Investigating Prosocial Behavior Theory in LLM Agents under Policy-Induced Inequities
Abstract: As LLMs increasingly operate as autonomous agents in social contexts, evaluating their capacity for prosocial behavior is both theoretically and practically critical. However, existing research has primarily relied on static, economically framed paradigms, lacking models that capture the dynamic evolution of prosociality and its sensitivity to structural inequities. To address these gaps, we introduce ProSim, a simulation framework for modeling the prosocial behavior in LLM agents across diverse social conditions. We conduct three progressive studies to assess prosocial alignment. First, we demonstrate that LLM agents can exhibit human-like prosocial behavior across a broad range of real-world scenarios and adapt to normative policy interventions. Second, we find that agents engage in fairness-based third-party punishment and respond systematically to variations in inequity magnitude and enforcement cost. Third, we show that policy-induced inequities suppress prosocial behavior, propagate norm erosion through social networks. These findings advance prosocial behavior theory by elucidating how institutional dynamics shape the emergence, decay, and diffusion of prosocial norms in agent-driven societies.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces a new way to study “prosocial behavior” (doing things that help other people or society) in AI agents powered by LLMs, like GPT-4. The authors built a simulation system called ProSim to see if these AI agents act kindly, enforce fairness, and how their behavior changes when rules or policies are unfair. They also compare AI behavior with real humans to check how similar they are.
Key Questions
The researchers set out to answer three simple questions:
- Can LLM agents act in prosocial ways across everyday situations (like helping, donating, and recycling)?
- Do LLM agents notice unfairness and try to enforce fair rules, even when it costs them something?
- What happens to prosocial behavior when policies are unfair, and does that unfairness spread through a social network?
How the Research Was Done
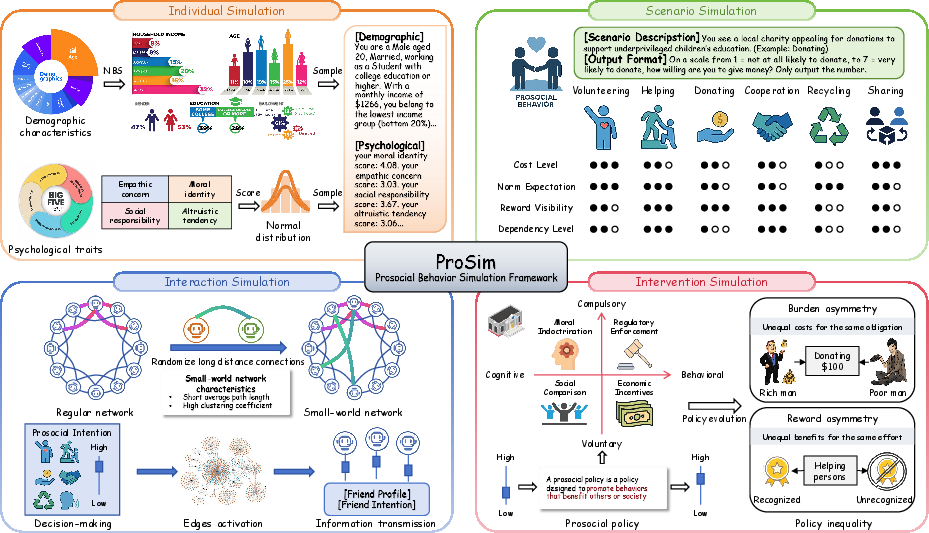
To make the simulations feel like real life, the authors built ProSim with four connected parts. Think of it like a virtual town of AI “people,” each with their own personality, doing everyday tasks, talking to their neighbors, and reacting to rules.
- Individual Simulation: Each AI agent is given a basic profile (like age and education) and psychological traits (such as empathy and moral identity). These traits are written into the agent’s instructions so it “thinks” like a person with that profile.
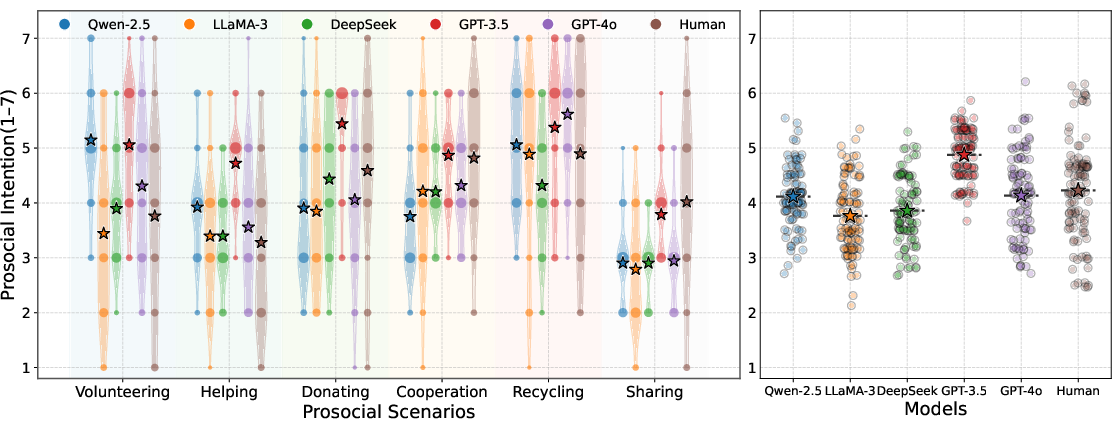
- Scenario Simulation: Agents face six common prosocial tasks: helping someone, donating, volunteering, cooperating, sharing information, and recycling. After each scenario, they rate how likely they are to do the prosocial action on a scale from 1 (very unlikely) to 7 (very likely).
- Interaction Simulation: Agents are placed in a “small-world network,” which is like a school or neighborhood where most people have close friends and also know a few people far away. Over time, agents see their neighbors’ choices and may change their own behavior, just like peer influence in real life.
- Intervention Simulation: The system adds policies (rules or nudges) to encourage prosocial actions. There are four types:
- Moral Indoctrination: reminding people of moral values.
- Regulatory Enforcement: clear rules or penalties (like fines).
- Social Comparison: showing what peers are doing (peer pressure).
- Economic Incentives: rewards (like money or points) for doing the right thing.
The system can also make policies unfair in two ways: - Reward Asymmetry: some agents get recognition or benefits while others don’t, even if they did the same work. - Burden Asymmetry: some agents face higher costs or effort for the same task (like being asked to do more for the same grade).
To check realism, the team ran parallel tests with 104 human participants who did similar tasks. They compared human and AI choices to see how closely AI agents matched people.
Two extra pieces worth explaining:
- Third-Party Punishment Game (Study 2): Imagine someone splits $30 unfairly between two players. A separate “judge” (the agent) can accept the split and get$10, or pay a fee to punish the unfair player. This tests if agents will pay a cost to enforce fairness, like a hall monitor who gives a detention even if it means doing extra paperwork.
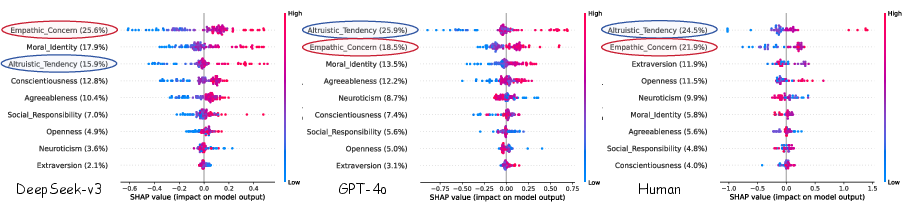
- SHAP Analysis (Study 1): This is a tool that estimates how much each trait (like empathy or altruism) influences an agent’s decision. Think of it as a fair “credit system” that tells you what traits mattered most for acting kindly.
Main Findings
Here’s what the researchers discovered across three studies:
- Study 1: Prosocial behavior and response to policies
- Many LLM agents showed a general tendency to act prosocially, often similar to humans.
- Some models (like GPT-4o and GPT-3.5) matched human patterns the best across different scenarios.
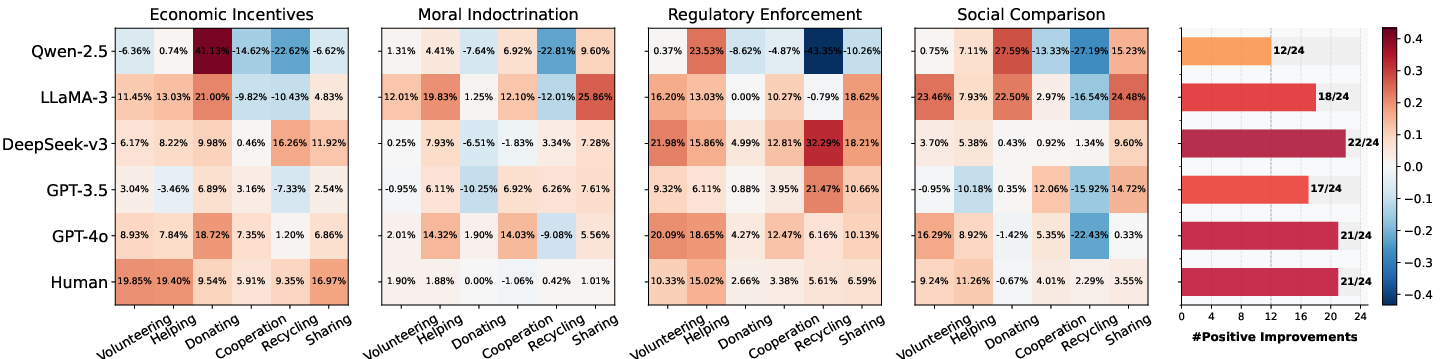
- When policies were added, agents usually increased their prosocial behavior. Clear rules (Regulatory Enforcement) were most effective. Economic rewards worked well for humans, but were mixed for AI agents—suggesting money-like rewards matter less to AI than clear rules or moral messages.
- Traits like altruism and empathy strongly influenced AI decisions, in ways close to human patterns.
- Study 2: Fairness and punishment
- LLM agents recognized unfair situations and often punished unfair behavior, even when it cost them something.
- The “GPT” models were most similar to humans: they punished more when the split was very unfair and punished less when it became fair or more costly—showing balanced judgment.
- Study 3: Unfair policies reduce kindness and spread across networks
- When policies were unfair (unequal rewards or unequal burdens), agents’ willingness to be prosocial dropped noticeably.
- Reward unfairness (who gets recognized) hurt prosocial behavior even more than unequal burdens (who does extra work).
- Unfairness spread through the social network: even agents not directly treated unfairly started to feel things were unfair after seeing their neighbors’ experiences. As this feeling grew, prosocial behavior fell across the whole network.
- There was a strong link between feeling unfairly treated and being less willing to help—suggesting fairness perceptions drive the decline.
Why It Matters
This research shows that:
- Advanced LLM agents can model human-like kindness and fairness, making them useful for studying social behavior.
- Clear, fair policies help keep prosocial norms strong. Unfair rules don’t just harm a few individuals—they can “infect” the whole community by spreading feelings of unfairness.
- When designing AI systems or policies that influence groups (schools, companies, online communities), fairness really matters. If AI agents are used to simulate or manage social systems, unfair designs can erode cooperation over time.
- ProSim provides a testing ground to try out different policies and see what keeps prosocial behavior strong. Future work can explore how to repair fairness, rebuild trust, and slow or stop the spread of norm erosion.
In short: LLM agents can act kindly and fairly, but unfair policies weaken these good habits and can spread that negativity across a network—just like in real life. Designing fair rules and clear expectations is key to keeping communities, human or AI, cooperative and healthy.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list outlines unresolved gaps, limitations, and open questions that future research could concretely address to strengthen the claims and utility of ProSim and its findings.
- Behavioral validity: Prosociality is primarily measured via self-reported Likert-scale “intention” rather than consequential choices with real stakes. Test incentivized tasks (e.g., real donations, time/effort costs, monetary consequences) and behavioral proxies to validate that reported intentions translate into behavior.
- Economic realism: In the third-party punishment paradigm, LLM agents do not incur actual costs or experience real payoffs. Introduce consequential environments (e.g., token budgets, constrained tool access, or API costs) to evaluate cost sensitivity and trade-offs under genuine incentives.
- Trait-encoding validity: Psychological traits are injected via natural language prompts, yet no manipulation checks show that agents internalize or consistently act on those traits. Conduct ablation studies and paraphrase stress tests to quantify how trait phrasing, placement, and specificity affect decisions.
- Interpretability pipeline transparency: SHAP analyses are reported, but the predictive model, features, training procedure, and target used to compute SHAP are unspecified. Provide full modeling details, compare multiple interpretable models (e.g., linear/logistic, tree-based), and assess robustness across modeling choices.
- Scenario coverage and construction: Six scenarios were selected based on expert judgment without a validated taxonomy or cross-cultural vetting. Develop a standardized, validated scenario bank with factorial manipulations (e.g., cost, anonymity, beneficiary proximity, reputational visibility) and test cross-cultural generalizability.
- Human benchmarking limitations: The human sample (n=104) is modest and may not be representative; the comparison relies on scenario-level averages and Pearson correlation across six categories. Expand samples, match demographics to agent profiles, perform trial-level analyses, and report reliability (e.g., internal consistency, measurement invariance).
- Cultural and linguistic generalization: Demographics are sampled from NBS distributions, but prompts/language and cultural norms are not systematically varied. Evaluate multilingual prompts, culturally localized scenarios, and model behavior across distinct cultural datasets to assess generalizability.
- RLHF confounds: Prosocial tendencies may reflect instruction tuning and RLHF bias rather than genuine social reasoning. Compare base (pre-alignment) vs. aligned models, control for safety/alignment priors, and quantify normative “helpfulness” baselines independent of scenario content.
- Stochasticity and variability: All runs use temperature=0, potentially suppressing human-like variability and exploration. Systematically vary sampling temperature, decoding strategies, and seeds to measure outcome variance and stability.
- Model coverage and comparability: Inequity effects are tested mainly on GPT-4o and DeepSeek-v3; results may not generalize across models or sizes. Include broader families (e.g., Claude, Mistral, Gemini), multiple parameter scales, and fine-tuning regimes to assess consistency.
- Network topology sensitivity: The small-world network (k=6, p=0.2) and activation rate (10% of edges per round) are fixed. Conduct parameter sweeps and compare topologies (scale-free, modular, homophily-based, dynamic/rewiring) to test whether contagion and erosion effects depend on network structure.
- Statefulness and learning: Agent “memory” appears prompt-based, with prior actions fed into the LLM; there is no explicit long-term learning or internal state updating. Evaluate explicit memory modules, episodic summaries, or reinforcement-style updates to test genuine normative learning over time.
- Contagion mechanism assumptions: An agent is marked “indirectly exposed” if any active neighbor previously experienced unfair treatment—an aggressive exposure definition. Compare alternative contagion rules (e.g., thresholds, weighted influence, tie strength), and identify minimal conditions for norm erosion.
- Inequity taxonomy breadth: Only reward asymmetry and burden asymmetry are modeled. Incorporate procedural justice, distributive vs. interactional fairness, group-based inequity (e.g., identity, status), exclusion/marginalization, and intersectionality to reflect real institutional inequities.
- Intervention design space: Interventions are static framings embedded in prompts (moral indoctrination, regulatory enforcement, social comparison, economic incentives). Test dynamic, multi-stage, and adaptive interventions (e.g., fairness restoration, audit/feedback loops, targeted subsidies), and quantify their effectiveness in halting or reversing norm erosion.
- Economic incentive comprehension: LLMs showed muted sensitivity to monetary incentives relative to humans. Diagnose whether models grasp economic contingencies by using structured payoff tables, external calculators/tools, or multi-turn reasoning steps and verify internal consistency.
- Emotional alignment measurement: The paper mentions analyzing emotional expressions but does not present methods or results. Operationalize emotion detection (e.g., emotion lexicons, human coding, model-based classifiers), compare affective responses to human data, and link affect to punishment/cooperation decisions.
- Calibration and response-style bias: LLMs may exhibit systematic rating biases (e.g., favoring higher scales) on Likert responses. Calibrate with anchoring vignettes, constrained formats (forced choice, pairwise comparisons), and probabilistic outputs to reduce scale artifacts.
- Time horizon and equilibrium: Network simulations run for 30 iterations; long-run equilibria and potential recovery dynamics remain unknown. Extend horizons, analyze steady states, phase transitions, and intervention timing (early vs. late) to understand resilience and tipping points.
- Robustness to prompt design: Policy interventions and inequity cues are delivered via text framings; outcomes may be sensitive to wording or context length. Perform prompt engineering audits, measure sensitivity to rephrasings/minimal changes, and pre-register prompt templates to improve reproducibility.
- Grounding and external validity: All interactions are text-only. Incorporate grounded environments (e.g., task APIs, sensor data, simulated workplaces) to test whether prosocial norms survive when actions have concrete external consequences or constraints.
- Measurement triangulation for unfairness: Perceived unfairness is self-reported by agents. Add complementary measures (e.g., sentiment/moral-emotion analysis, rule-violation detection, justification quality) and test convergent validity across indicators.
- Reproducibility details: The paper references code availability but does not specify seeds, full prompt sets, or human data sharing. Release complete experimental artifacts (prompts, traits, network configs, seeds, analysis scripts, anonymized human datasets) to enable independent replication.
- Causal mechanisms across models: Inter-model differences (e.g., GPT-4o vs. DeepSeek-v3) are described but not explained. Investigate how training data, alignment methods, and architectural choices causally relate to prosocial and fairness behaviors through controlled fine-tuning/ablation studies.
- Safety and ethics considerations: The societal deployment implications of policy-induced inequity and LLM-driven norm dynamics are not discussed. Articulate ethical guardrails, misuse risks (e.g., manipulating norms via prompts), and governance recommendations for agent societies.
Glossary
- Agent-Based Social Simulation: Computational modeling of social processes using autonomous agents to study emergent behavior. "LLM-Driven Agent-Based Social Simulation."
- Altruistic orientation: A dispositional tendency to prioritize others’ welfare over self-interest. "altruistic orientation~\cite{amitha2024altruistic}"
- Altruistic punishment: Incurring a personal cost to punish unfair behavior to uphold social norms. "a well-established framework for studying fairness judgment and altruistic punishment."
- Altruistic Tendency: A stable inclination to act for others’ benefit even at personal cost. "Altruistic Tendency emerges as the most dominant factor"
- Big Five personality: A five-factor model of personality comprising openness, conscientiousness, extraversion, agreeableness, and neuroticism. "the Big Five personality~\cite{gosling2003very}"
- Burden Asymmetry: Unequal costs or efforts imposed on different agents for performing the same task. "Burden Asymmetry: agents face unequal costs or effort for performing the same prosocial task."
- Dictator game: An economic game where one player unilaterally allocates resources between self and another. "dictator game and public goods game"
- Economic Incentives: Extrinsic rewards or penalties designed to shape agent behavior. "Economic Incentives (,): introduces rewards or penalties contingent on agent choices."
- Empathic Concern: Emotional responsiveness and sympathy toward others’ suffering. "strong contributions from Empathic Concern."
- Human Benchmarking: Comparing model behavior against human participants under matched conditions. "Human Benchmarking."
- Inequity magnitude: The degree of unfairness in an allocation or treatment. "variations in inequity magnitude and enforcement cost."
- Likert scale: An ordered rating scale used to measure attitudes or intentions. "7-point Likert scale"
- Moral Identity: The degree to which moral values are central to one’s self-concept. "places greater weight on Moral Identity."
- Moral Indoctrination: An intervention appealing to internalized moral values to motivate prosociality. "Moral Indoctrination (,): appeals to internalized moral values to motivate prosociality."
- Norm erosion: The decay of adherence to social norms over time or due to adverse conditions. "propagate norm erosion through social networks."
- Norm formation: The emergence of shared behavioral expectations within a group or society. "norm formation~\cite{li2024culturepark}"
- Normative policy interventions: Policies designed to promote compliance with prosocial norms. "adapt to normative policy interventions."
- Pearson correlations: A statistical measure quantifying linear association between two variables. "we computed Pearson correlations"
- Perceived unfairness: Subjective judgment that treatment or outcomes are unequal or unjust. "perceived unfairness can propagate socially"
- Prosocial Behavior Theory: Framework studying voluntary actions intended to benefit others or promote collective welfare. "Prosocial Behavior Theory"
- Prosocial policies: Institutional measures intended to promote cooperative and altruistic behavior. "Prosocial Policies."
- Public goods game: An economic game involving private contributions to a shared resource with collective benefits. "dictator game and public goods game"
- Regulatory Enforcement: Mandated rules or sanctions to compel compliance. "Regulatory Enforcement (,): mandates behavior through institutional rules or penalties."
- Reward Asymmetry: Unequal recognition or benefits despite equal contributions. "Reward Asymmetry: agents receive unequal recognition or benefits despite contributing equally."
- SHAP (SHapley Additive exPlanations): A method that attributes model predictions to features using Shapley values. "we compute SHAP (SHapley Additive exPlanations) values"
- Small-world network: A network with high local clustering and short average path lengths, resembling many social systems. "a small-world network "
- Social Comparison: An intervention exposing agents to peer decisions to induce normative pressure. "Social Comparison (,): exposes agents to peer decisions to activate normative pressure."
- Social contagion: The spread of behaviors or perceptions through social connections. "amplified through social contagion"
- Social responsibility: A sense of obligation to contribute to societal welfare. "social responsibility"
- Theory of mind: The capacity to attribute mental states to others and predict behavior. "including theory of mind~\cite{strachan2024testing}"
- Third-party punishment paradigm: An experimental setup where a neutral observer can punish unfair allocations at a cost. "third-party punishment paradigm~\cite{fehr2004third}"
- Value alignment: Ensuring model behavior adheres to human values and ethical norms. "value alignment~\cite{liu2022aligning}"
- WattsâStrogatz algorithm: A procedure to generate small-world networks by rewiring edges in a regular lattice. "WattsâStrogatz algorithm~\cite{kleinberg2000small}"
Practical Applications
Immediate Applications
Below are practical applications that can be deployed now, leveraging the paper’s ProSim framework, empirical findings, and workflows.
- Industry (Software/Platform Governance) — Policy A/B Testing Sandbox
- Use case: Evaluate moderation and community rules (e.g., “regulatory enforcement” vs “social comparison” vs “economic incentives”) before rollout to assess their impact on cooperation, information sharing, and norm compliance.
- Tools/products/workflows: ProSim-based “Policy Sandbox” with small-world network simulation; intervention switchboard; SHAP-driven trait sensitivity reports; pre–post prosociality dashboards.
- Assumptions/dependencies: LLM agents approximate user responses under given prompts; monetary incentives are less salient for some LLMs than for humans; network topology must reflect platform communities.
- Industry (HR/Organizational Culture) — Equitable Recognition Design
- Use case: Audit volunteering/helping programs to avoid “reward asymmetry” (unequal recognition) and “burden asymmetry” (unequal effort/cost), which the paper shows erode prosociality and spread via social contagion.
- Tools/products/workflows: “Inequity Risk Scanner” atop ProSim; scenario templates for volunteering/helping; fairness stress tests; policy iteration (recognition policy variants).
- Assumptions/dependencies: Trait distributions must be calibrated to the firm’s workforce; outcomes depend on how recognition is framed in prompts.
- Industry (Nonprofits/Fundraising) — Prosocial Messaging Optimization
- Use case: Test donation appeals and incentive framings to increase prosocial intent while avoiding inequity perceptions (e.g., tiered recognition).
- Tools/products/workflows: ProSim scenario for “Donating”; message variants comparing moral appeals vs economic incentives; measure changes in intention scores.
- Assumptions/dependencies: Donation behavior in LLM simulations aligns with real donor segments only if prompts and demographics mirror target populations.
- Academia (Computational Social Science/Psychology) — Trait-to-Behavior Mapping Replication
- Use case: Use ProSim to replicate and extend SHAP-based analyses of how empathy, altruistic tendency, moral identity, and Big Five traits shape prosocial behavior across scenarios.
- Tools/products/workflows: Trait initialization pipelines; SHAP analytics; human benchmarking replication kits.
- Assumptions/dependencies: Validity depends on reliable trait priors and matched human samples.
- Policy (Municipal Sustainability/Public Goods) — Pre-mortem for Recycling and Cooperation Programs
- Use case: Prototype and test recycling/cooperation policies (e.g., fines, social comparison, public recognition) to predict prosocial uptake and identify inequity-induced norm erosion.
- Tools/products/workflows: City “Policy Prototyping Lab” using ProSim’s six scenarios; reward/burden asymmetry toggles; network contagion diagnostics.
- Assumptions/dependencies: Local demographic calibration; municipal constraints (legal, budgetary) shape deployable interventions.
- Policy (Regulatory Design/Compliance) — Enforcement Framing Evaluations
- Use case: Compare “regulatory enforcement” vs “voluntary cognitive appeals” to maximize compliance without triggering perceptions of unfairness.
- Tools/products/workflows: Intervention library; scenario-specific compliance scorecards; fairness perception tracking.
- Assumptions/dependencies: Enforcement costs and penalties must be grounded in realistic institutional contexts.
- Industry and Policy (Community Management) — Norm-Guardrails for Recognition Systems
- Use case: Design badge/award systems that distribute recognition equitably to prevent network-wide prosocial decline.
- Tools/products/workflows: Recognition allocation simulator; contagion heatmaps showing norm erosion; “equity-by-design” checklists.
- Assumptions/dependencies: Accurate modeling of visibility and social comparison effects in the target community.
- AI Safety/LLM Product Development — Prosocial Alignment Audits
- Use case: Integrate ProSim into model evaluation to quantify prosociality, fairness sensitivity, and third-party punishment behavior under differing costs and inequity magnitudes.
- Tools/products/workflows: Prosocial Alignment Index; cost-sensitivity curves; fairness-threshold profiling across model versions.
- Assumptions/dependencies: Prompt stability and determinism (temperature 0) may differ from real-world usage; cross-model behavior varies.
- Education (Classroom/Teamwork) — Fair Group Work Policy Tuning
- Use case: Test grading schemes, peer-recognition, and workload distribution to sustain cooperation and information sharing while minimizing perceived unfairness.
- Tools/products/workflows: Class-level ProSim scenarios; burden asymmetry toggles; norm-contagion visualization for group projects.
- Assumptions/dependencies: Student trait priors and group network structures must be approximated; teacher adoption of interventions.
- Healthcare (Clinical Teams/Research Collaborations) — Credit Allocation Audits
- Use case: Assess credit/reward distribution and workload policies for care teams to prevent inequity-driven drops in cooperation and information sharing.
- Tools/products/workflows: Scenario templates for team cooperation and info sharing; policy framings (e.g., explicit enforcement); pre–post intention tracking.
- Assumptions/dependencies: Domain-specific ethics and incentives must be represented in prompts; privacy constraints.
Long-Term Applications
The following applications require further research, scaling, validation, or integration before broad deployment.
- Public Sector — Community Digital Twins for Policy Design
- Use case: Build city-scale digital twins to simulate long-term impacts of reward/burden asymmetries on norms (e.g., recycling, public health behaviors, civic volunteering) and stress-test interventions before rollout.
- Tools/products/workflows: Data-integrated ProSim (census, mobility, platform data); adaptive network models; real-time fairness perception tracking.
- Assumptions/dependencies: High-quality local data; robust external validation against field outcomes; governance and privacy frameworks.
- Software/Platforms — Autonomous Moderation Agents with Fairness-Aware Enforcement
- Use case: Deploy agents that calibrate intervention strength (warnings, penalties) to fairness thresholds and cost-sensitivity, minimizing over-enforcement while preserving norms.
- Tools/products/workflows: Enforcement policy optimizer; fairness-threshold estimators; human-in-the-loop review pipelines.
- Assumptions/dependencies: Reliable cost sensitivity and ethical guardrails; continuous human oversight.
- HR/Enterprise Systems — Fairness-Aware Incentive Engines
- Use case: Optimize bonus/recognition schemes that account for perceived unfairness signals to maintain cooperation and reduce norm erosion across departments.
- Tools/products/workflows: “Norm-Preservation Optimizer” using ProSim; long-horizon contagion simulations; ESG-linked prosocial KPIs.
- Assumptions/dependencies: Access to internal behavioral data; cross-cultural tuning; change management.
- Healthcare/Public Health — Campaign Design Against Norm Erosion
- Use case: Model contagion of perceived unfairness in vaccination or preventive care campaigns; tailor interventions (social comparison, regulatory enforcement, moral appeals) to sustain prosocial health behaviors.
- Tools/products/workflows: Health-behavior digital twins; dynamic intervention scheduling; equity impact forecasting.
- Assumptions/dependencies: Integration with epidemiological models; equitable access considerations; ethics review.
- Education — Cross-Cultural Prosocial Alignment in Schools
- Use case: Scale ProSim to diverse cultural contexts to tune cooperative learning policies and peer-recognition systems that generalize across schools and regions.
- Tools/products/workflows: Culture-calibrated trait priors; localized intervention framings; longitudinal norm tracking.
- Assumptions/dependencies: Cultural data availability; sustained partnerships for field validation.
- Energy — Fair Demand Response and Community Energy Sharing
- Use case: Design incentive schemes that avoid burden asymmetry (e.g., uneven participation costs) in demand response and microgrid sharing to maintain collective cooperation.
- Tools/products/workflows: Prosocial energy behavior scenarios; incentive fairness diagnostics; contagion-aware rollout plans.
- Assumptions/dependencies: Integration with grid operations; accurate modeling of household heterogeneity.
- Finance — Prosocial Investing and Fee Transparency
- Use case: Simulate how recognition, transparency, and fee structures affect prosocial financial products (ESG funds, charitable micro-donations) and mitigate inequity perceptions.
- Tools/products/workflows: Investor behavior simulation; framing optimization; fairness-sensitive product design.
- Assumptions/dependencies: Regulatory compliance; mapping LLM outputs to investor segments.
- Robotics — Prosocial Social Robots for Care and Education
- Use case: Train robots with fairness-aware prosocial policies (helping, sharing, recognition sensitivity) to interact cooperatively in homes, classrooms, and eldercare.
- Tools/products/workflows: Multi-agent training via ProSim; real-world cost models; cross-modal perception of inequity cues.
- Assumptions/dependencies: Safe deployment; robust grounding from text simulations to embodied behavior.
- AI Training — RL from Prosocial Simulations
- Use case: Use ProSim outcomes to shape reward functions and curricula for LLMs/multi-agent systems that internalize fairness norms and avoid inequity-induced degradation in cooperation.
- Tools/products/workflows: Curriculum learning pipelines; reward shaping based on fairness thresholds; evaluation suites for norm stability.
- Assumptions/dependencies: Transfer from simulated intent scores to real task performance; avoidance of reward hacking.
- Standards/Measurement — Prosocial Alignment Index and Fairness Metrics
- Use case: Establish standardized metrics for prosocial alignment, fairness sensitivity, and contagion risk in AI agents and policies.
- Tools/products/workflows: Benchmark datasets; cross-model scorecards; governance reporting.
- Assumptions/dependencies: Community consensus on metric definitions; ongoing human benchmarking.
Cross-cutting assumptions and dependencies
- LLM-to-human validity: LLM agents approximate human behavior under specific prompts and settings; generalization requires human benchmarking and field validation.
- Model variability: Different LLMs exhibit different prosocial magnitudes and cost sensitivity; applications should be model-agnostic or version-aware.
- Network realism: Small-world networks capture some social structures; domain-specific networks may be necessary for fidelity.
- Cultural context: Demographic and trait priors should be localized; fairness perceptions vary across cultures and sectors.
- Incentive salience: Economic incentives affected LLMs differently than humans in the studies; monetary framing must be carefully tested.
- Governance and ethics: Any deployment that affects people requires transparency, consent, privacy safeguards, and human oversight.
Collections
Sign up for free to add this paper to one or more collections.