- The paper demonstrates that RL training can implicitly induce strong process-reward capabilities in LLMs, reducing the need for explicit PRM supervision.
- The paper shows that end-to-end RL yields higher process-level judgment F1 scores (>83) compared to explicit PRM methods and voting techniques.
- The paper identifies limitations in Self-PRM precision on challenging tasks, highlighting the need for further research in fine-grained reward alignment.
Emergent Process Reward Model Capability via Reinforcement Learning in LLMs
Introduction
The paper "Is PRM Necessary? Problem-Solving RL Implicitly Induces PRM Capability in LLMs" (2505.11227) interrogates the necessity of explicit process reward models (PRMs) for cultivating process-level reasoning skills in LLMs. Historically, PRMs have been proposed to guide models by providing granular supervision across intermediate reasoning steps, purportedly yielding interpretable and robust problem-solving. These models, however, face persistent obstacles: ambiguity in stepwise annotation, supervision costs, and vulnerability to reward hacking. This work presents comprehensive empirical evidence that the process-level judgment capacities—a hallmark of PRMs—can arise organically through RL focused solely on end-to-end problem-solving, negating the need for explicit process supervision.
Empirical Correlation Between RL and PRM Capabilities
A systematic evaluation using ProcessBench, composed of GSM8K, MATH, OlympiadBench, and OmniMath, reveals that models solely trained via RL (notably DeepSeek-R1 and QwQ-32B) substantially exceed the process-level judgment performance of PRM-supervised models. Both final answer accuracy and ProcessBench F1 (judging the correctness of each reasoning step) are elevated, with the RL-trained models attaining mean F1 scores above 83, while the best discriminatively-trained PRM models plateau below 80.
Chi-square tests further quantify the relationship between end-task problem-solving accuracy and process-step judgment, showing statistically significant positive correlations (p < 0.05) across datasets and models. The implication is that as RL improves a model's capacity for accurate solutions, it also internally develops the ability to discern flawed versus valid intermediate steps, tightly coupling these competencies.
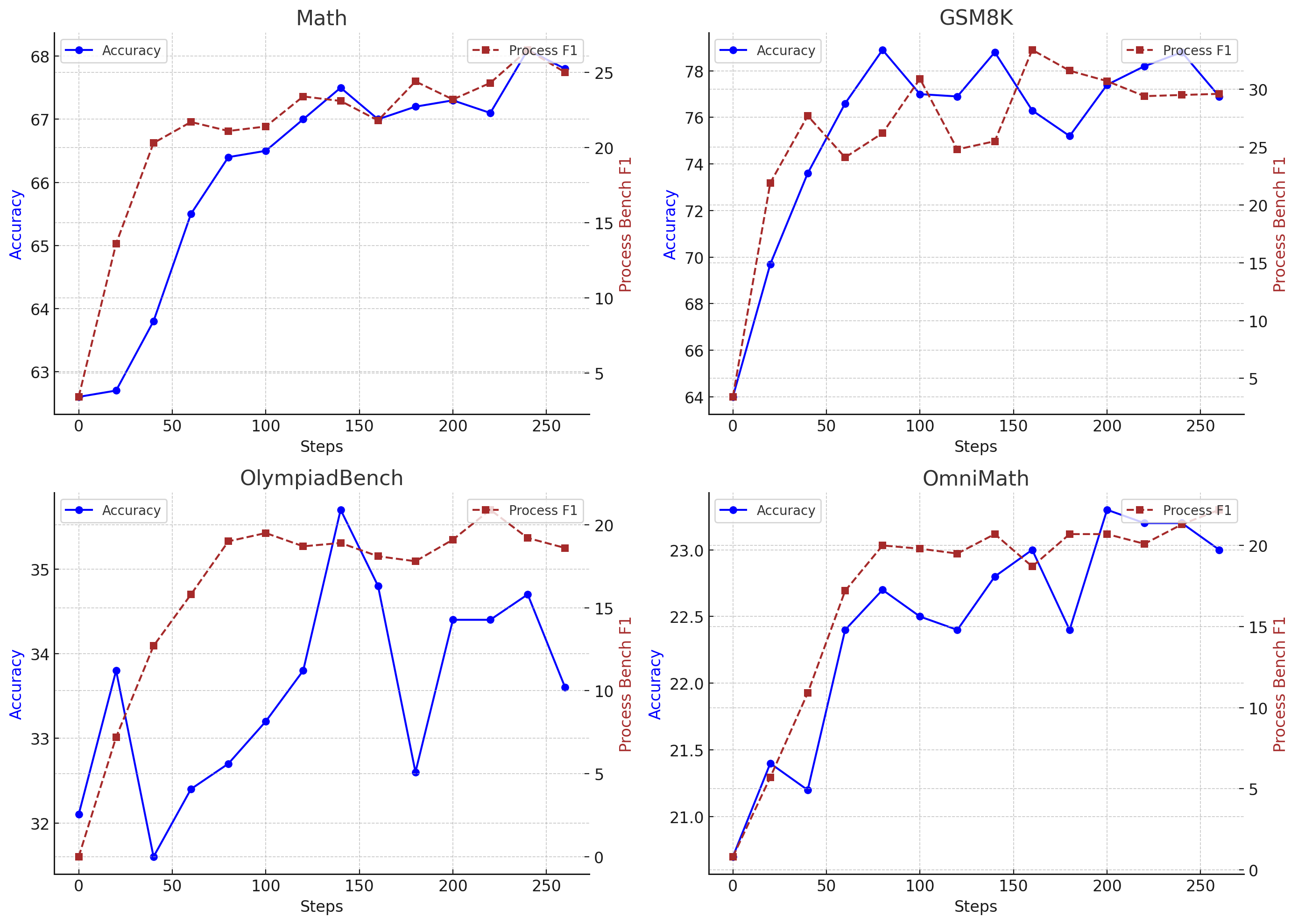
Figure 1: Problem Solving Accuracy and F1 Results of the RL-trained model on ProcessBench. We leverage Qwen2.5-7b-base for RL training.
Analysis of learning curves in RL training demonstrates coordinated and, in some instances, leading improvements in process-level F1 compared to answer accuracy. On benchmarks like MATH and GSM8K, gains in stepwise judgment precede overall accuracy, indicating that RL agents first internalize the ability to recognize correct reasoning structures before optimizing final solutions. This trend is persistent across more challenging datasets and out-of-domain generalization scenarios.
Limitations of External and Self-Reference PRMs
Rigorous experiments with external PRMs (e.g., Qwen2.5-MATH-PRM-72B) employed for reranking candidate solutions from strong RL-trained models show that these auxiliary reward signals fail to enhance, and often degrade, performance compared to voting-based heuristics. This observation holds across multiple mathematical reasoning evaluations and diverse sample sizes. It suggests that model-internal reward alignment has outpaced the discriminatory capacity of external PRMs, making the latter obsolete for best-in-class RL agents.
Attempts to enhance PRM alignment via self-generated traces (Self-REF) uncover that such supervision is beneficial only for models lacking RL, such as instruction-tuned architectures. For RL-trained or distillation-augmented models, Self-REF yields marginal or negative returns, corroborating the premise that end-to-end RL objectives supersede the contribution of stepwise self-supervision once models are incentivized for coherent reasoning.
Conversely, leveraging the model as its own process reward judge (Self-PRM)—reranking outputs by internal reward scores—results in consistent incremental performance gains over both external PRM-based and majority-voting selection, especially at large candidate set sizes (k=32, 64). These improvements furnish strong evidence that process-reward alignment emerges robustly via RL, and the model’s introspective self-assessment tracks closely with its problem-solving ability.
Precision Limits and Failure Modes of Self-PRM
Despite aggregate improvements, fine-grained analysis uncovers that Self-PRM methods can suffer from low precision on hard problems. On challenging cases, models often misclassify a high proportion of incorrect solutions as valid. For example, among solutions identified as correct by Self-PRM for a hard CNMO24 problem, only 2 out of 55 (QwQ-32B) and 10 out of 39 (DeepSeek-R1) were truly valid, yielding precision rates far below 30%. Notably, stronger models exhibit higher Self-PRM precision but retain significant error modes. This suggests that full alignment between process-judgment and solution validity is not universally achieved purely via current RL scaling and that further methodological advances, such as joint process-based supervision or extended RL training, are necessary to mitigate overconfident model introspection.
Theoretical and Practical Implications
The central claim—that explicit PRM supervision is unnecessary for fostering PRM-like capabilities in LLMs when sufficiently capable RL training is performed—is both numerically substantiated and theoretically significant. This finding challenges the prevailing paradigm that process-level supervision is a prerequisite for interpretable, robust, and reliable model reasoning. It positions RL from answer-level reward not merely as a tool for solution accuracy but as a powerful mechanism for holistic reward and process alignment.
Practically, these results streamline the development of advanced reasoning models by obviating costly intermediate annotation and the complexity of PRM design. The strong empirical co-evolution of problem-solving skill and process judgment under RL opens the door to leaner training pipelines and the emergence of more self-correcting LLMs. The observed failure modes of Self-PRM also delineate important directions for future research in reward alignment, safe deployment, and the closure of introspective gaps.
Future Directions
Advancing internal reward alignment and process-judgment accuracy in LLMs will benefit from additional RL scaling, exploration of hybrid joint training with fine-grained PRM objectives, and the introduction of self-critique mechanisms. Further work should extend these findings outside of the mathematical domain to diverse reasoning scenarios to evaluate generality. The limitations of Self-PRM on “hard” out-of-distribution problems also motivate research into selective confidence estimation and dynamic supervision strategies.
Conclusion
This work rigorously demonstrates that modern RL techniques, applied to LLMs for problem-solving, intrinsically induce strong process-reward model capabilities—rendering explicit PRM training unnecessary for advanced mathematical reasoning. RL-trained models not only solve complex tasks but also internally judge the validity of stepwise reasoning comparable to, or exceeding, specialized PRMs. While introspective reward mechanisms like Self-PRM further capitalize on this alignment, persistent precision gaps on challenging instances highlight reward alignment as an ongoing frontier.
These findings materially impact the theoretical understanding of reasoning skill acquisition in LLMs and inform the design of highly capable and interpretable AI systems—pointing towards an RL-first strategy for robust, self-aware, and annotation-light model development.