- The paper demonstrates that CEFR-based prompting initially constrains Spanish outputs but suffers from alignment drift during prolonged tutor-student dialogues.
- It employs simulated interactions with four multilingual LLMs, using readability scores and Mean Dependency Distance to assess language complexity across proficiency levels.
- The findings indicate that prompt engineering alone is insufficient for long-term tutoring, suggesting the need for alternative strategies like fine-tuning or interactive learning.
Alignment Drift in CEFR-prompted LLMs for Interactive Spanish Tutoring
Introduction
The paper "Alignment Drift in CEFR-prompted LLMs for Interactive Spanish Tutoring" (2505.08351) explores the potential of LLMs as adaptive language tutors, specifically assessing their ability to constrain output complexity in Spanish based on the Common European Framework of Reference for Languages (CEFR). Through simulated dialogues between tutor and student roles, the study evaluates the stability of CEFR-based prompting across three proficiency levels: A1, B1, and C1.
Experimental Design
The study leverages four open-source LLMs, ranging from 7B to 12B parameters, each instruction-tuned for multilingual interactions: Llama, Gemma, Mistral, and Qwen. Dialogues are generated by alternating between tutor and student roles to simulate a language tutoring scenario without human participants, allowing for an extensive low-cost evaluation of model performance.

Figure 1: System prompt provided to each tutor LLM for level A1. Level-specific words are underlined in red and replaced for B1 and C1.
Results
A suite of metrics, including traditional readability scores and syntactic measures such as Mean Dependency Distance (MDD), are employed to evaluate text complexity. Readability metrics consistently imply an initial success in aligning language output with proficiency levels; scores for A1 are higher (easier) than those for B1 and C1. However, over time, these distinctions blur, indicating a phenomenon termed "alignment drift."
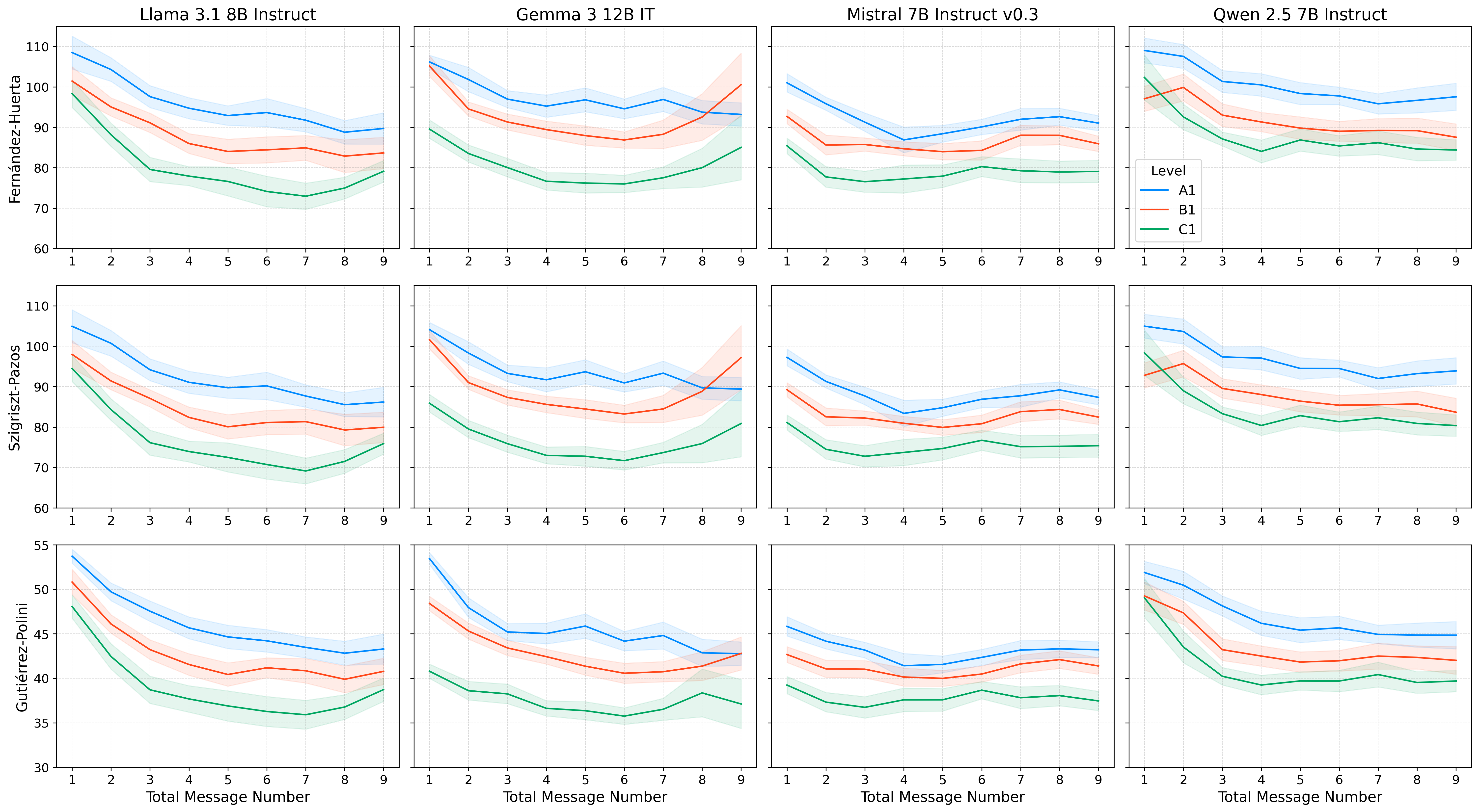
Figure 2: Average readability metrics over the total number of messages sent by the tutor LLM for each model, grouped by CEFR level (A1, B1, C1).
The analysis reveals significant variability among LLMs, with Llama and Gemma showing notable shifts in English or Mandarin content, particularly at lower proficiency levels. This disalignment underscores a critical limitation of direct CEFR-based prompting.
Discussion
While the study demonstrates the feasibility of using CEFR-based prompting to initially constrain LLM outputs, sustained dialogue reveals diminishing returns in constraint effectiveness, attributed to alignment drift. This finding calls into question the robustness of prompt engineering as the sole mechanism for adapting LLMs to specific educational contexts over extended interactions.
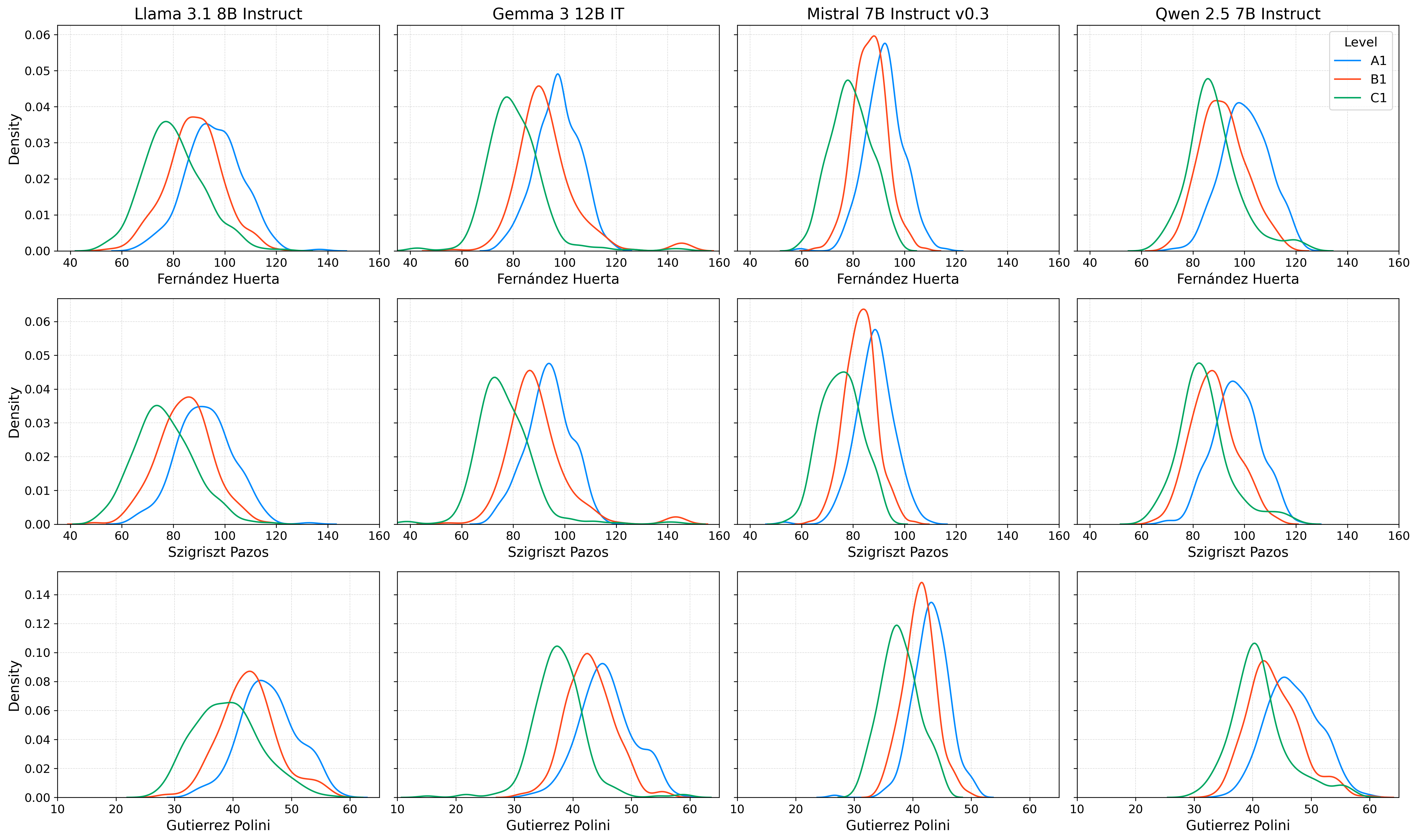
Figure 3: Readability metrics as separate density plots for each CEFR level (A1, B1, C1).
Implications and Future Work
The study's findings hold implications for deploying LLMs as personalized language tutors. The observed alignment drift suggests that complementary approaches, beyond system prompting, are necessary to maintain language complexity constraints over time. Future research should consider alternative methods such as model fine-tuning or interactive learning strategies to bolster the alignment of LLM behavior with intended pedagogical goals. Moreover, exploring robustness benchmarks for CEFR knowledge in LLMs could provide deeper insights into model capabilities.
Conclusion
This study introduces a scalable framework for evaluating LLMs in the context of language learning, specifically focusing on the alignment of model outputs with CEFR levels. Although initial constraints are achievable through system prompting, the persistence of these constraints diminishes over longer interactions. To advance the utility of LLMs in education, further research is necessary to develop more robust solutions against alignment drift in dynamic tutoring environments.