- The paper introduces Adaptive Constrained Equivariance (ACE), which dynamically transitions networks from non-equivariant to equivariant states.
- It employs a homotopic optimization framework with layer-wise modulation coefficients to balance symmetry constraints during training.
- ACE offers theoretical error bounds and demonstrates empirical improvements in accuracy, sample efficiency, and robustness across diverse datasets.
Learning (Approximately) Equivariant Networks via Constrained Optimization
Introduction
The paper introduces "Adaptive Constrained Equivariance" (ACE), a novel approach for training neural networks while managing equivariance constraints. The methodology leverages constrained optimization to adjust a model's equivariance during training, enhancing performance across various tasks. The essential premise is that models strictly adhering to equivariance may struggle with real-world data often marred by symmetry-breaking noise. ACE addresses these challenges by dynamically navigating between non-equivariant and equivariant states.
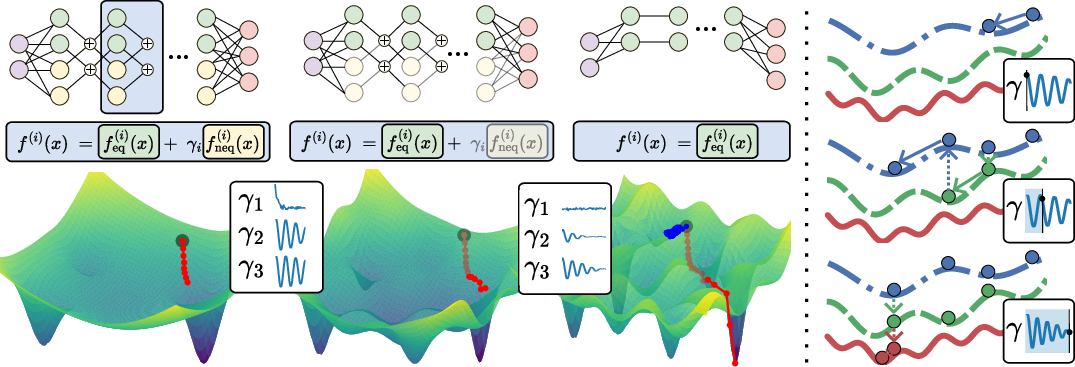
Figure 1: The proposed ACE homotopic optimization scheme at a glance. Left: The red trajectory illustrates training of a relaxed, non-equivariant model that gradually becomes equivariant as the layer-wise γi decay. The blue trajectory illustrates a strictly equivariant network feq trained from the same initialization.
Methodology
ACE employs a homotopy-inspired framework where the training begins with a flexible, non-equivariant model. Over iterations, the model adapts its level of equivariance through the modulation coefficients γi. The ACE scheme uses constrained optimization to balance strict equivariance and non-equivariance, allowing the model to adhere as needed based on data characteristics. This adjustment mitigates manual tuning and hyperparameter dependency seen in prior approaches.
Mathematically, ACE exploits dual methods in optimization, akin to simulated annealing, to decrease γi iteratively, transitioning from non-equivariant to strictly equivariant as the model converges. By casting this transition as a constrained optimization problem, ACE automatically adjusts the constraints to maintain a balance between performance metrics like accuracy and equivariance.
Theoretical Guarantees
The proposed framework furnishes explicit bounds on both approximation errors for fully equivariant models and equivariance errors for partially equivariant models. These theoretical insights ensure that ACE can robustly handle relaxation and imposition of symmetry constraints, improving generalization without degrading convergence speed.
The central theoretical contribution includes:
- Approximation Error Bound: This bound quantifies the error introduced by partial equivariance, ensuring solutions remain close to optimal.
- Equivariance Error Bound: Provides a measure for how deviations in γi relate to equivariance errors, supporting automated equivariance adjustments during training.
Empirical Evaluation
ACE was empirically validated across multiple datasets and tasks, consistently showing improvements in sample efficiency, accuracy, and training robustness.
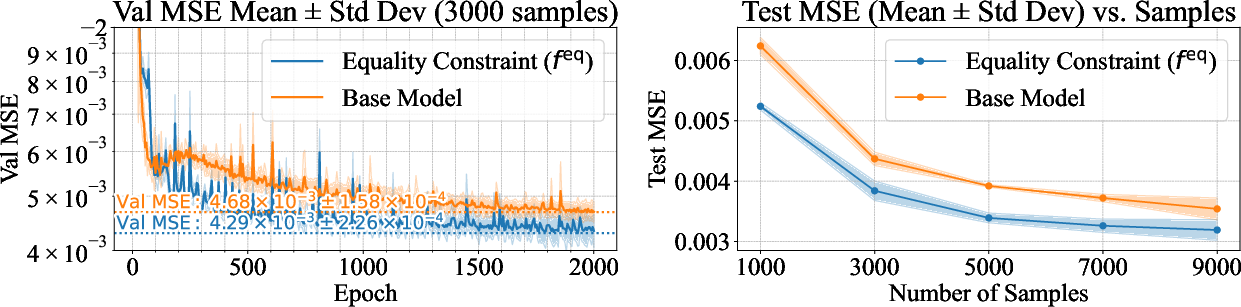
Figure 2: SEGNN trained with ACE equality constraints compared with the normal SEGNN on the N-Body dataset. Left: Validation MSE over 2000 epochs. Right: Test MSE versus training set size.
In setups where input degradation is induced, ACE-trained models demonstrated stable and superior performance with reduced data, illustrating enhanced sample efficiency. Experiments on complex motion datasets (e.g., CMU MoCap) highlighted ACE's ability to outperform traditional and strictly equivariant models, especially through resilience-based inequality constraints.
Conclusion
ACE emerges as a potent method for improving neural networks by dynamically balancing equivariance and performance through constrained optimization. It aligns network training with data symmetry properties, which vary across real-world applications. Future work could explore extending ACE across additional domains and devising architectures that innately leverage its dynamic symmetry negotiation capabilities, pointing towards broader applications in AI.
The integration of symmetry negotiation within machine learning offers a promising avenue for models to adaptively harness structural information, promoting efficient and robust learning outcomes across disciplines.