- The paper demonstrates that tuning superposition through weight decay is pivotal in achieving robust loss scaling across model dimensions.
- The method leverages an autoencoder toy model to analyze how weak and strong superposition regimes distinctly affect feature frequencies and loss distributions.
- The study validates that low variance in overlapping representations results in an inverse-dimension loss scaling, reinforcing LLM performance predictions.
Introduction
The paper "Superposition Yields Robust Neural Scaling" (arXiv ID: (2505.10465)) investigates the phenomenon of neural scaling laws in LLMs, focusing on the role of superposition in representation. Neural scaling laws describe the empirical observation that larger models tend to exhibit lower loss and better performance, often characterized by a power-law decrease in loss with model size. This study explores the hypothesis that representation superposition—where a model can represent more features than its dimensional space—underlies these scaling behaviors.
Methods
Utilizing Anthropic's toy model, the authors employ weight decay to adjust the degree of superposition, thereby systematically analyzing its impact on loss scaling. The toy model acts as an autoencoder with specific protocols for data sampling, representing features as activation vectors. Key principles in the model include data sparsity and differential feature frequencies, which are manipulated to observe their effects on superposition and subsequent loss scaling.
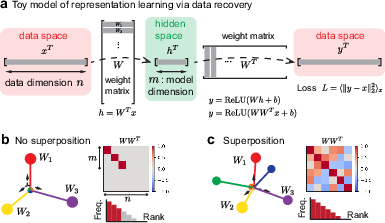
Figure 1: Toy model of superposition showing architecture and loss distribution, where superposition allows representation overlap.
Weight decay is used strategically to tune the degree of superposition. Positive weight decay biases towards weak superposition, where frequent features have near-zero representations. Conversely, negative weight decay promotes strong superposition, ensuring that representations overlap significantly. The efficacy of weight decay in controlling superposition is evidenced by the observed bimodal distribution of feature norms and robust superposition when small weight decay values are applied.
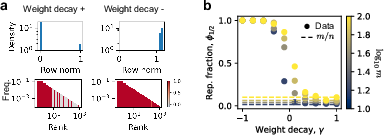
Figure 2: Weight decay tuning superposition levels effectively; small decay leads to strong superposition, large decay aligns with weak superposition.
Results
Weak Superposition Regime
In the weak superposition regime, the loss scaling is sensitive to the decay of feature frequencies with rank. It's demonstrated that loss adheres to a power-law form provided the feature frequencies themselves follow a power law. Specifically, the model exponent correlates with the data exponent, suggesting that loss scales as the sum of ignored feature frequencies.
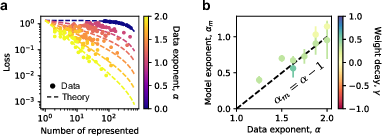
Figure 3: Loss description at weak superposition aligns with the frequency sum of ignored features.
Strong Superposition Regime
Strong superposition facilitates robust loss scaling independently of feature frequency distributions. Loss here scales inversely with model dimension due to geometric interference between overlapping representation vectors, akin to isotropic vector configurations. The phenomena are supported by low variance in overlaps among features with higher norm, indicating ETF-like behavior, which enhances model robustness.
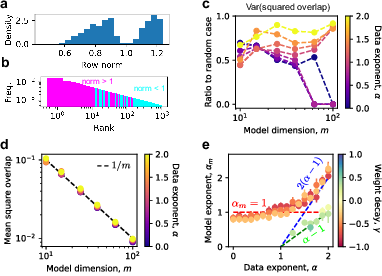
Figure 4: Loss scaling in strong superposition explained via geometric overlaps, maintaining consistency across feature distributions.
Application to LLMs
Empirical analysis of various LLM classes reveals that these models operate in the strong superposition regime, confirmed by the scaling of squared overlaps and token frequency distributions. Evaluated losses exhibit similar scaling patterns, reinforcing the theoretical predictions. The models display a mean squared overlap scaling as $1/m$, which corresponds to the inverse dimension scaling found in the toy model.
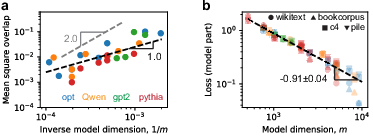
Figure 5: Superposition elucidating LLM scaling laws, across different models and datasets with consistent $1/m$ loss scaling.
Conclusion
The study identifies superposition as a pivotal element underpinning neural scaling laws in LLMs. By controlling superposition through weight decay, researchers can elucidate the conditions under which models exhibit robust scaling of loss with dimension. This work contributes to a refined understanding of LLM behaviors and offers pathways for optimizing model design and training strategies. Future research could expand on parsing-limited scaling and parse-layer behaviors, bridging the gap between theoretical models and practical deployment outcomes.

