- The paper introduces mmRAG, a modular benchmark evaluating retrieval-augmented generation using multi-modal datasets from text, tables, and knowledge graphs.
- It provides granular diagnostics by separately assessing retrieval, query routing, and generation components with cross-dataset relevance annotations.
- Baseline evaluations of classic and neural retrievers underscore mmRAG’s potential to drive improvements in complex RAG systems.
"mmRAG: A Modular Benchmark for Retrieval-Augmented Generation over Text, Tables, and Knowledge Graphs" (2505.11180)
Introduction and Motivation
The paper "mmRAG: A Modular Benchmark for Retrieval-Augmented Generation over Text, Tables, and Knowledge Graphs" addresses the limitations of existing Retrieval-Augmented Generation (RAG) benchmarks, which primarily focus on single-modal text retrieval and often rely on end-to-end assessments. These evaluations obscure the granularity needed to distinguish failures in retrieval from those in generation. The authors introduce mmRAG, a novel benchmark designed to facilitate a more detailed evaluation across multiple modalities—specifically text, tables, and knowledge graphs (KGs). The benchmark aims to provide comprehensive diagnostics by evaluating specific RAG components, including retrieval and query routing accuracy, using cross-dataset relevance annotations.
Contributions and Novel Features
The mmRAG benchmark offers the following innovations:
- Unified Multi-Modal Corpus: It amalgamates datasets from different modalities, including text, tables, and KGs, creating a comprehensive environment for evaluating RAG systems’ performance across these diverse data types.
- Cross-Dataset Relevance Annotation: By annotating queries with relevant document chunks across all involved datasets, mmRAG allows for the direct measurement of retrieval accuracy and ensures that the benchmark reflects real-world scenarios where information might span multiple data sources.
- Whole-Process Modular Evaluation: The benchmark provides distinct annotations for various components of the RAG process — from query routing to retrieval and generation — enabling thorough performance diagnostics for each component separately.
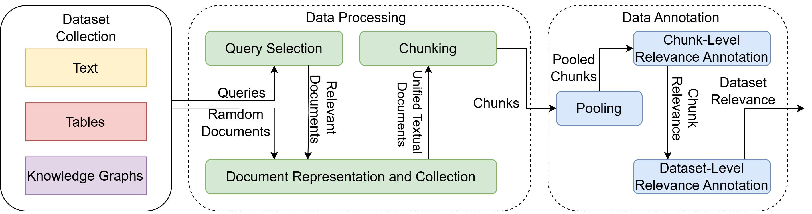
Figure 1: Construction of mmRAG.
Methodology for Benchmark Construction
The construction of mmRAG comprises three main phases: dataset collection, data processing, and data annotation.
- Dataset Collection: The benchmark draws from six diverse QA datasets encompassing text, tables, and KGs, selected to cover a broad range of real-world query types and reasoning tasks. This collection allows mmRAG to evaluate RAG systems’ handling of complex, heterogeneous data.
- Data Processing: This phase involves the selection and processing of documents into retrievable chunks. Techniques include clustering for query selection, transforming dataset corpora into unified document formats, and segmenting documents into manageable chunks for efficient retrieval.
- Data Annotation: Utilizing a standardized IR pooling method and LLM-based automatic annotation, mmRAG provides detailed relevance labels for retrieval and queries. Importantly, it also introduces dataset-level relevance labels, crucial for evaluating routing accuracy.
Evaluation of Retrievers and Query Routers
The authors establish baseline performances for a variety of retrieval models ranging from classic lexical methods like BM25 to modern neural models such as BGE and GTE. These models were evaluated using standard IR metrics, yielding insights into their retrieval efficiencies and guiding future improvements in RAG systems.
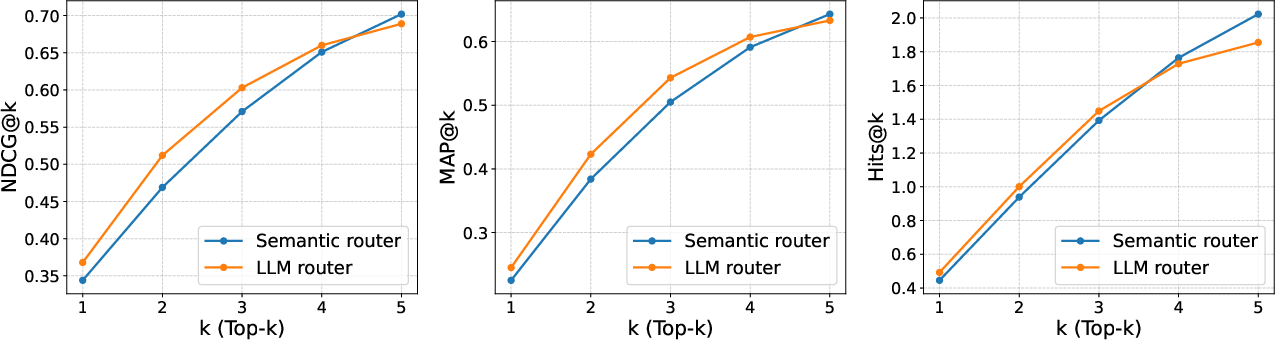
Figure 2: Evaluation of query routers (routing accuracy).
Furthermore, mmRAG facilitates the evaluation of query routers, comparing semantic and LLM-based routing strategies. Direct evaluation with the dataset-level relevance labels was shown to be an effective measure for routing accuracy, providing a more nuanced assessment compared to generation quality metrics alone.
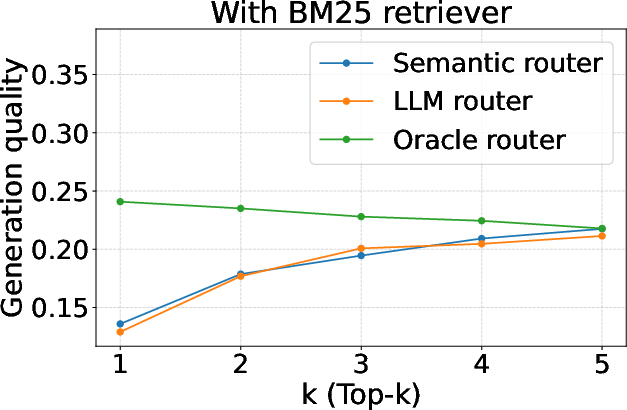
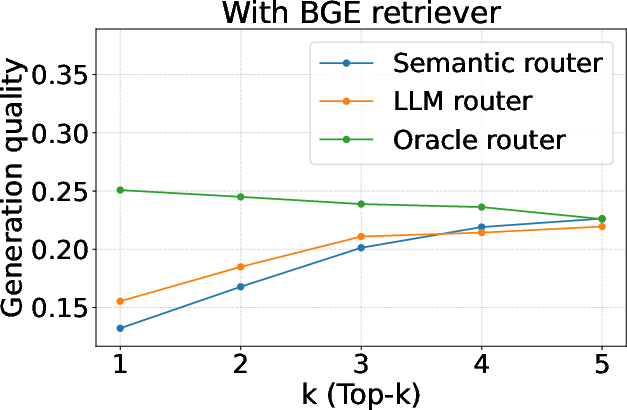
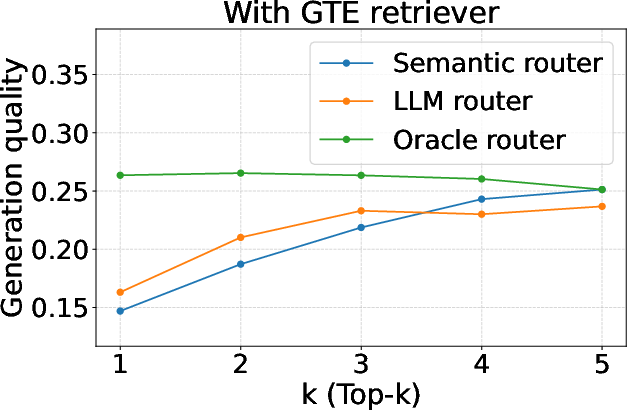
Figure 3: Evaluation of query routers (generation quality).
Implications and Future Directions
The introduction of mmRAG represents a pivotal advancement for RAG benchmarking, enabling detailed, component-level evaluation that surpasses the capabilities of previous benchmarks. By facilitating evaluation at multiple levels — from retrieval to generation — and across multiple data modalities, mmRAG sets a new standard for diagnosing and optimizing RAG systems.
Future work involves expanding the benchmark to encompass additional modalities, such as images, and optimizing the annotation process to enhance scalability. Additionally, exploring domain-specific data splits could further refine the evaluation of RAG systems within particular fields like medicine or law.
Conclusion
mmRAG advances RAG research by providing a detailed, multi-modal, and modular benchmark. It offers significant insights into retrieval, query routing, and generation, all essential for the continued enhancement of RAG systems. The benchmark's robust design aims to inspire further research into retrieval-augmented generation and encourage a broader adoption of diverse knowledge sources in machine learning applications.