfer and minimizing catastrophic forgetting.
On DPG-Bench and GenEval, Selftok-SFT surpasses all contemporaneous AR-based VLMs in alignment metrics. Particularly notable is its positive synergy: joint training for generation and comprehension improves both, whereas spatial tokenizations suffer conflict in this setting.
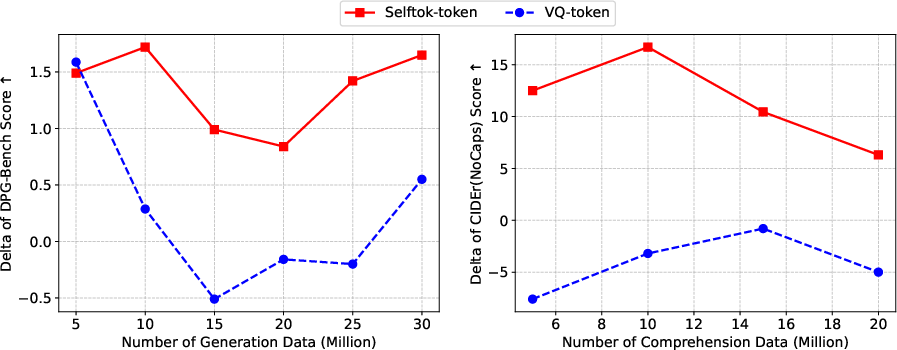
Figure 8: Selftok demonstrates robust positive Δ in multitask synergy, in stark contrast to spatial VQ-tokens.
Visual Reinforcement Learning
The formulation of visual RL over discrete AR token sequences enables application of the Bellman equation and policy improvement theorems. In this MDP, tokens are actions, sequences are states, and rewards are defined by programmatic detectors or QA-based VLM feedback. Crucially, only AR token sequences avoid anti-causal feedback loops; spatial token-based models do not admit the required recursion by Bellman’s structure.
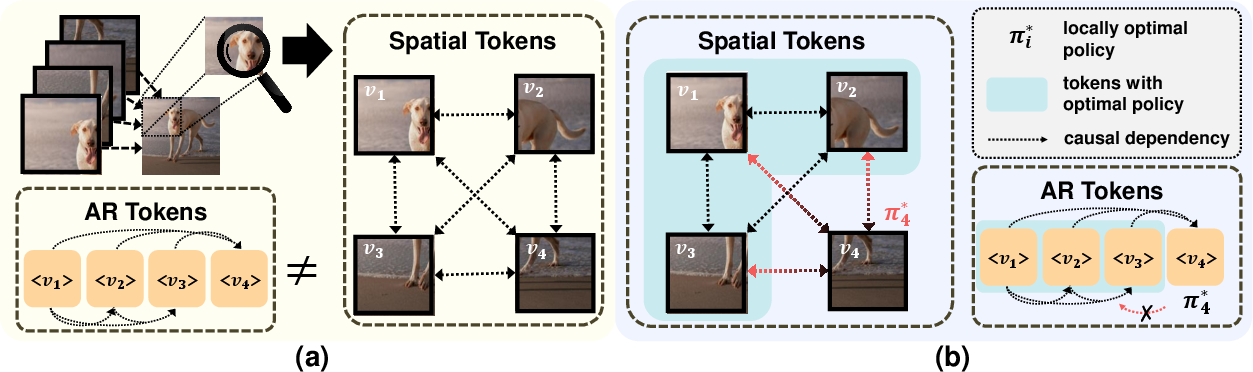
Figure 9: AR token causal graphs support recursive value computation; spatial tokens induce anti-causal paths that invalidate Bellman factorization.
Empirical Validation: Visual RL Gains
Selftok-based VLMs subjected to visual RL—driven by CLIP or comprehension VLM rewards—show strong improvement in image-text consistency, especially for rare and compositionally complex prompts. The gain is uniquely significant for Selftok (e.g., +18 on GenEval), while spatial token-based models plateau or degrade under RL.
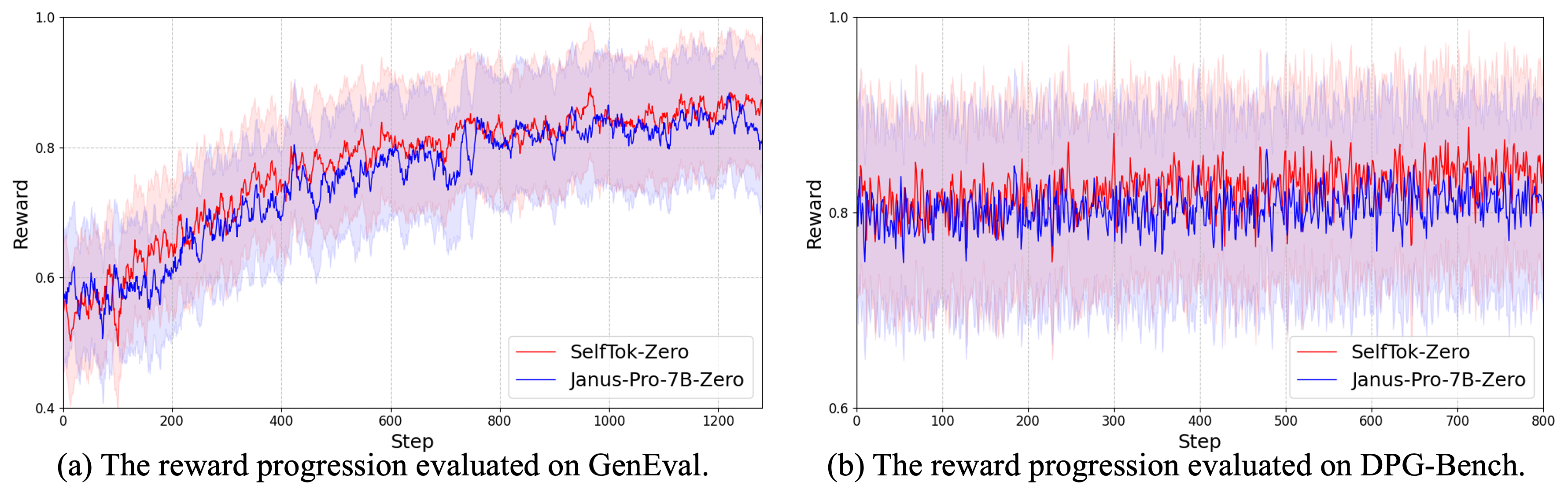
Figure 10: Reward progression under RL—a sharp climb for Selftok (green), little effect for spatial token-based models (orange).
Figure 11: Visual RL enables Selftok to generate accurate rare combinations (e.g. “red dog”, “yellow broccoli”) that are impossible under SFT.
Limitations and Future Work
While Selftok addresses core theoretical and practical limitations of spatial and hybrid VLM tokenizer architectures, it substantially increases token throughput requirements—LLMs are bottlenecked in generation speed relative to diffusion models. Scaling to high-resolution images or video generation (e.g., 512×512 with 2K+ tokens per frame) remains computationally intensive.

Figure 12: Promising preliminary results on 512×512 scaling via token reuse and multi-resolution Selftok.
Current models have not yet demonstrated cross-modal emergent capabilities at scale due to limited model capacity and training data. Planned extensions include physics-aware RL for video models and large-scale evaluation of cross-modal transfer.
Conclusion
Selftok establishes a rigorous AR formulation for visual tokenization, aligning causality of image discrete representations with AR LLM protocols and enabling direct application of reinforcement learning for vision. The observed qualitative and quantitative improvements validate the theoretical critique of spatial tokenization and the power of an AR, diffusion-driven non-spatial visual tokenizer. The path forward is clear: scaling Selftok to higher resolutions and longer sequences, and leveraging its compatibility with LLM RL pipelines, to unlock robust, interactive, and synergistic multimodal reasoning and generation at scale.