- The paper introduces ReasonRAG, a reinforcement learning framework that leverages process-level rewards to optimize agentic RAG systems.
- It employs Monte Carlo Tree Search and Shortest Path Reward Estimation to efficiently explore decision spaces and evaluate reasoning trajectories.
- Experimental results demonstrate that ReasonRAG improves training stability, reduces computational costs, and outperforms traditional outcome-supervised methods.
Process vs. Outcome Reward in Agentic RAG Reinforcement Learning
The paper "Process vs. Outcome Reward: Which is Better for Agentic RAG Reinforcement Learning" explores a novel approach to reinforcement learning (RL) in retrieval-augmented generation (RAG) systems. It introduces the ReasonRAG method, which utilizes process-level rewards to address challenges in agentic RAG systems, offering improvements over traditional outcome-supervised RL methods.
Introduction to ReasonRAG
The integration of external knowledge sources in retrieval-augmented generation (RAG) systems enhances the capabilities of LLMs by allowing them to incorporate accurate, up-to-date information. Traditional RAG systems often utilize static workflows that limit their adaptability in complex multi-step reasoning tasks. Agentic RAG systems mitigate these limitations through dynamic retrieval strategies and adaptive workflows, managing intricate search queries more adeptly.
ReasonRAG is introduced as a reinforcement learning framework utilizing process-level rewards. This approach aims to enhance training stability, reduce computational costs, and improve efficiency by employing a novel dataset called RAG-ProGuide. This dataset provides process-level supervision in query generation, evidence extraction, and answer generation, facilitating improved model capabilities via process-supervised reinforcement learning.
Framework and Implementation
ReasonRAG employs Monte Carlo Tree Search (MCTS) for efficient exploration of decision spaces and identification of high-reward intermediate steps in RAG processes.
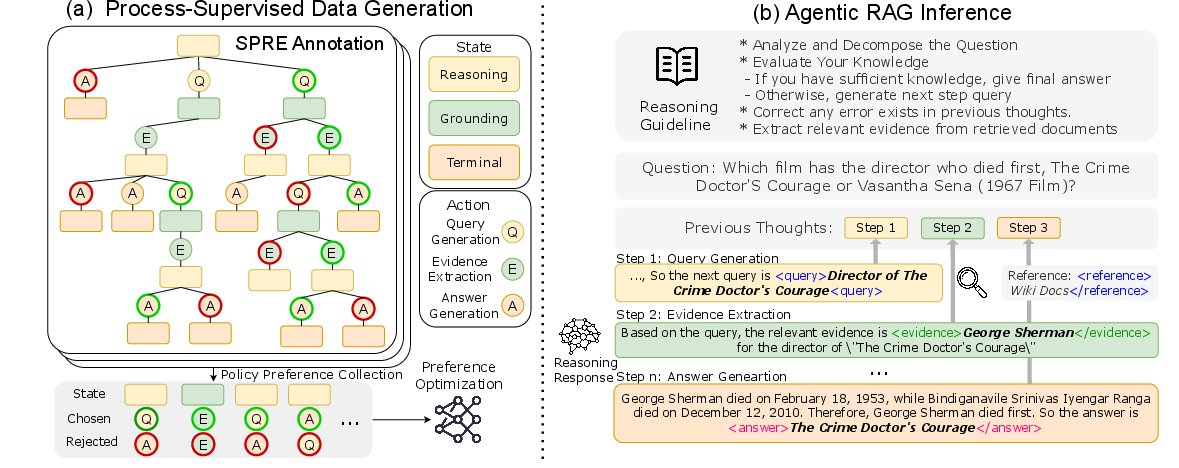
Figure 1: Framework of ReasonRAG, illustrating policy optimization and inference example.
Shortest Path Reward Estimation (SPRE)
A key innovation in ReasonRAG is SPRE, which offers fine-grained reward estimation at each reasoning step to optimize efficiency. It simulates possible outcomes of partial reasoning sequences and applies penalties for unnecessarily long trajectories, enabling the model to choose paths that lead directly to correct answers.
Data Generation and MCTS Exploration
RAG-ProGuide dataset construction utilizes MCTS to explore potential reasoning trajectories. This process collects high-quality supervision data for enhancing agentic RAG policy optimization. MCTS assists in efficiently navigating the vast decision space by selectively expanding promising reasoning paths.
ReasonRAG demonstrates substantial performance improvements over existing methods, such as Search-R1, across multiple benchmarks. It achieves these results using significantly fewer training instances, exemplifying the efficiency of process-supervised RL.
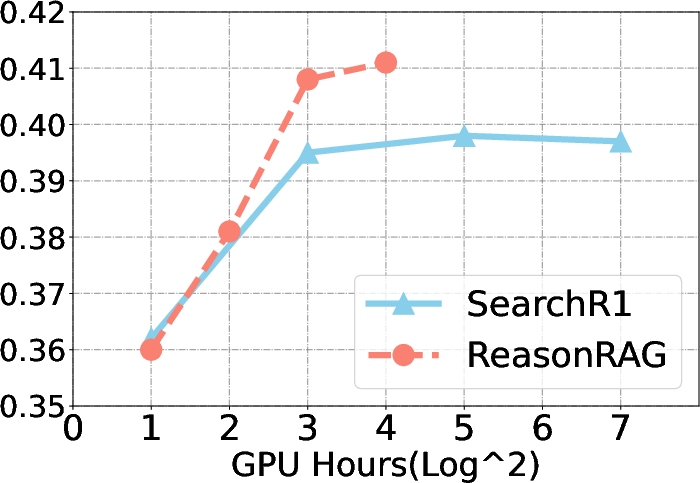
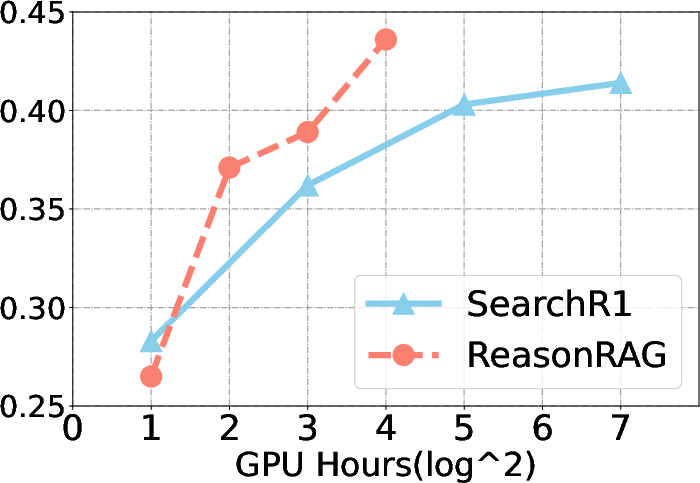
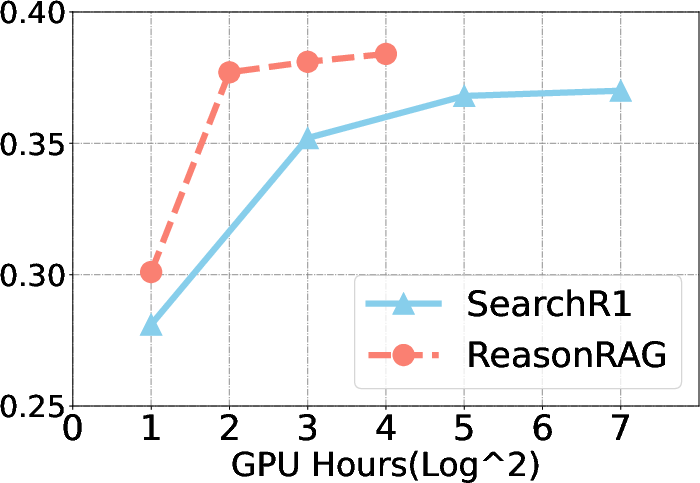
Figure 2: Training cost and convergence speed comparison for ReasonRAG and Search-R1.
Retrieval Iterations and Document Effectiveness
The model's performance improves with the number of retrieval iterations up to a saturation point, highlighting ReasonRAG's adaptive reasoning capabilities. Additionally, the number of top-k retrieved documents impacts performance, with more retrieved documents contributing to enhanced accuracy in multi-hop reasoning scenarios.
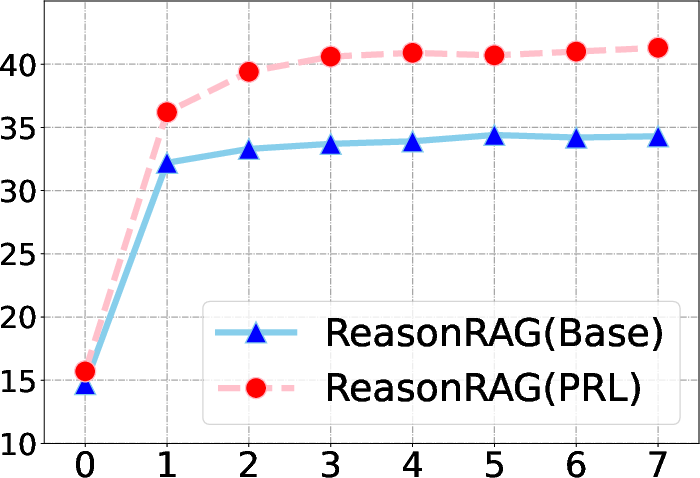
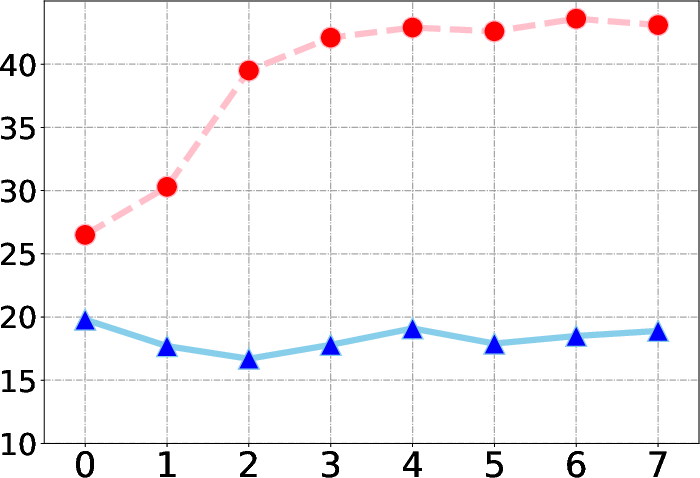
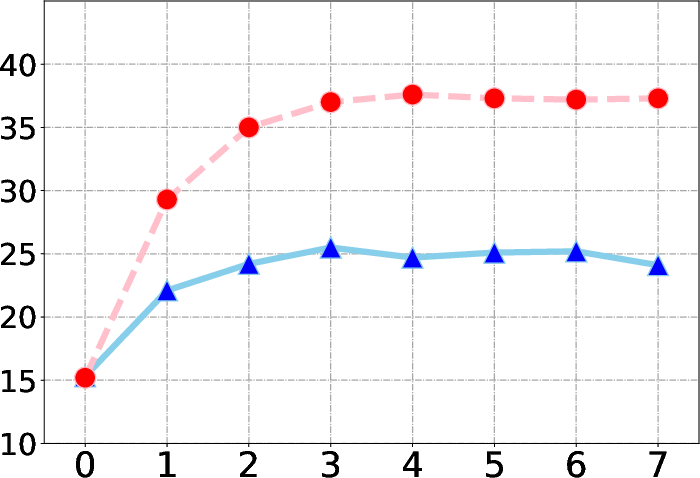
Figure 3: EM performance across varying retrieval iterations on benchmarks.
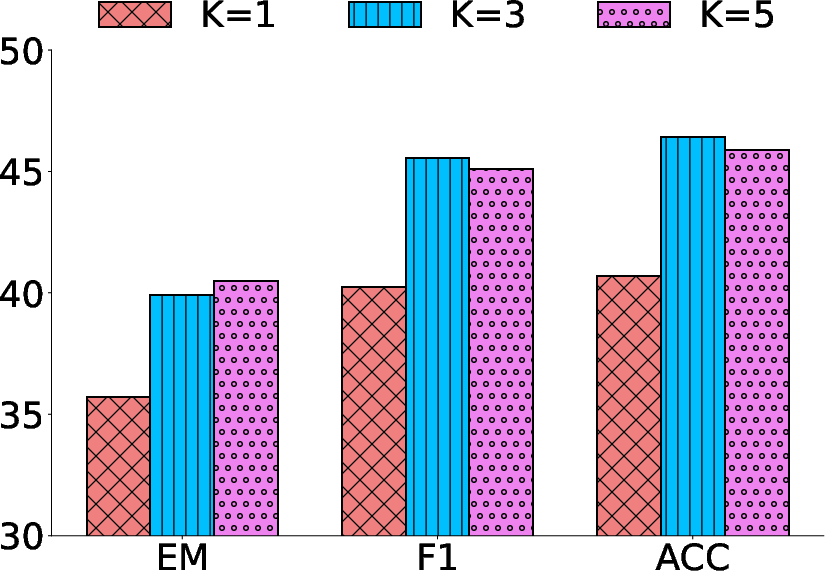
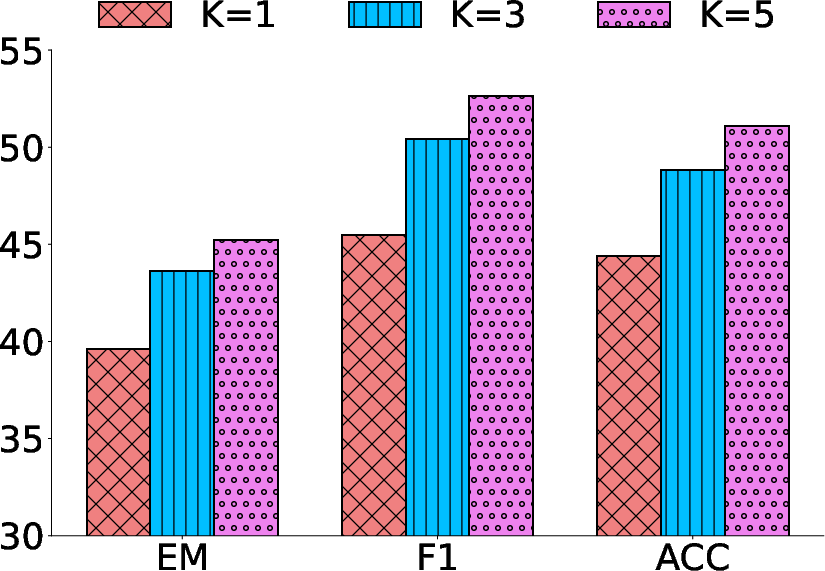
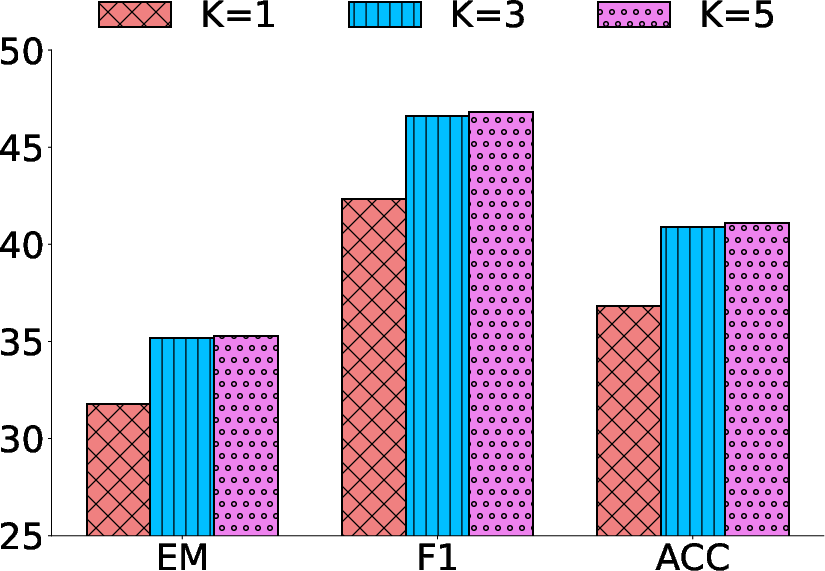
Figure 4: Effect of top-k retrieved documents on ReasonRAG's performance across datasets.
Conclusion
ReasonRAG signifies a meaningful advancement in agentic RAG systems by leveraging process-level rewards for efficient reinforcement learning. This innovative approach provides nuanced guidance for policy optimization, displaying robust improvements in both in-domain and out-of-domain generalization tasks. The reduction in computational requirements and data efficiency further underscores the potential of process-supervised RL in enhancing real-world applications of RAG systems. This research contributes towards evolving methodologies in AI that integrate external knowledge sources dynamically for advanced problem-solving. Overall, ReasonRAG's methodology and findings hold significant implications for future developments in adaptive RAG frameworks, underscoring the importance of optimizing not just the outcome, but the journey to it within AI systems.