- The paper demonstrates that fine-tuned LLMs like SuperCoder achieve 95.0% correctness and 1.46× speedup over gcc -O3.
- The methodology leverages reinforcement learning techniques (PPO and GRPO) on a robust CodeNet dataset to optimize assembly code while ensuring functional equivalence.
- The study highlights advanced optimizations, including instruction scheduling and improved register allocation, with implications for future compiler integration.
SuperCoder: Assembly Program Superoptimization with LLMs
Introduction
Superoptimization involves transforming a program to enhance its performance while maintaining its original functionality. The research on utilizing LLMs for this task addresses the potential of these models to function as superoptimizers, specifically for assembly programs that have already undergone optimization by high-performance compilers like gcc -O3. The significance of this work lies in demonstrating the capacity of LLMs, exemplified by the SuperCoder model, to further optimize code beyond what conventional compilers achieve.
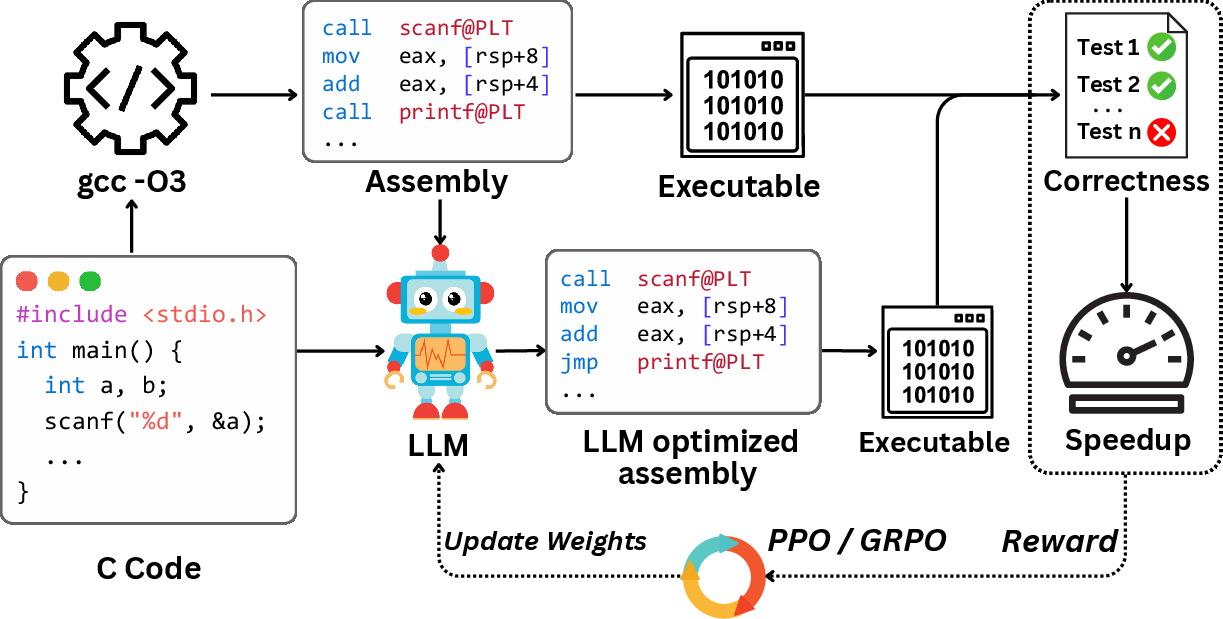
Figure 1: Overview of the assembly code optimization task. Given a C program and its baseline assembly from gcc -O3, an LLM is fine-tuned with PPO or GRPO to generate improved assembly. The reward function reflects correctness and performance based on test execution.
Methodology
Task Definition
The goal is to produce an assembly program P′ that is functionally equivalent to a given program P, such that P′ executes faster. The baseline P is generated from a high-level language program C using gcc at the -O3 optimization level. Functional equivalence is verified using a test set T, with rewards based on performance speedups over gcc -O3.
Dataset Construction
A significant dataset is constructed from CodeNet submissions, focusing on assembly programs where gcc -O3 provides the highest relative speedup compared to gcc -O0. The dataset comprises 8,072 training instances and 200 validation instances, designed to represent complex code structures suitable for high-level optimizations.
Reinforcement Learning Framework
The task is framed as a contextual multi-armed bandit problem. Training employs two reinforcement learning algorithms: Proximal Policy Optimization (PPO) and Group Relative Policy Optimization (GRPO). These algorithms are adapted to maximize speedup rewards while ensuring the generated assembly is both correct and performance superior.
Experimental Setup
The experimental setup involves evaluating 23 LLMs, incorporating comprehensive metrics for both correctness (compile- and test-pass rates) and performance (execution speedup over baseline). The best results under baseline conditions were achieved by Claude-opus-4 with a 51.5% test pass rate and an average speedup of 1.43×.
Results and Analysis
Model Evaluation
The evaluated LLMs exhibit diverse performance on the assembly optimization task. Notably, the SuperCoder model, when fine-tuned using reinforcement learning, achieved significant improvements: a 95.0% correctness and an average speedup of 1.46× over gcc -O3. This performance validated the hypothesis that LLMs can transcend traditional compiler optimization limits.
SuperCoder exhibited advanced code transformations mainly through instruction scheduling and code layout adjustment, demonstrating a capability to effectively reassemble assembly code to exploit modern CPU architectures' performance characteristics. Additional optimizations included improved register allocation and control flow simplifications.
Implications and Future Work
The implications of this research are substantial in compiler optimization and code generation fields. By demonstrating the viability of LLMs as superoptimizers, this work suggests that future compilers could integrate machine learning components to anticipate and apply optimizations beyond the rule-based confines existing today. Further exploration is warranted into interactive model refinement and expanding these methods to diverse hardware architectures and GPU kernels.
Conclusion
The study on using LLMs for superoptimization, epitomized by SuperCoder, provides compelling evidence of the models' potential to enhance assembly program execution beyond industry-standard compiler optimizations. The establishment of a robust benchmark and notable performance improvements underscore a promising trajectory in AI-driven code optimization, inviting further inquiry and application in the broader landscape of software engineering.