- The paper demonstrates that coarse tokenization can obscure atomic reasoning units, resulting in up to an 80% performance loss in arithmetic tasks.
- It employs systematic evaluations on symbolic and arithmetic tasks, showing that fine-grained tokenization significantly enhances logical expressiveness.
- The study suggests considering tokenization as a core design choice, proposing adaptive strategies to optimize reasoning in both large and small models.
Tokenization Constraints in LLMs: A Study of Symbolic and Arithmetic Reasoning Limits
Introduction
The paper "Tokenization Constraints in LLMs: A Study of Symbolic and Arithmetic Reasoning Limits" (2505.14178) presents an in-depth examination of how tokenization impacts the symbolic and arithmetic reasoning capabilities of LLMs. The authors explore the limitations imposed by tokenization schemes, particularly focusing on subword-based methods like byte-pair encoding (BPE). They introduce the concept of Token Awareness to articulate how these tokenization strategies can disrupt the logical operations required for effective reasoning and generalization in LLMs.
Theoretical Foundations and Significance
Inductive reasoning and arithmetic computation form the crux of symbolic intelligence. However, the inherent architectural constraints of transformer models, which underpin LLMs, limit their ability to perform these tasks. By relying on a fixed number of parallel layers for computation, transformers are fundamentally ill-equipped for tasks requiring iterative updates, such as counting or basic arithmetic operations. The paper argues that the Chain-of-Thought (CoT) prompting paradigm, which externalizes intermediate reasoning steps, offers a partial solution but is still bounded by the tokenization process.
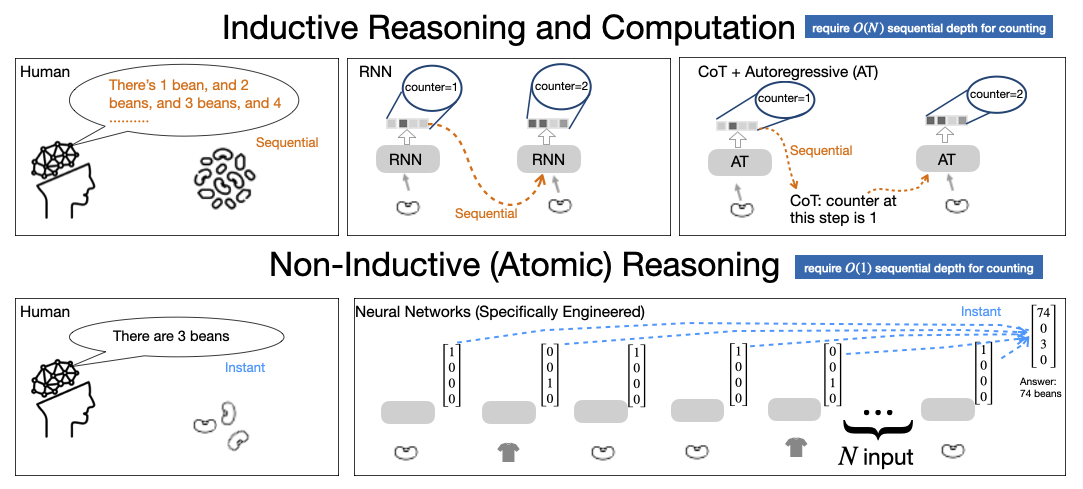
Figure 1: Illustration of inductive reasoning as performed by humans, RNNs, and LLMs with CoT, respectively.
Empirical and Experimental Analysis
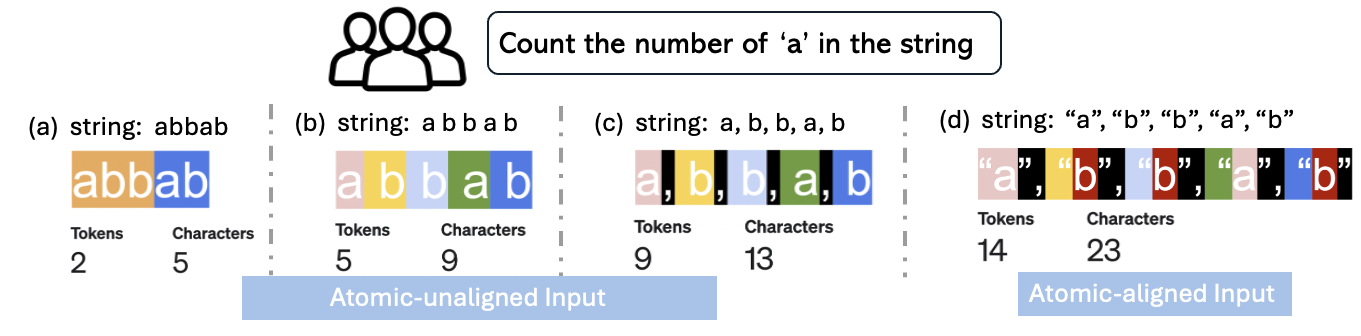
The authors conduct systematic evaluations using arithmetic and symbolic tasks to demonstrate the influence of tokenization on model performance. They highlight that the success of CoT prompting is critically reliant on the granularity of tokens. When tokenization results in coarse granularity, such as merging multiple characters into single tokens, the models exhibit significant performance degradation, sometimes resulting in up to 80% performance loss. They propose atomically-aligned formats as an enabling factor for the generalization of symbolic procedures, allowing smaller models like GPT-4o-mini to match or exceed the performance of larger models.
Results and Discussion
The paper reports several key findings:
- Tokenization Damage Types:
- Information Hiding: When tokenization obscures atomic reasoning units, it prevents the model from accessing necessary information for reasoning tasks.
- Limited Expressiveness: Coarse tokenization results in a reduced capacity to express the necessary intermediate computational states during CoT reasoning.
- Empirical Findings:
The study provides strong numerical evidence supporting these claims. For instance, in counting tasks, models using atomically-aligned token formats show a substantial increase in accuracy compared to those using conventional BPE tokenization methods.
Implications and Future Directions
The research underscores the pivotal role of tokenization in determining the symbolic and arithmetic capabilities of LLMs. It suggests that the choice of tokenization should be considered a core design decision rather than a mere preprocessing detail. By optimizing tokenization strategies, smaller models can be more effectively utilized, potentially leading to more resource-efficient applications of LLMs.
Looking forward, the authors speculate that further advancements could be made by developing adaptive tokenization schemes that dynamically adjust to the task at hand, maximizing both efficiency and accuracy in symbolic reasoning. Moreover, integrating insights from this research could enhance the interpretability and robustness of LLMs across a variety of complex reasoning tasks.
Conclusion
The paper effectively highlights the significant, yet often overlooked, impact of tokenization on the reasoning capabilities of LLMs. By bridging the gap between token-level representations and logical reasoning requirements, the authors pave the way for future improvements in the design and application of LLMs. Their work suggests that addressing tokenization constraints is essential for unleashing the full potential of LLMs in executing symbolic and arithmetic operations.