- The paper demonstrates that incorporating user data significantly improves repost prediction, raising the F1 score from 0.24 to 0.70 in out-of-distribution scenarios.
- It employs both decision tree and neural network models to evaluate 305 features across message content and user activity, highlighting the strength of user-centric approaches.
- The study emphasizes the need for real-time adaptation to social media dynamics while acknowledging limitations in data scope and temporal variations.
Prediction of Reposting on X: An Analytical Overview
This discourse aims to dissect the focal points elucidated in the paper titled "Prediction of Reposting on X" (2505.15370). The paper presents an authoritative perspective on predicting user reposting behavior on social media, particularly X (formerly Twitter), with a strong emphasis on out-of-distribution generalization. The approach categorically distinguishes between the types of data utilized and evaluates both traditional and neural methodologies for enhanced predictive accuracy.
Introduction to Reposting Prediction
Reposting prediction on X, perceived as a binary classification task, gauges the potential of content diffusion via user reposts. Traditional distributional assumptions often involve random assignment of test and training data, which inherently limits applicability to real-world scenarios of unseen, novel topical events. The study explores this by infusing user-centric data alongside content-based features, postulating that user behavior, independent of content, plays a pivotal role in out-of-distribution forecasting.
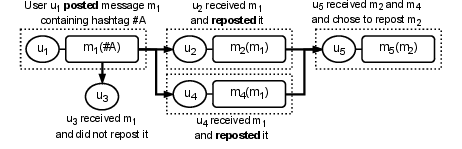
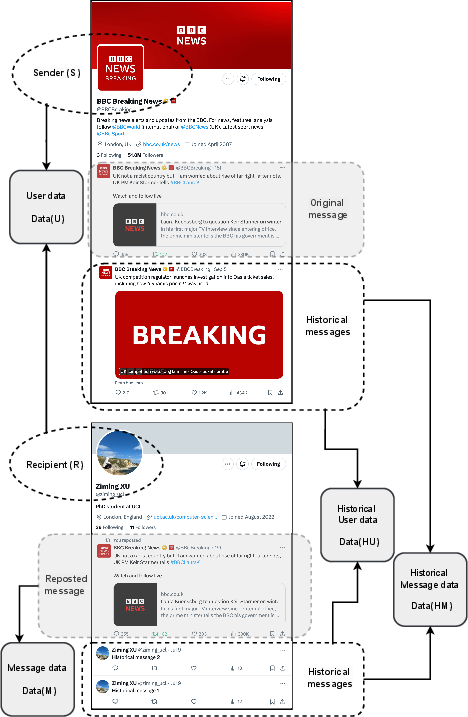
Figure 1: Reposting on X. (a) Flowchart of information spreading via reposting. (b) An example of reposting, where a recipient reposted a message from a sender. Four types of input data for reposting prediction: message data, historical message data, user data, and historical user data.
Methodology and Feature Significance
Data Sources and Feature Categorization
The paper identifies an array of 305 features falling under categories such as message content, historical message context, user profile data, and historical user interaction. Notably, user-related features have been vastly underrepresented in prior studies. Decision tree (DT) models like XGBoost and neural network (NN) models are scrutinized for their efficacy in utilizing these features.
Algorithmic Evaluations
Benchmarking against the TORS model, the inclusion of user data markedly outperforms content-centric models, especially in out-of-distribution scenarios:
- F1 Score Enhancement: Incorporating user profile and behavior data elevates the F1 score from 0.24 (content-only) to 0.70 in out-of-distribution settings.
- Temporal Data Influence: Algorithms trained on user features maintain robustness across temporal splits, thereby catering to the dynamic nature of X's trend-based dissemination.
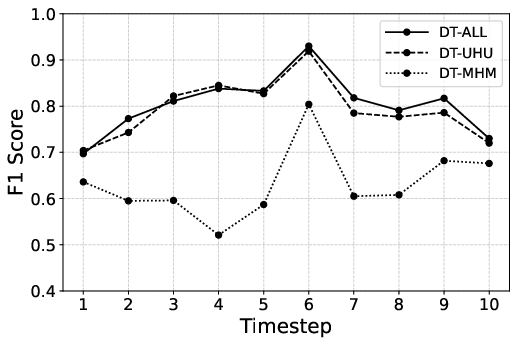
Figure 2: Reposting predictions by DT models for hashtag #Climatechange based on sliding time windows (the temporal split).
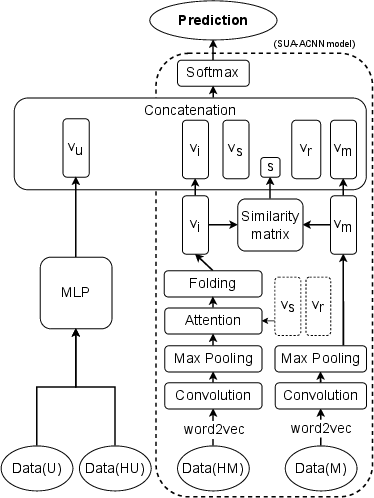
Figure 3: Neural network (NN) models based on different types of data. The baseline model SUA-ACNN uses only message-related data.
Decision Tree Findings
A comprehensive evaluation reveals decision tree models capitalizing on user-related data consistently outperform those relying solely on message data. As demonstrated in Table 3 of the paper, feature showcases such as follower interactions and user activity metrics underscore their significance.
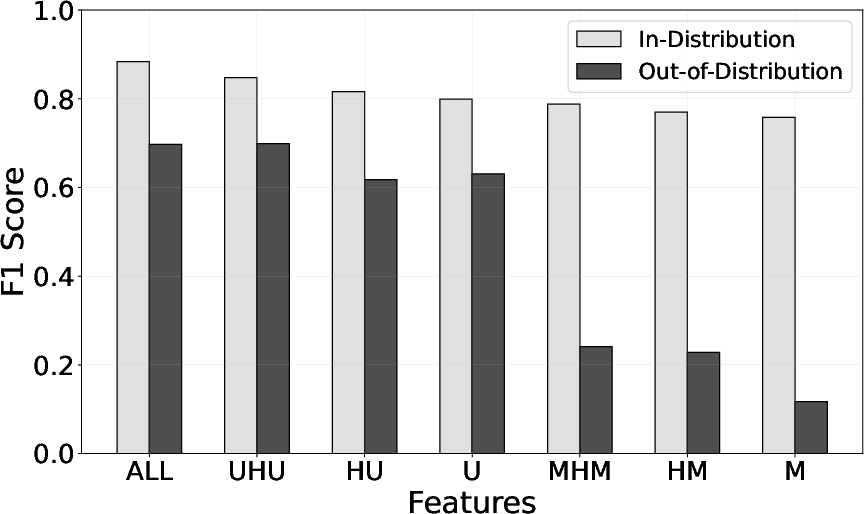
Figure 4: Comparison of the in-distribution and out-of-distribution predictions by DT models using different types of features.
Neural Network Dynamics
The NN models, especially those augmented with user data, aligned with these findings. BERT embeddings, although strong in content representation, lagged behind user-enriched networks in handling unseen hashtags. This highlights a crucial narrative: user engagement patterns are invaluable for generalized prediction beyond mere content analysis.
Limitations and Future Implications
While the investigation richly contributes to understanding repost behavior, it acknowledges limitations such as the finite scope of X's feature variations and the extrapolation of results beyond the studied dataset's temporal bounds. Future research could extend this paradigm to embed real-time adaptation mechanisms, further aligning predictive models with evolving social media landscapes.
Conclusion
The study provides an intricate analysis of reposting behavior prediction, advocating for a paradigm shift towards user-related information as the cornerstone of robust, adaptable predictive systems. It poises substantial implications for practitioners, particularly in developing models with stronger insights into user behavior beyond textual analysis, fostering improved strategic decision-making in information diffusion contexts.