- The paper introduces clustering-based client selection to reduce energy consumption in federated learning for AIoT.
- It compares SimClust and RepClust methods, demonstrating significant energy savings and improved convergence on benchmarks like CIFAR-10.
- The research highlights energy-efficient techniques that extend AIoT device lifespan while preserving model accuracy.
Energy-Efficient Federated Learning for AIoT using Clustering Methods
Introduction
The paper "Energy-Efficient Federated Learning for AIoT using Clustering Methods" (2505.09704) addresses the critical issue of energy consumption in Federated Learning (FL) settings within Artificial Intelligence of Things (AIoT) applications. While FL has been recognized for its ability to tackle privacy concerns by processing data locally rather than transmitting all data to centralized servers, this research identifies specific energy-intensive processes, namely preprocessing, communication, and local learning, that contribute significantly to the energy footprint of FL systems.
This paper presents novel clustering-informed methods for device/client selection in FL, aiming to optimize energy consumption without sacrificing model performance. The authors propose two clustering solutions that organize AIoT devices based on data similarity, alleviating the heterogeneity in label distribution and thereby enhancing convergence rates while minimizing energy costs.
Energy Consumption in FL
In traditional centralized learning, energy costs are heavily incurred during data transmission and computation. However, in decentralized systems like FL, the largest contributors to energy expenditure are often the local computations required during training. The research highlights that AIoT systems spend a greater portion of energy during training than during communication, a finding depicted in their experimental results.
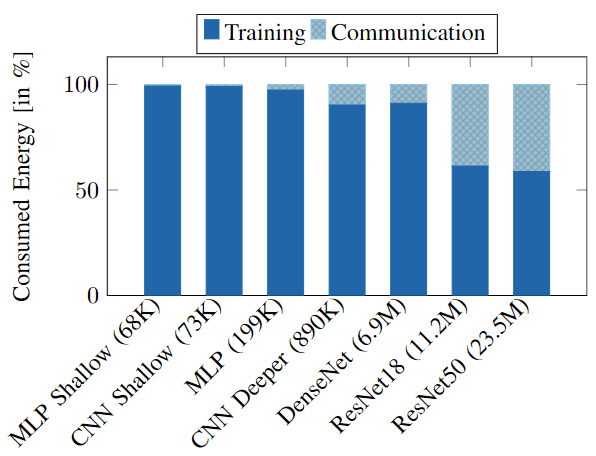
Figure 1: Percentage of the total energy consumed during training (solid) and communication (striped) stages of a heterogeneous FL process with 100 clients learning on CIFAR-10 dataset.
The realization that training dominates energy costs shifts the focus of optimization from solely communication-efficient methods to comprehensive strategies that also consider the energy consumption of training processes.
Clustering-Based Client Selection
The proposed methods focus on clustering clients to maximize the utility of selected data representations. By grouping devices with similar data characteristics, such as label distribution, the selection of participating clients in each communication round becomes more informed and energy-efficient. Notably, two clustering methods are introduced:
- SimClust (Similarity Clustering): Clusters clients with similar data distributions. This method aims to avoid redundant data processing by ensuring diverse data contributions across the clustered devices.
- RepClust (Repulsive Clustering): Focuses on maximizing group diversity. Instead of selecting clients based solely on similarity, this approach forms groups that are internally diverse yet similar to other groups, ensuring that each communication round covers a broad data spectrum.
These methods are computed prior to training and remain static during the training phase, significantly reducing computational overhead compared to more dynamic approaches like active client sampling.
Evaluation and Results
The research employs comprehensive numerical experiments across datasets like CIFAR-10 and F-MNIST to validate the energy efficiency and accuracy of the proposed clustering methods. It was observed that both SimClust and RepClust efficiently balance the trade-off between energy consumption and model performance, outperforming traditional random client selection and existing methods like FedCor in heterogeneous data scenarios.
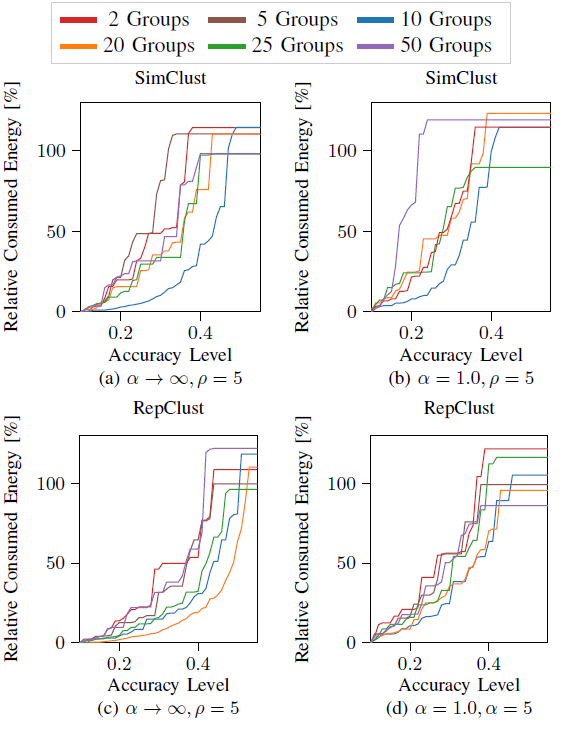
Figure 2: Impact in energy and accuracy of the number of clusters (different colors) for SimClust and RepClust in a homogeneous scenario with α→∞, and a heterogeneous scenario with α=1.0.
Their results demonstrate substantial energy savings during FL training without compromising accuracy. This highlights the effectiveness of clustering-based strategies in achieving energy-efficient learning in AIoT environments, where device constraints are critical.
Implications and Future Work
The implications of this research are significant for the deployment of FL in AIoT networks, where energy resources are limited. By reducing energy consumption, these methods extend the operational lifespan of AIoT devices and promote sustainable practices in deploying machine learning solutions at scale.
Future work could explore integrating these clustering strategies with privacy-preserving techniques and further optimizing them for large-scale, real-world AIoT deployments. Additionally, the exploration of decentralized clustering approaches and their impact on data privacy and energy consumption presents a rich avenue for further research.
Conclusion
The paper makes a substantial contribution by introducing energy-efficient clustering-based client selection methods for FL in AIoT applications. By addressing the primary energy-consuming elements of FL, these techniques not only enhance model convergence but also align with the sustainable operation of distributed learning systems. The approach underscores the need for holistic energy management strategies in future AIoT frameworks, setting a foundation for continued innovation in this space.