- The paper presents VRRAEs that integrate deterministic rank reduction via truncated SVD with probabilistic VAE sampling to effectively mitigate posterior collapse.
- It demonstrates improved image quality and reduced reconstruction errors on synthetic and real-world datasets, including MNIST, CelebA, and CIFAR-10.
- Empirical evaluations confirm that the method achieves lower FID scores and robust latent space regularization, leading to sharper and more reliable generated samples.
Variational Rank Reduction Autoencoders
In the study of latent space dynamics and generative modeling, Variational Rank Reduction Autoencoders (VRRAEs) emerge as a significant innovation that marries the deterministic benefits of Rank Reduction Autoencoders (RRAEs) with the generative power of Variational Autoencoders (VAEs). This paper explores the architecture and capabilities of VRRAEs, focusing on their application in mitigating common limitations associated with VAEs, such as posterior collapse and inadequate space regularization. The model leverages a truncated Singular Value Decomposition (SVD) within the latent space to enhance stability and generative capabilities.
Introduction and Background
VRRAEs incorporate the latent space regularization strength from RRAEs and the probabilistic sampling from VAEs under a unified framework. RRAEs utilize a truncated SVD to enforce a bottleneck via rank reduction rather than dimensional reduction, which inherently regularizes the latent representation. This deterministic action counteracts the chaotic nature of generative processes by introducing stability, making VRRAEs robust against generative failures frequently observed in standard VAEs.
The VAEs maximize the evidence lower bound by balancing reconstruction quality and latent distribution regularization through the Kullback-Leibler (KL) divergence. VRRAEs retain this approach but substitute deterministic coefficient sampling post-SVD for latent variable sampling, ensuring stronger regularization and mitigating posterior collapse.
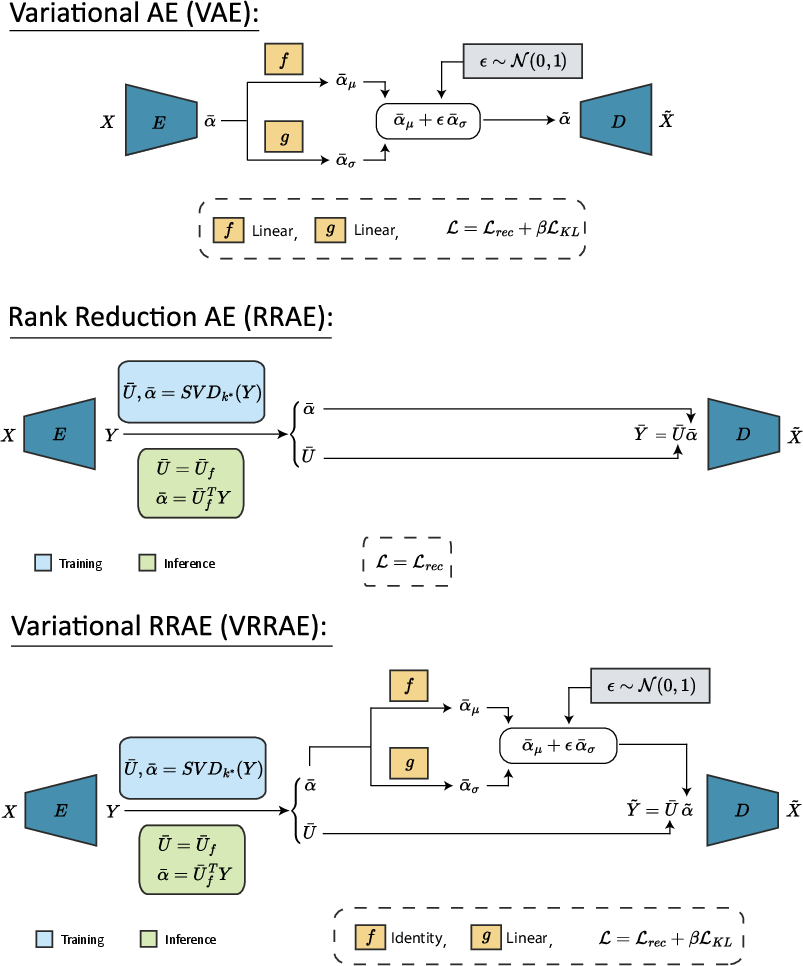
Figure 1: Schematic illustrating the architecture of Variational Rank Reduction Autoencoders (VRRAEs). Both E and D are trainable Neural Networks representing an encoding and a decoding map. SVDk∗ is a truncated SVD of rank k∗.
Methodology
The architecture of VRRAEs is designed to utilize the deterministic stability of RRAE latent representations while embedding the probabilistic structure central to VAEs. VRRAEs sample the truncated SVD coefficients αˉ rather than the latent matrix representation Yˉ, maintaining the advantageous latent space properties of RRAEs. Key advantages include:
- Enhanced Regularization: The inherent regularization imposed by the truncated SVD strengthens latent space representation without necessitating additional optimization objectives, leading to sharper image generation.
- Resilience Against Posterior Collapse: VRRAEs exhibit greater robustness to posterior collapse by constraining the possible collapse points to specific values related to latent singular values, as opposed to arbitrary collapse vectors.
These benefits manifest as performance improvements on generative tasks, evidenced by empirical tests on synthetic datasets and real-world scenarios (MNIST, CelebA, CIFAR-10).
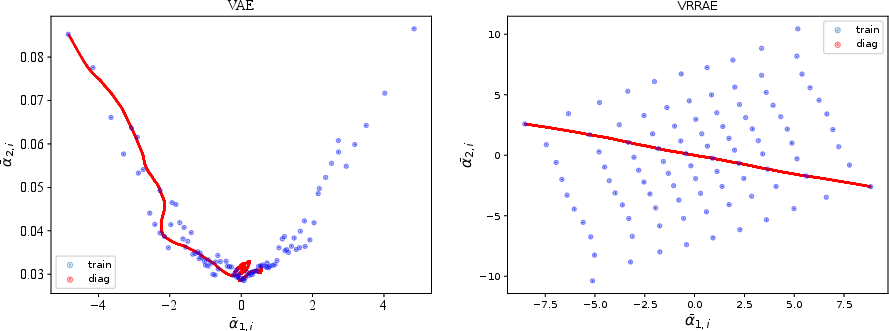
Figure 2: Visualization of the second latent mean plotted against the first one for VAEs (left) and VRRAEs (right). The collapse of the second latent dimension in VAEs is evidenced by small variations in the y-axis.
Empirical Results
VRRAEs were evaluated against standard RRAEs, VAEs, and traditional Autoencoders using metrics including reconstruction error and Fréchet Inception Distance (FID) scores for interpolation and random sample generation:
- Synthetic Dataset: The synthetic Gaussian dataset illustrates VRRAEs' ability to resist posterior collapse more effectively than VAEs, thereby generating samples with reduced errors in more constrained environments.
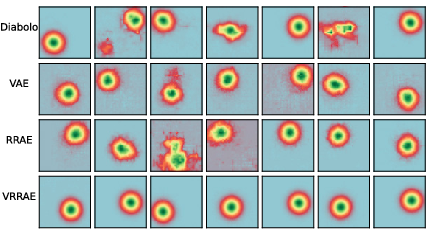
Figure 3: Randomly generated samples for different architectures on the 2D Gaussian problem.
- Real-World Data (MNIST, CIFAR-10, and CelebA): VRRAEs outperformed both RRAEs and VAEs in generating clearer images with lower reconstruction errors, maintaining advantageous FID scores across random generation and interpolation tasks.
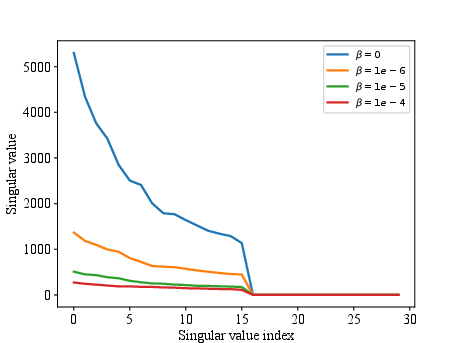
Figure 4: The singular values (by VRRAEs) of the training latent space on the MNIST dataset for different contributions of the KL divergence (i.e., different values of beta). Note the bottleneck enforced with k∗=16.
Ablation Studies
An ablation study further confirmed the critical choice of using f=I (identity map) for sampling mean values in VRRAEs. The identity function ensures regularization properties integral to the RRAE structure remain unimpeded by probabilistic sampling effects. Additionally, the role and value of β were assessed and shown to be pivotal in maintaining sample quality and enforcing latent space regularization.
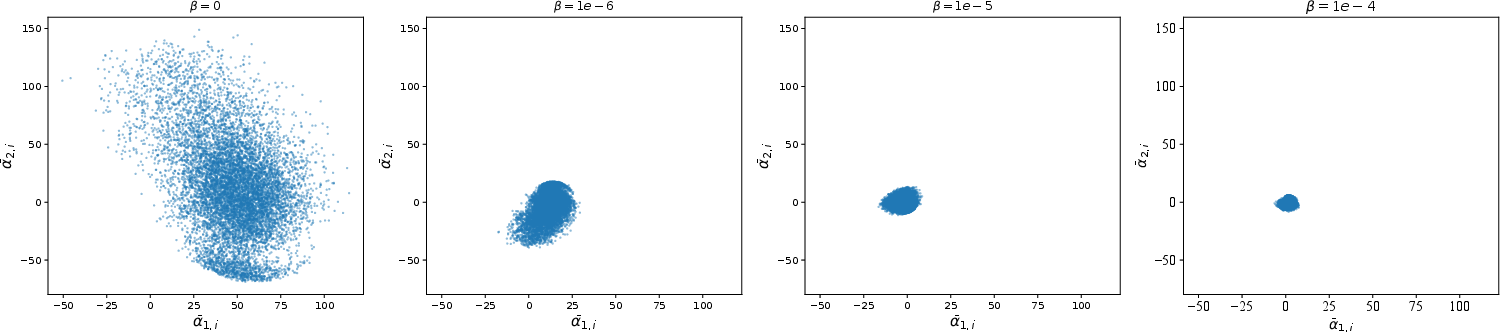
Figure 5: The mean of the second latent dimension against the mean of the first latent dimension for VRRAEs on the MNIST dataset for different values of beta.
Conclusion
VRRAEs represent an effective methodology for integrating the deterministic strengths of singular value-based regularization with the generative frameworks of VAEs. This development significantly reduces common generative model failures, achieving superior results in terms of reconstruction and sample quality across synthetic and real-world datasets. Future work may explore extending VRRAEs to incorporate more sophisticated regularization mechanisms or adaptive latent space manipulation to further enhance generative performance and applications in complex, high-dimensional datasets.