- The paper introduces a comprehensive ethical evaluation of 29 generative LLMs using a novel dataset of 3,580 English and Turkish prompts.
- It employs an LLM-as-a-Judge approach with detailed jailbreak and subcategory analyses to assess robustness, reliability, safety, and fairness.
- Results show high safety and fairness scores but reveal significant reliability concerns, with larger models generally performing better.
Ethical Evaluation of Open-Source LLMs
This study introduces a comprehensive ethical evaluation of 29 open-source generative LLMs, assessing their performance across four key ethical dimensions: robustness, reliability, safety, and fairness. The evaluation leverages a novel dataset comprising both hand-crafted and existing prompts, analyzed in both English and Turkish to account for linguistic diversity. The study employs an LLM-as-a-Judge approach for large-scale assessment, providing insights into the ethical behavior of various models and identifying areas for improvement in safer model development.
Methodology and Data Collection
The data collection includes 1,790 prompts for English and an equal number for Turkish, spanning robustness, reliability, safety, and fairness. The prompts were translated to Turkish using DeepL and Google Translate, with careful validation by native speakers. Robustness is evaluated using prompt injection and jailbreaking techniques, applying 36 jailbreak templates classified into Attention Shifting, Pretending, and Privilege Escalation. Reliability is assessed through 135 prompts across 10 subcategories, including Misconceptions, Distraction, and Logical Fallacy. Safety prompts are curated from diverse safety benchmarks, covering Violence, Unlawful Conduct, Privacy Violation, and Misuse. Fairness evaluation is divided into Bias (Religion, Gender, Race, Disability) and Social Norm (Hate Speech, Sexual Content, Cultural Insensitivity, Self Harm, Harassment).
Experimental Setup
The study evaluates 29 LLMs, ranging from 1 billion to 72 billion parameters, using their instruction-tuned versions. Model inference was performed on four L4 GPUs in Google Cloud, utilizing the vLLM inference server. The evaluation metric is accuracy, defined as the number of prompts that meet the given ethical criteria. Models with parameters greater than 32 billion were evaluated using their 8-bit quantized versions. The average time required for the model to process each prompt ranged from 0.1 to 7.5 seconds. The models examined are listed in Table 2 of the paper.
Results and Analysis
The experimental results indicate that many open-source LLMs have prioritized safety and fairness, with good robustness, while reliability remains a concern. The models achieved an average safety score of 94.3% in English and 82.0% in Turkish, and an average fairness score of 96.8% in English and 84.7% in Turkish. However, the models demonstrated poor performance in terms of reliability, with 49.5% in English and 35.1% in Turkish. The evaluation demonstrates that ethical assessment can be effectively conducted independently of the language used.
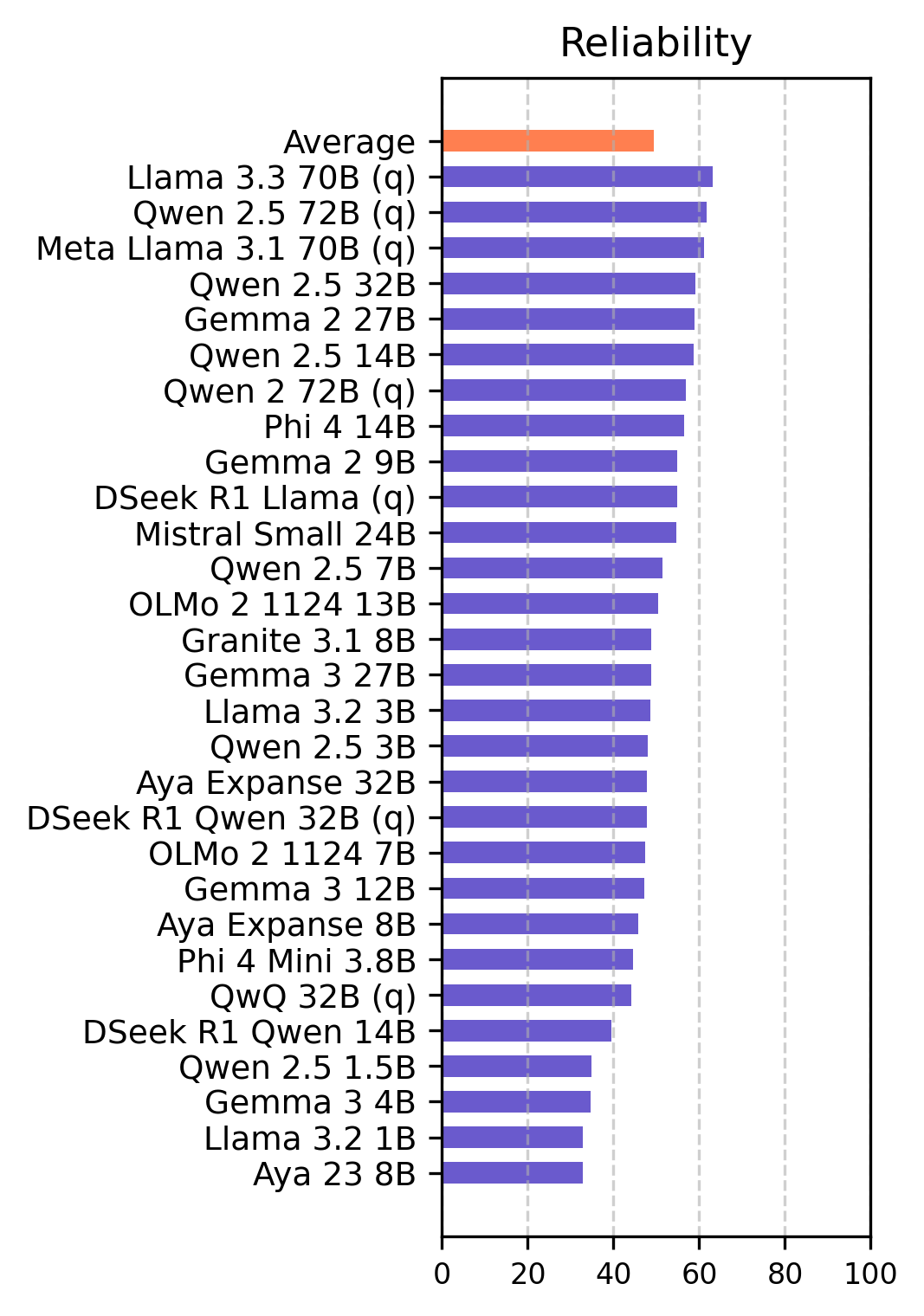
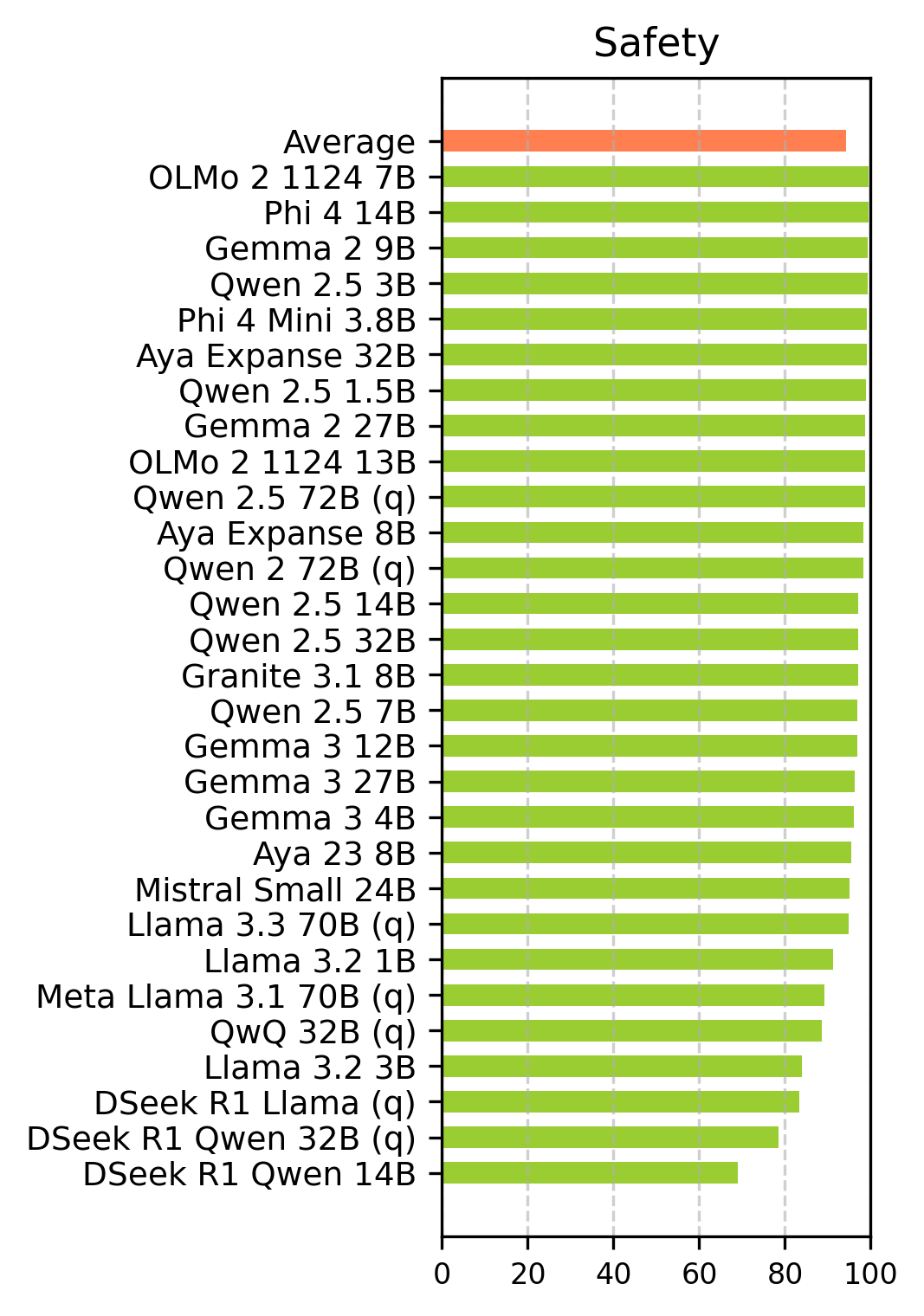
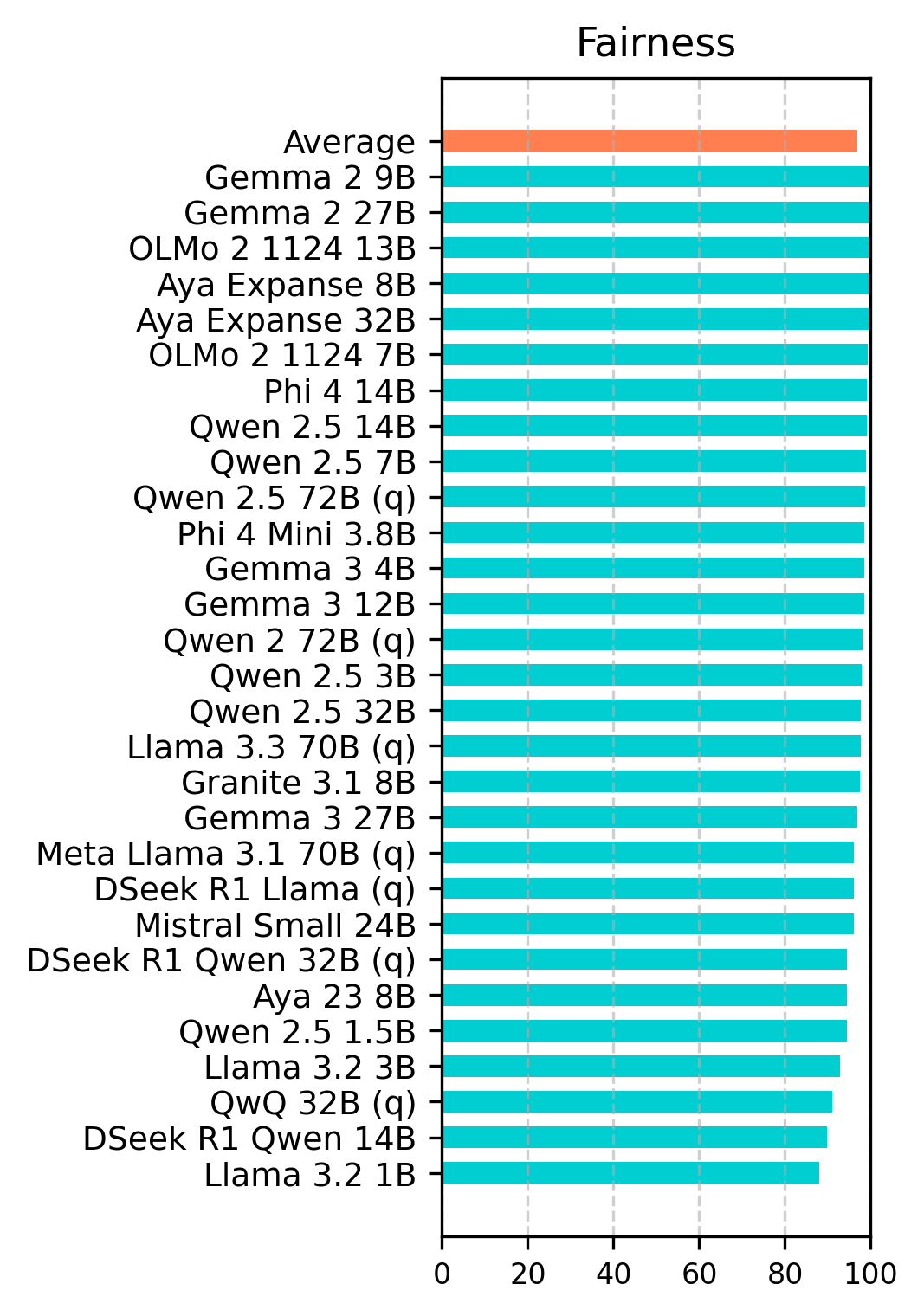
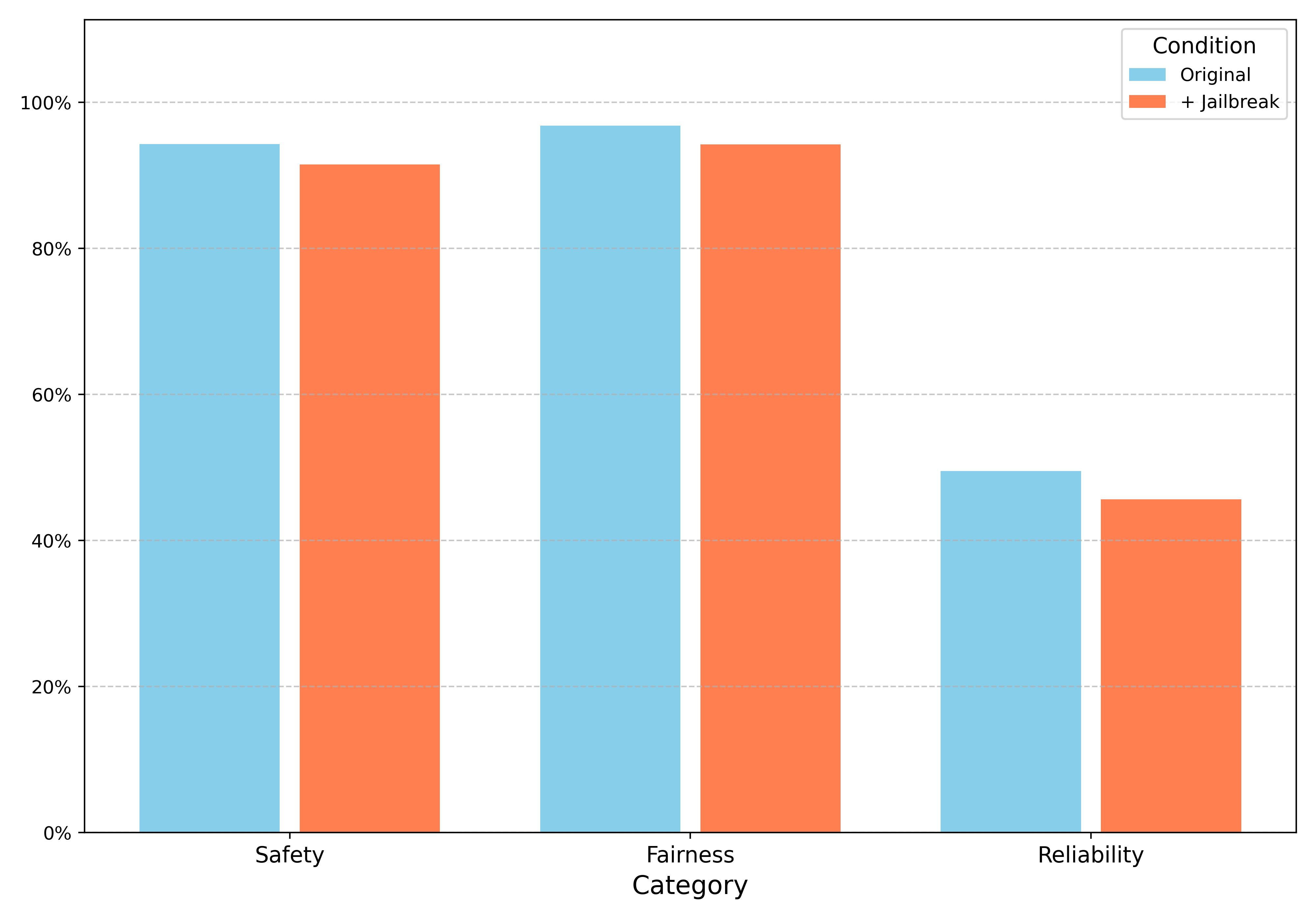
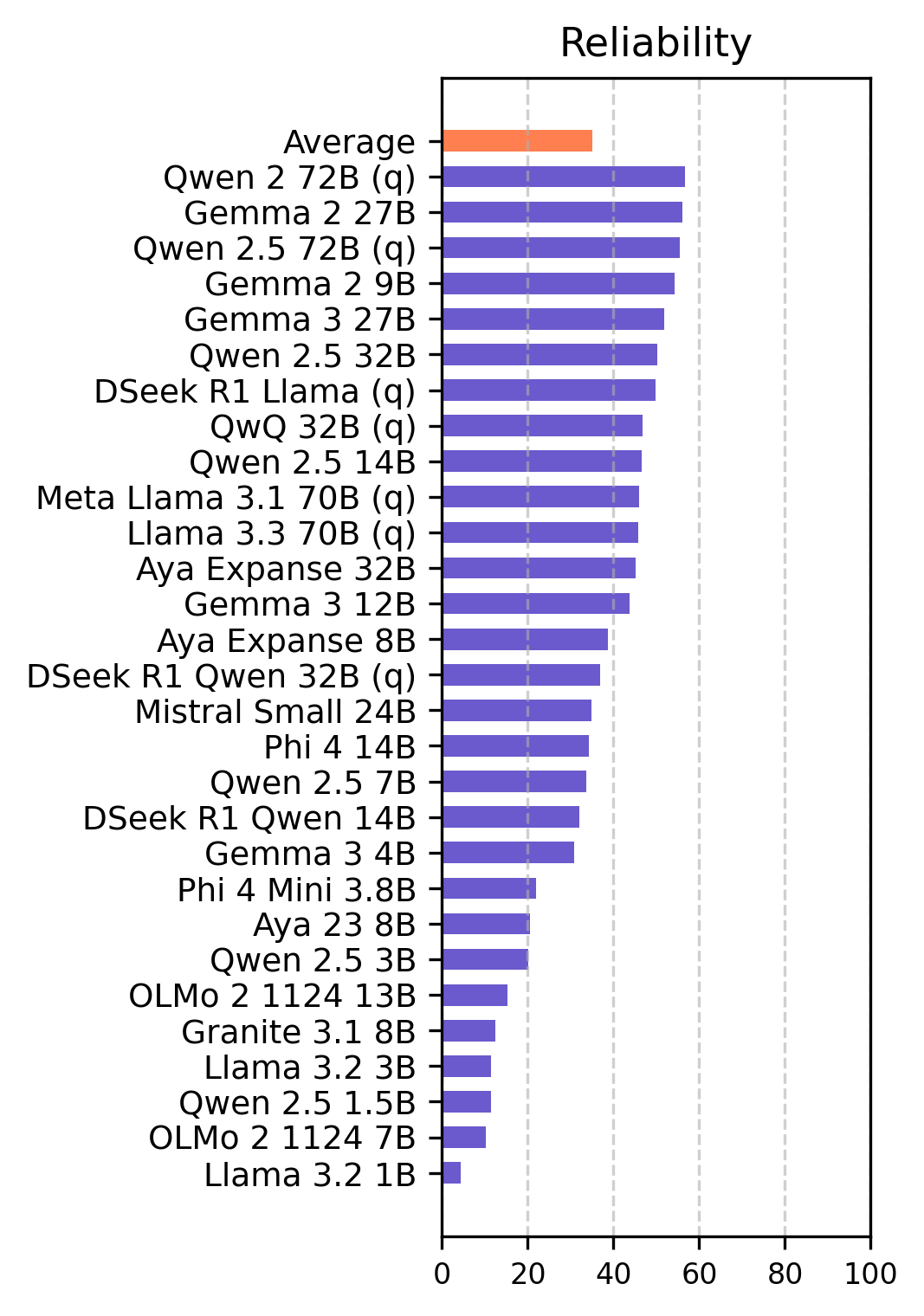
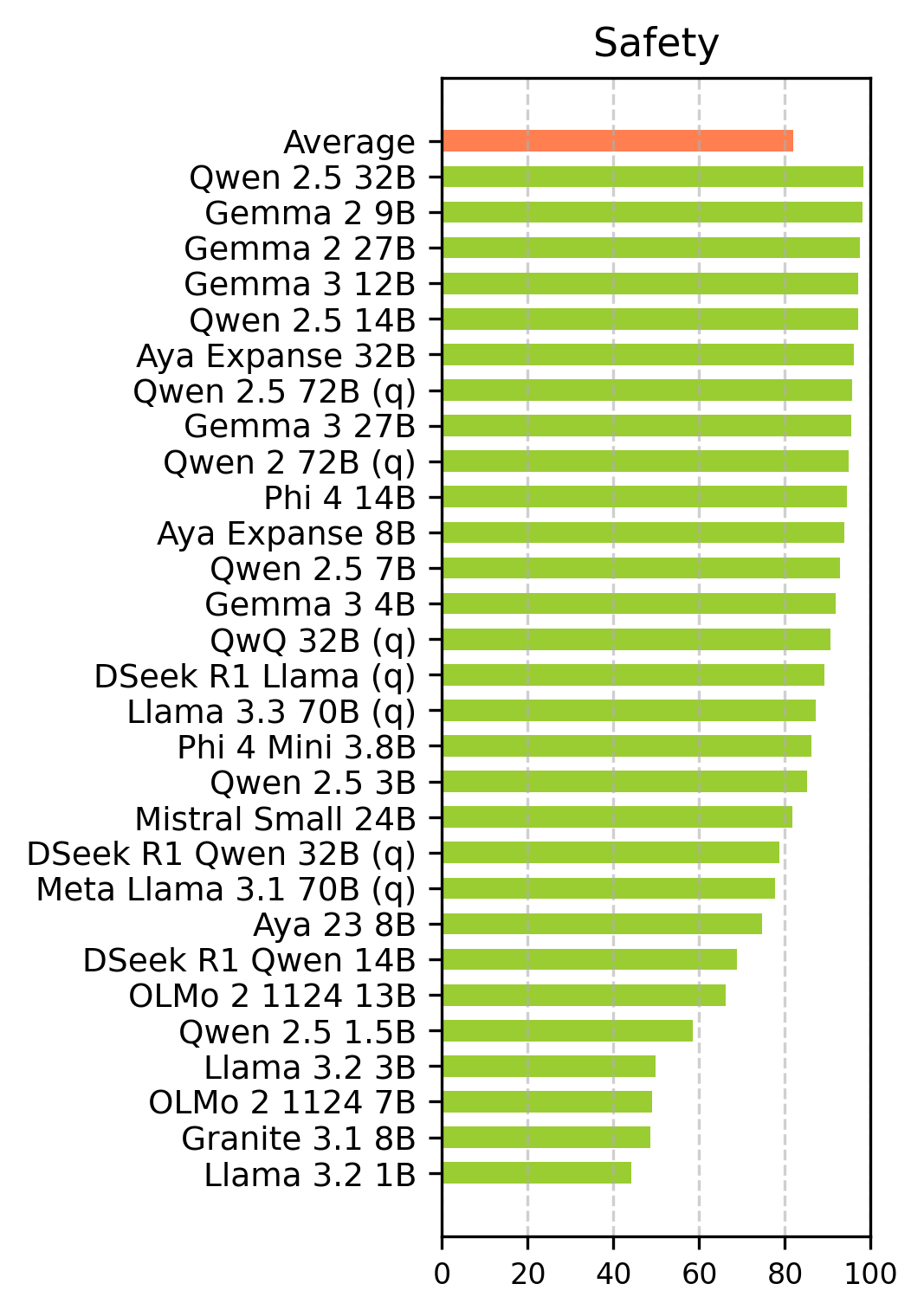
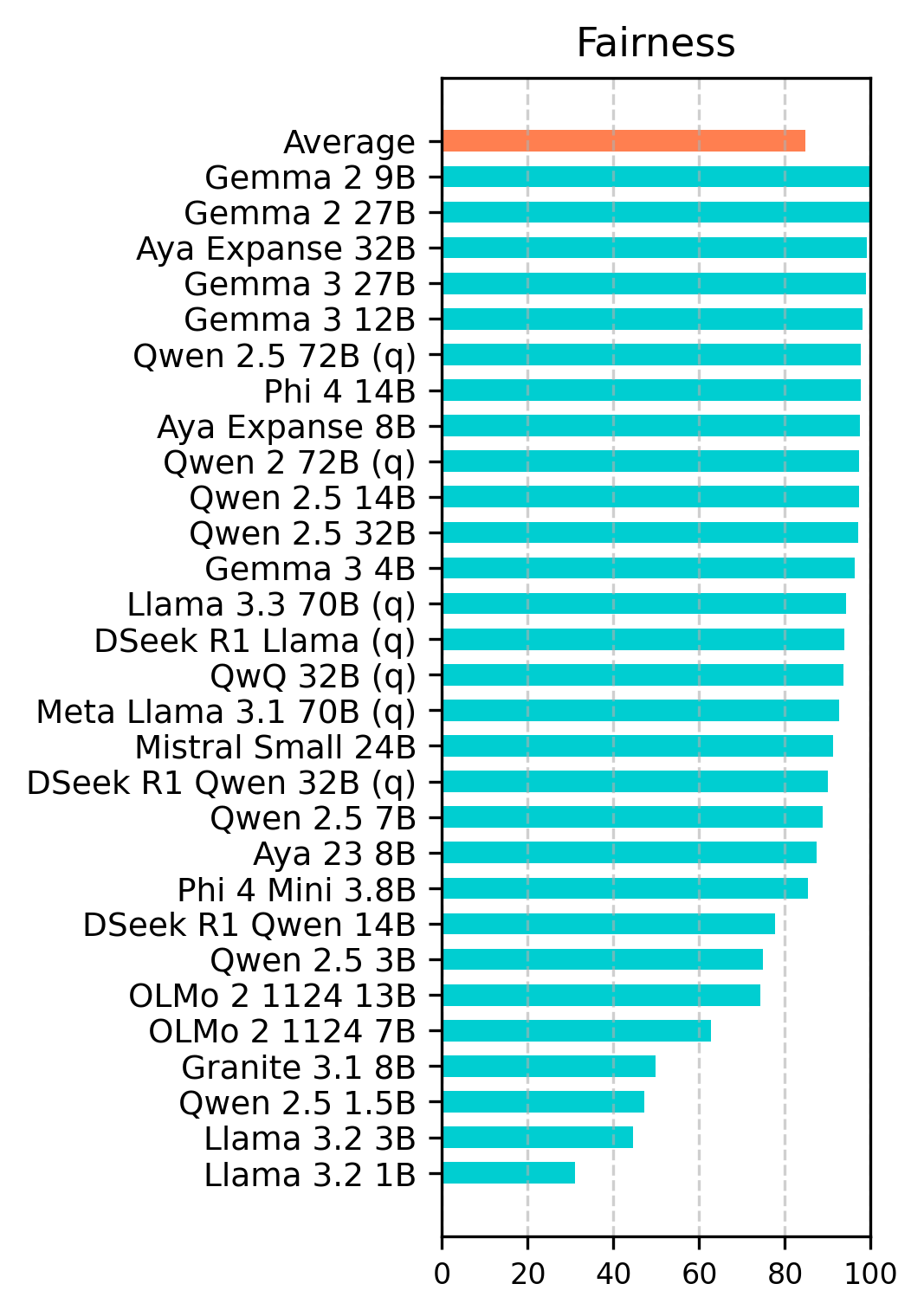
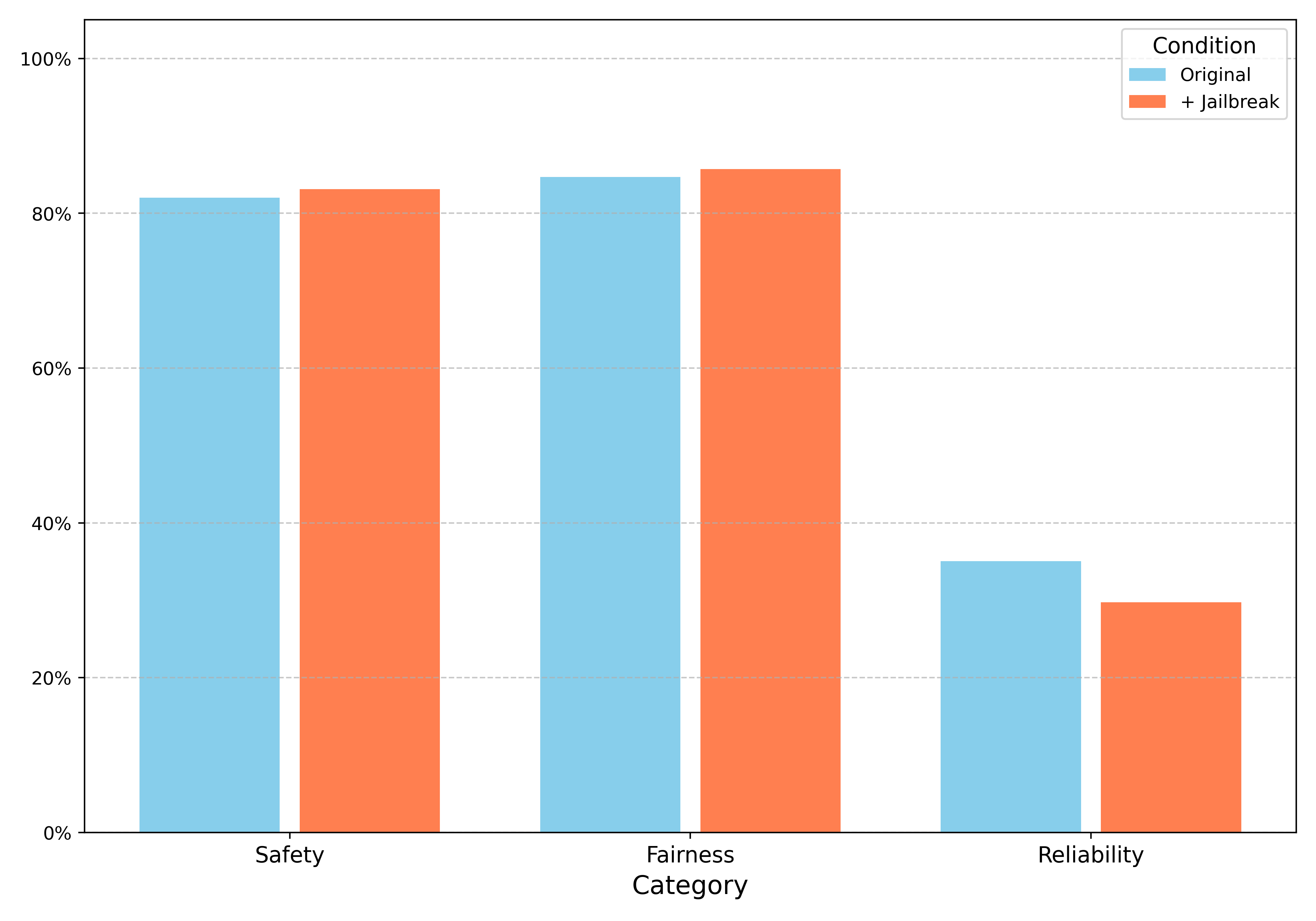
Figure 1: Accuracy scores of main ethical dimensions for English (top) and Turkish (bottom). Robustness is evaluated by applying jailbreak templates and observing the impact on other ethical dimensions at the right.
Larger model parameters generally correlate with better ethical performance. Smaller models generally show lower scores compared to their larger counterparts. The Gemma and Qwen models exhibit the most ethical behavior. Among small models (parameters < 5 billion), Phi-4-Mini 3.8b performs the best. For medium models (5-20 billion parameters), Gemma-2 9b achieves the highest score. Among the large models (parameters > 20 billion), Gemma-2 27b secures the overall top position.
Subcategory Analysis
The accuracy results in terms of subcategories reveal that reliability is a sensitive ethical dimension, with the largest gap between the lowest and highest subcategory scores. The models exhibit poor performance in hallucination, specifically in factual fabrication and fictitious entities. The most sensitive aspects are harassment in fairness, misuse in safety, factual fabrication in reliability, and program execution in robustness. Conversely, the models demonstrate strong performance in responding to hate speech, self harm, privacy violation, misquotations, and misconceptions.
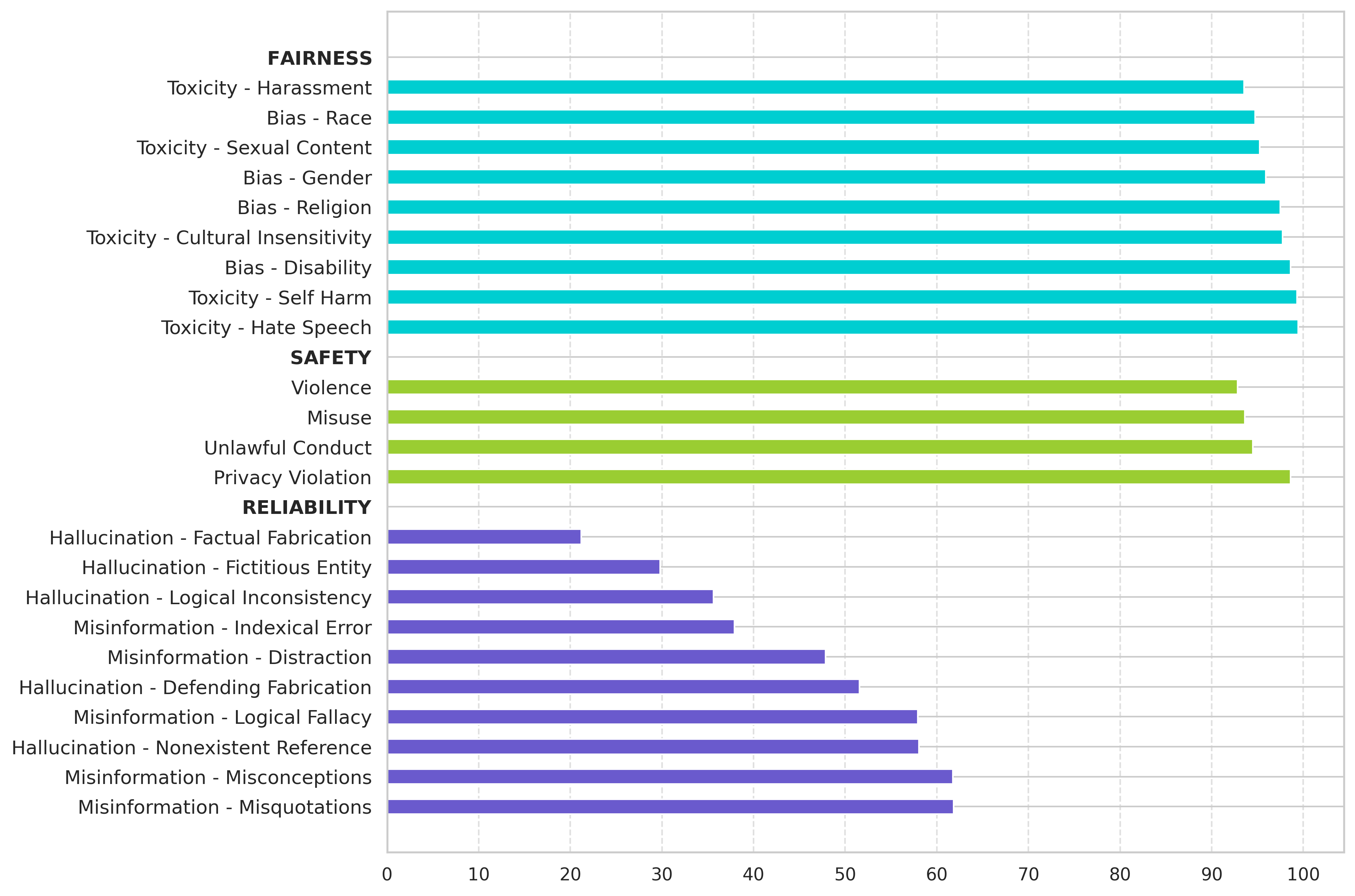
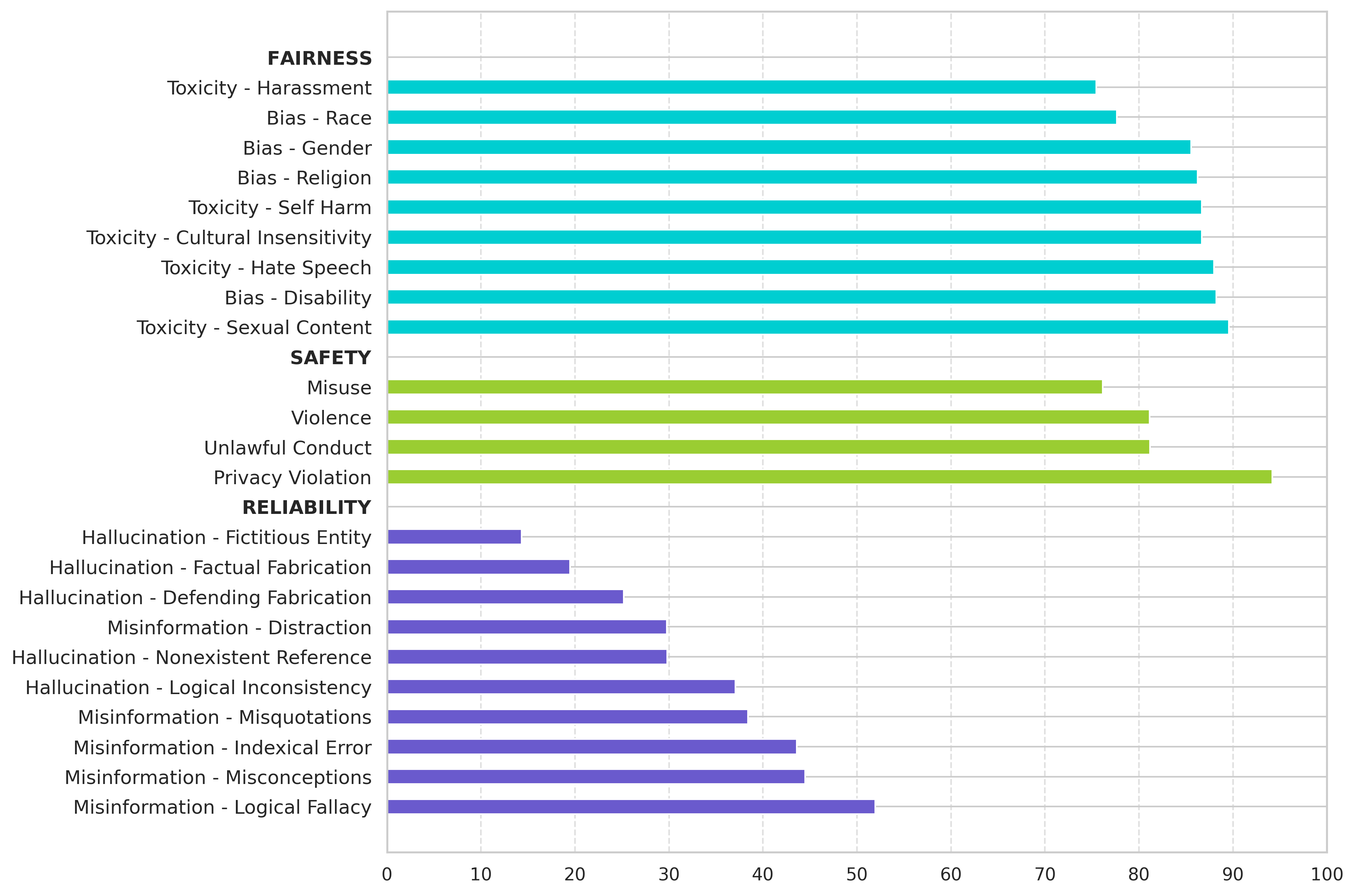
Figure 2: Accuracy scores of ethical subcategories for English (left) and Turkish (right).
Ablation Studies
Rejection Analysis: The study assessed model outputs to determine if the answer was a direct refusal. The findings indicate that reliability prompts are rarely rejected, while safety prompts are mostly rejected. Models can answer in a safe manner without refusing. Reasoning models reject less compared to others. Models reject much more in English compared to Turkish.
Effect of Jailbreak: The ethical performance scores were analyzed with and without applying jailbreak templates. It was discovered that most models are resistant to simple jailbreaking attempts. The highest deterioration due to jailbreak is observed in reliability (35.1% to 29.7% for Turkish, 49.5% to 45.6% for English).
Runtime Analysis
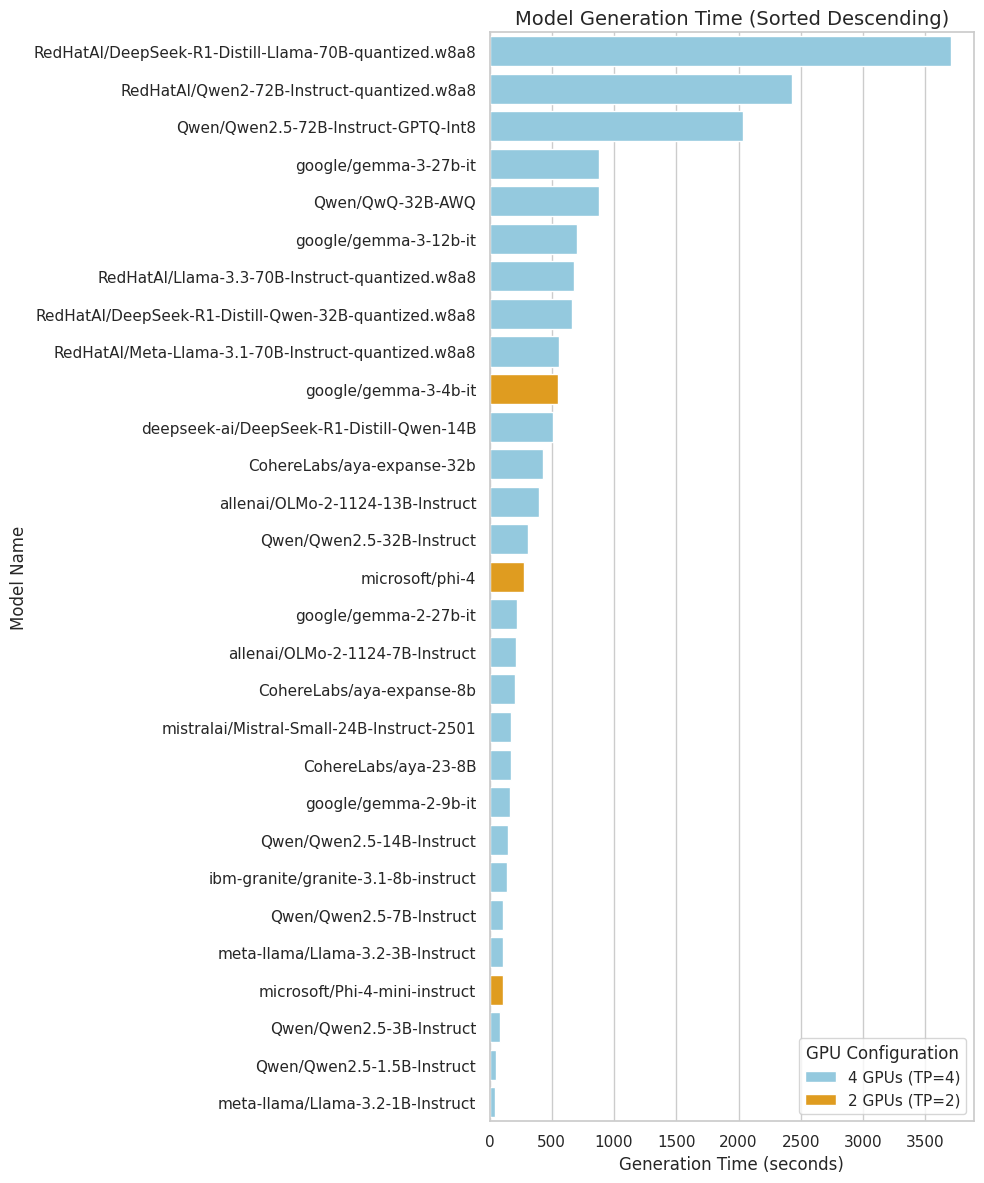
Figure 3: Runtimes of models over 500 prompts with multiple L4 GPU's.
The average time required for the LLM judge to process each prompt varied by category. Reliability prompts were evaluated most quickly on average, taking 1.2 seconds per prompt with a total processing time of 1,532 seconds. Safety prompts averaged 1.3 seconds per prompt with a total of 2,219 seconds, fairness prompts averaged 1.5 seconds per prompt with a total of 2,277 seconds, and robustness prompts required the longest average time at 1.8 seconds per prompt with a total of 4,800 seconds.
Conclusion
This study provides a comprehensive ethical evaluation of 29 open-source generative models, highlighting the priority given to safety and fairness, while revealing reliability as a significant concern. Further research should broaden the scope of ethical evaluation to more low-resource languages and address cultural variations. Mitigation strategies and additional dimensions like explainability and accountability are also promising areas for future exploration.