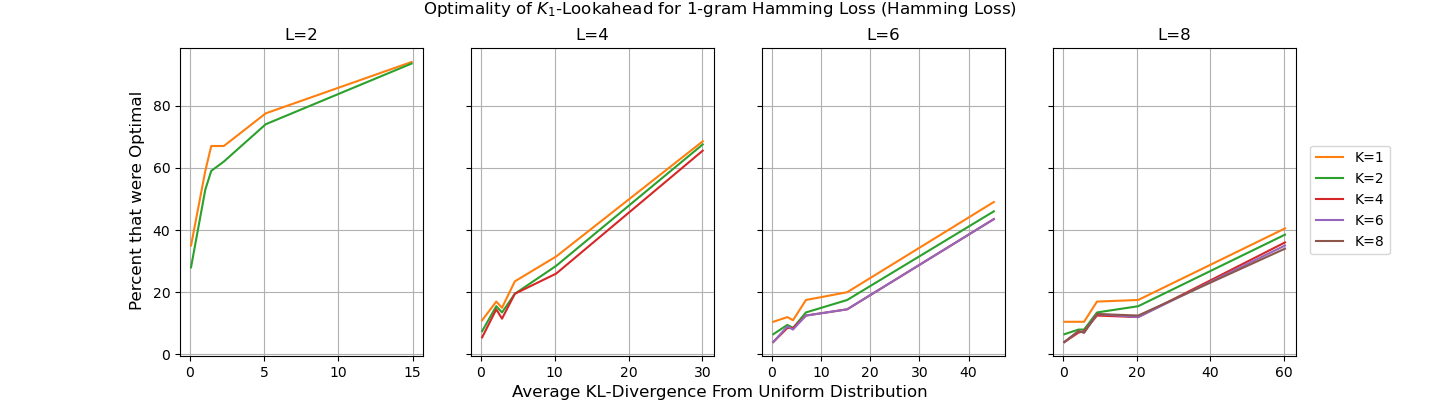
- The paper demonstrates that while $K_T$-lookahead decoding generalizes greedy methods, it often falls short of achieving consistent optimality across all token distributions.
- The study reveals that random sampling aligns well with cross-entropy loss, whereas temperature-scaled sampling introduces trade-offs between diversity and deterministic retrieval.
- Empirical analyses using Markov chains confirm that no polynomial-time algorithm consistently optimizes deterministic losses like the Hamming loss.
On Next-Token Prediction in LLMs: How End Goals Determine the Consistency of Decoding Algorithms
This paper examines the relationship between next-token prediction in LLMs and the decoding algorithms employed to achieve specific end goals. The discussion involves both theoretical analysis and empirical evaluation, providing insights into the consistency of these algorithms, particularly with respect to surrogate loss functions.
Introduction
The standard method for training LLMs involves probabilistic next-token prediction using cross-entropy loss. This process predicts the likelihood of different tokens being the next in a sequence. Various decoding algorithms such as greedy, KT-lookahead, and stochastic sampling are utilized to generate complete sequences from these predictions. Despite the wide adoption of these algorithms, there is limited theoretical understanding of how well they align with different end goals encoded as loss functions. This paper explores evaluating the asymptotic consistency of several decoding methods concerning their surrogate loss functions like Hamming loss and sequence cross entropy.
Decoding Algorithms and Consistency
The consistency of KT-lookahead is contextual and sensitive to the asymptotic behavior of next-token prediction converging to true distributions. The inability to universally optimize across all possible distributions without exponential time computations marks a significant challenge.
Optimality Across Probability Distributions
The paper asserts that no polynomial-time decoding algorithm achieves optimality for the N-gram Hamming loss across all distributions. The intricacies of sequential decision-making introduce computational complexities that inherently limit consistent optimality:
- Deterministic Outcomes: Consistency for deterministic targets like Hamming loss necessitates deterministic decoding strategies, which stochastic algorithms inherently cannot fulfill.
- Stochastic Necessity: In contrast, tasks involving distributional mimicry (e.g., artificial sample generation) highlight the necessity for stochastic approaches (e.g., random sampling due to its inherent consistency with cross-entropy optimization).
Empirical Evaluations
Empirical evaluations conducted using fully connected Markov chains illustrate the diverse performance outcomes of KT-lookahead across varied distributions. The analysis highlights scenarios where KT-lookahead decoders excel and where they falter, underlining the necessity to tailor decoding strategies to specified end goals:
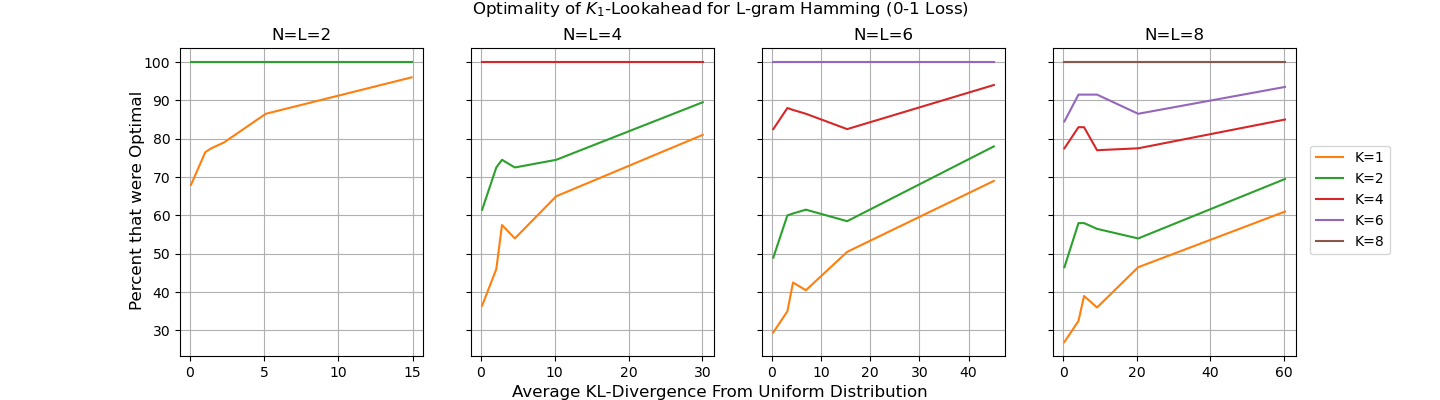
Figure 2: A plot of the amount of trials K1-lookahead was optimal for the L-gram Hamming loss (the 0-1 loss), showing improved performance with increasing sequence length.
Conclusion
The investigation into decoding algorithm consistency presented in this paper underscores the dichotomy between information retrieval goals and creative generation objectives in LLM applications. The findings suggest that decoding strategies should be aligned with the specific end-user intent to optimize outcomes effectively. Future work could explore adaptive algorithms dynamically adjusting decoding strategies based on real-time evaluation of user intent or contextual requirements.
Ultimately, this paper provides a framework for understanding the trade-offs inherent in different decoding strategies, elucidating their strengths and limitations in yielding consistent and optimal results under varied circumstances. These insights contribute critically to the theoretical grounding needed to design more effective and purpose-driven LLM applications.