- The paper introduces SeNaTra, a vision transformer backbone that natively produces segmentation masks via a content-aware spatial grouping layer.
- It replaces uniform downsampling with a differentiable clustering process, enabling hierarchical and boundary-preserving segmentation without dedicated decoder heads.
- Experimental results demonstrate improved zero-shot segmentation and data efficiency on benchmarks compared to larger, pre-trained models.
This paper introduces a novel vision backbone architecture, the Native Segmentation Vision Transformer (SeNaTra), designed to produce hierarchical image segmentations directly within the backbone, eliminating the need for dedicated segmentation heads. The core innovation is a content-aware spatial grouping layer that replaces traditional uniform downsampling operations with a learned dynamic assignment of visual tokens to semantically coherent groups. This approach enables the emergence of strong segmentation masks from the backbone itself, leading to improved zero-shot segmentation and efficient downstream segmentation tasks.
Methodology: Spatial Grouping and Native Segmentation
The SeNaTra architecture follows the standard structure of modern hierarchical vision backbones, comprising four stages that progressively reduce spatial resolution while increasing channel dimensions. The key component is the spatial grouping layer, which replaces uniform downsampling with a learned, dynamic assignment of visual tokens to semantically coherent groups.
The spatial grouping layer operates as a differentiable clustering process, inspired by K-means, where output tokens act as centroids, and input tokens are iteratively assigned to them. The process involves computing a soft assignment matrix using a cross-attention-like operation and renormalizing this matrix to update the output tokens with a weighted mean over input tokens. To ensure scalability, the grouping layer employs local grouping with restricted context windows in early stages, enabling linear scaling with input resolution, while dense grouping is used only in the final stage to produce whole-image segmentation masks efficiently.
The hierarchical structure and successive grouping operations result in a native segmentation capability, where a multi-scale hierarchy of segmentation masks emerges from the backbone's inherent region-aware representation. By forwarding an image through the model, the combined output of all grouping layers yields sets of matrices that define a mapping from input pixels to final tokens, which can be interpreted as a Markov chain. This probabilistic interpretation enables the model to decompose an image into segments hierarchically, with the final stage allowing tokens to encode segmentation masks spanning the entire image.
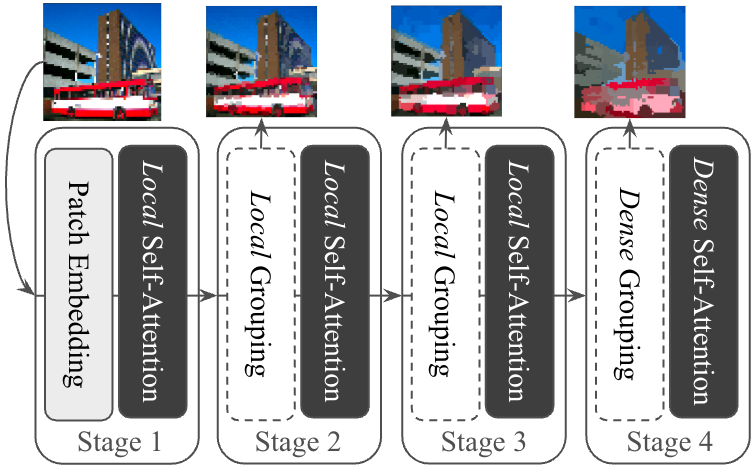
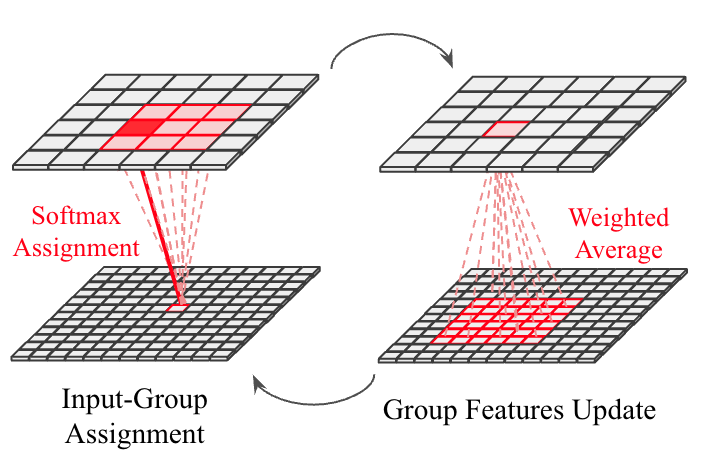
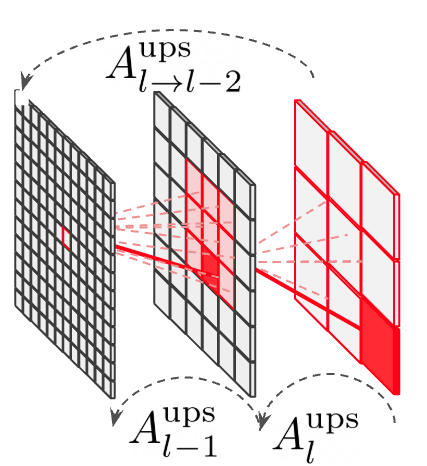
Figure 1: Overall model design, showcasing the hierarchical architecture with content-aware grouping layers and the core operations of the Spatial Grouping Layer.
Key Findings and Experimental Results
The study validates the native segmentation capability of SeNaTra on zero-shot segmentation tasks across established benchmarks, demonstrating significant outperformance compared to prior art, including models trained on an order of magnitude larger datasets. The authors suggest that the architecture is data-efficient, thanks to the grouping layer design. When trained with explicit mask supervision for semantic and panoptic segmentation on ADE20k and COCO-panoptic, the method outperforms several strong baselines without any dedicated segmentation heads, with a significantly reduced parameter and FLOP count. Furthermore, when used in conjunction with such heads, SeNaTra consistently improves the performance of top-performing backbones.

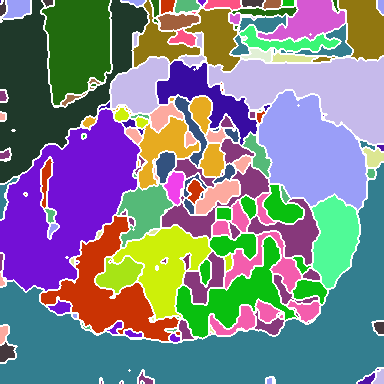

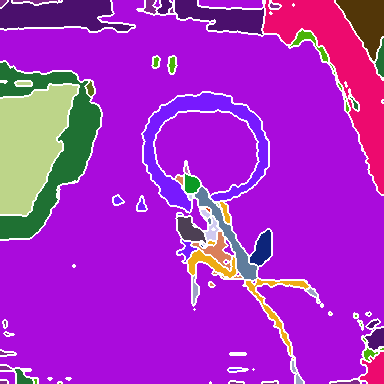
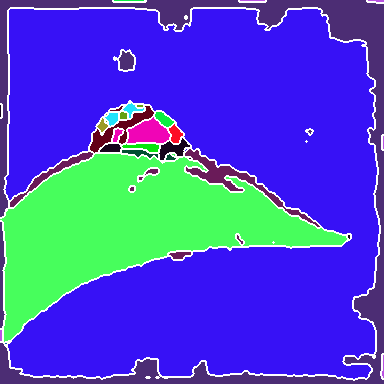
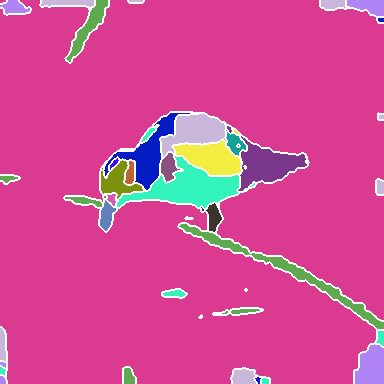
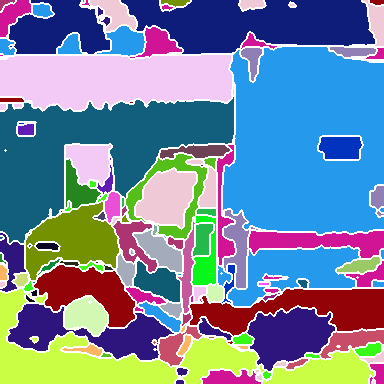
Figure 2: Visualization of group decompositions across each backbone stage after ImageNet pre-training, illustrating the emergence of super-pixel-like structures and semantically coherent regions.
The experiments involve training SeNaTra on ImageNet-1k and ImageNet-22k, demonstrating that the network produces a hierarchy of boundary-preserving super-pixel-like groups, combined in the last, dense grouping layer into meaningful semantic regions, without any form of supervision on intermediate group assignments. The models are also evaluated in zero-shot semantic segmentation, where SeNaTra outperforms specialized state-of-the-art methods across most benchmarks, including models leveraging CLIP's large-scale pre-training on a much larger dataset. When trained with mask supervision, SeNaTra yields substantial improvements over both standard and grouping-based backbones using well-established segmentation heads and consistently improves performance across variants when using a Mask2Former head.
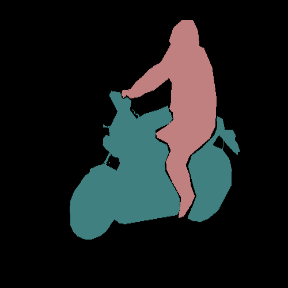


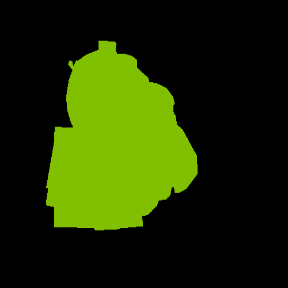



Figure 3: Qualitative zero-shot segmentation results on Pascal VOC validation images, showing hierarchical final decompositions and their predicted semantic masks.
Implications and Future Directions
The SeNaTra architecture presents a streamlined native segmentation network that excels at zero-shot segmentation, trained without any pixel/mask supervision, as well as on standard semantic/panoptic segmentation benchmarks. This suggests a shift towards models where segmentation is inherently encoded in the model's internal representations, rather than delegated to specialized decoder modules. Future developments could explore object-oriented pre-training schemes, optimize the grouping layer implementation for further efficiency gains, and investigate the potential of applying SeNaTra to other vision tasks beyond segmentation.
Conclusion
This work introduces a novel architecture suited for segmentation tasks centered around a spatial grouping layer. This design offers methodological advantages over prior art, being fully differentiable with strong inductive bias and scalable to large input resolutions. Through empirical results, the emergence of meaningful segments without explicit mask supervision and a streamlined paradigm for downstream segmentation were demonstrated. This shows that segmentation can be inherently encoded in a model's internal representations rather than delegated to specialized decoder modules, opening new directions in segmentation-centric backbone architectures.