- The paper introduces AdvCLIP-LoRA, which integrates low-rank adaptation with adversarial training for robust few-shot fine-tuning of vision-language models.
- It employs a minimax optimization framework using PGD-based adversaries and low-rank matrix updates to balance clean and adversarial performance.
- Experimental results show state-of-the-art accuracy on multiple datasets, achieving robustness without significant computational overhead.
Few-Shot Adversarial Low-Rank Fine-Tuning of Vision-LLMs
Introduction
Vision-LLMs (VLMs) like CLIP have become pivotal in bridging visual and textual data modalities. These models leverage extensive contrastive pre-training to embed visual and textual information in a unified latent space. Optimizing VLMs for specific downstream tasks typically requires Parameter-Efficient Fine-Tuning (PEFT) methods, such as Low-Rank Adaptation (LoRA), to adapt massive models effectively without incurring excessive computational costs.
Despite the advantages of VLMs, they are vulnerable to adversarial attacks—minor input perturbations that significantly degrade performance. Existing adaptation techniques, including prompt tuning, often compromise clean accuracy for adversarial robustness, especially in few-shot scenarios. The proposed method, AdvCLIP-LoRA, seeks to enhance the adversarial robustness of CLIP models fine-tuned with LoRA in these constrained settings.
Methodology
AdvCLIP-LoRA implements a minimax optimization framework that adapts low-rank matrices while training against adversarially perturbed data. The core idea is to jointly optimize over the low-rank weight adaptations and the adversarial perturbations to achieve robust performance with minimal fine-tuning parameters:
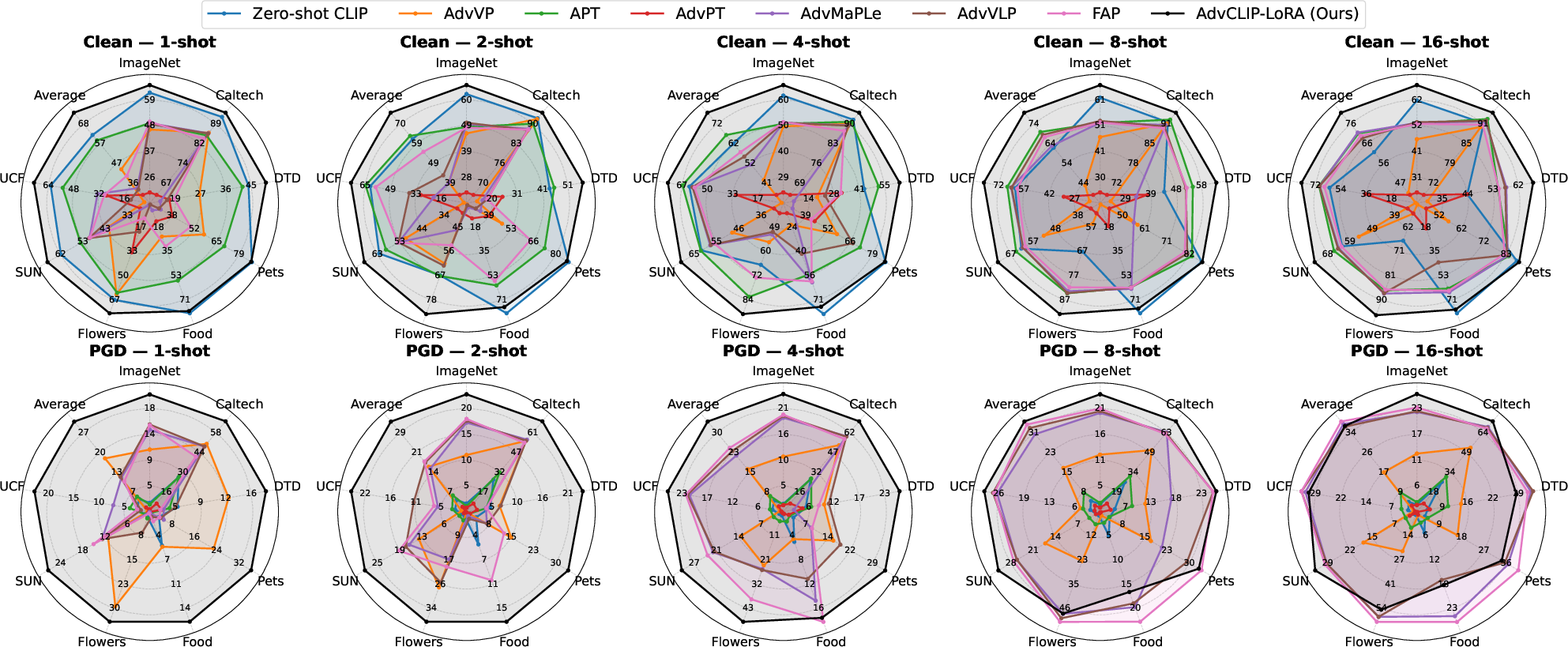
Figure 1: Few-shot performance across datasets under clean and adversarial evaluation. Spider plots show top-1 accuracy (\%) for Clean (top row) and PGD-100 (bottom row) on eight datasets at shot counts {1,2,4,8,16} with ViT-B/32. Each polygon denotes a method (larger area is better).
The algorithm proceeds by iteratively updating adversarial perturbations within a bounded set using Projected Gradient Descent (PGD). This adversarially augmented training data strengthen the model's resilience. Simultaneously, the LoRA matrices are adapted via gradient descent, keeping the primary model architecture frozen to maintain computational efficiency.
Convergence Analysis
The paper provides a theoretical foundation for convergence, demonstrating that under standard assumptions of smoothness and bounded gradients, the AdvCLIP-LoRA algorithm is guaranteed to reach a stationary point. This rigorous convergence analysis ensures that the method reliably optimizes model robustness without exceeding computational budgets typical in few-shot scenarios.
Experimental Results
AdvCLIP-LoRA was tested on various datasets, demonstrating superior robustness and clean accuracy compared to existing PEFT methods and prompt-based adaptations:
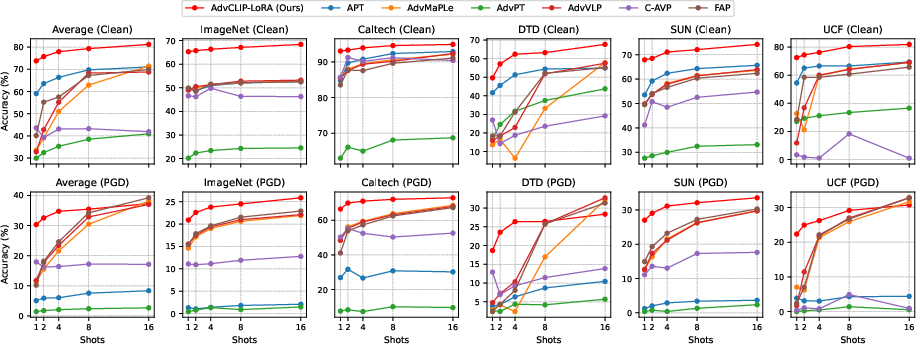
Figure 2: Effect of shot count on clean and adversarial performance. Clean and PGD accuracy versus number of shots {1,2,4,8,16} on representative datasets and the eight-dataset average.
AdvCLIP-LoRA consistently delivers state-of-the-art performance in adversarial settings while maintaining parity in clean accuracy. This is achieved across various evaluation scenarios, including base-to-new class generalization and cross-dataset evaluation, highlighting its capability to generalize well across different domains and task distributions.
Implementation Trade-offs
A critical aspect of AdvCLIP-LoRA is balancing clean and adversarial accuracy. The algorithm is sensitive to the choice of hyperparameters such as the PGD budget ϵ and the number of inner maximization steps τ. Empirical results suggest a τ value of around 10-15 strikes a favorable balance between robustness and computation time.
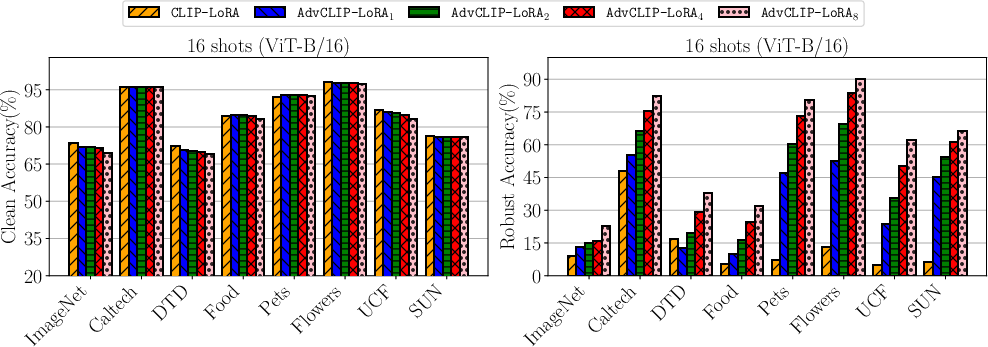
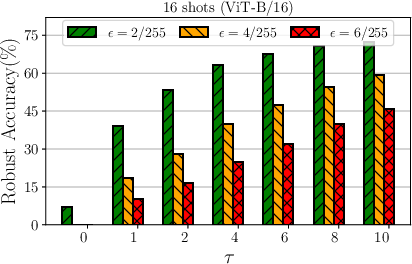
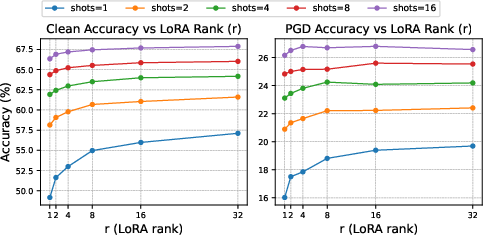
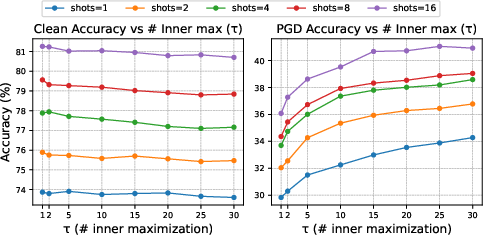
Figure 3: Top-left: comparison to the non-robust CLIP-LoRA. Ablations for AdvCLIP-LoRA. Top-right: effect of the PGD budget ϵ. Bottom-left: effect of LoRA rank r. Bottom-right: effect of inner maximization steps τ.
Conclusion
AdvCLIP-LoRA offers a robust adaptation strategy for VLMs in resource-limited environments by marrying adversarial training with parameter-efficient techniques. Its robust theoretical guarantees and empirical results provide a compelling case for its application in scenarios where both clean and adversarial accuracy are crucial. Future research might explore adaptive learning strategies that dynamically adjust τ and ϵ, potentially enhancing robustness further with even lower computational overhead.