- The paper introduces UFT, a unified fine-tuning paradigm that merges supervised and reinforcement methods to overcome overfitting and exponential sample complexity.
- It demonstrates polynomial convergence efficiency on long-horizon reasoning tasks, with empirical validation across benchmarks like Countdown, MATH, and logic puzzles.
- The methodology shows UFT’s adaptability by matching or surpassing traditional methods for various model scales, as evidenced by experiments on Qwen2.5 and Llama.
UFT: Unifying Supervised and Reinforcement Fine-Tuning
The paper "UFT: Unifying Supervised and Reinforcement Fine-Tuning" presents a novel post-training paradigm for LLMs that integrates supervised fine-tuning (SFT) and reinforcement fine-tuning (RFT) within a single framework titled Unified Fine-Tuning (UFT) (2505.16984). This approach aims to address the limitations associated with both SFT, which often leads to overfitting in larger models, and RFT, which can suffer from exponential sample complexity, especially in long-horizon tasks.
Methodology
UFT is designed to optimize the strengths and mitigate the weaknesses of both SFT and RFT. It achieves this by creating a unified training process that effectively combines supervised learning feedback with reinforcement learning's exploration capabilities. The process enables models to better explore solution spaces while still receiving guidance from correct reasoning trajectories, which is especially beneficial for training models on long-horizon reasoning tasks.
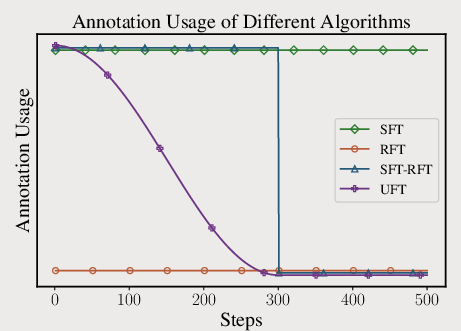
Figure 1: An illustration of SFT, RFT, SFT-RFT, and UFT (top left, top right, middle, bottom) strategies.
UFT also claims to break through RFT's exponential sample complexity bottleneck, showing more polynomially efficient convergence, thus offering a theoretical improvement over conventional RFT approaches.
Theoretical Insights
One of the significant theoretical contributions is showing that UFT can achieve a polynomial sample complexity on reasoning tasks with long horizons. This proves that UFT is capable of exponential speed-ups compared to traditional RFT methods. The theoretical foundations of UFT are built on optimizing a combination of reward optimization and log-likelihood maximization, which allows the model to learn and generalize effectively across both small and large model scales.
Empirical Validation
The experimental results demonstrate UFT's efficacy across various benchmarks, including Countdown, MATH, and logic puzzles. For smaller models, UFT bridged the performance gap between SFT and RFT, delivering superior results when memorization was significant. In contrast, for larger models, UFT achieved performance levels comparable to RFT, indicating its ability to generalize effectively without overfitting.
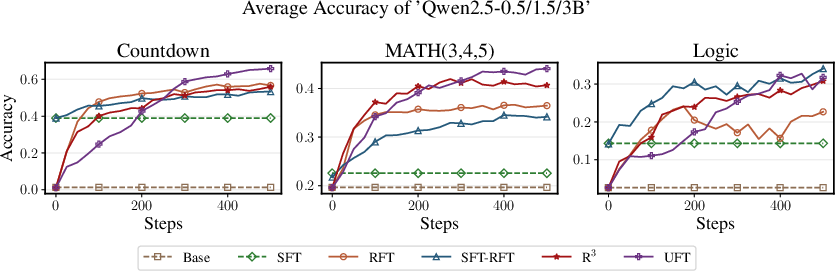
Figure 2: Presentation for different algorithms' accuracy when trained on Countdown.
The experiments involved training models like Qwen2.5 and Llama across various tasks and model scales, consistently showing that UFT outperformed or matched existing methods. This robustness highlights UFT's adaptability to different model sizes and domains.
Conclusion
The introduction of UFT represents a significant step in integrating supervised and reinforcement learning methods for post-training on LLMs. Its theoretical and empirical advancements suggest potential efficiency and performance gains, especially in tasks requiring extensive reasoning and generalization. While the current study leverages human-annotated solutions and focuses on specific reinforcement algorithms, further research may explore the integration of more advanced fine-tuning techniques and reinforcement learning strategies. The evidence indicates that UFT provides an advantageous compromise, improving sample efficiency while accelerating learning convergence, which could facilitate substantial advancements in LLM performance across varied reasoning tasks. Future work may also explore aligning training methodologies with emerging trends in LLM pretraining to further leverage prior knowledge and enhance reasoning capabilities.